-
-

Logo
-
Log-in screen
-
Library with no books
-
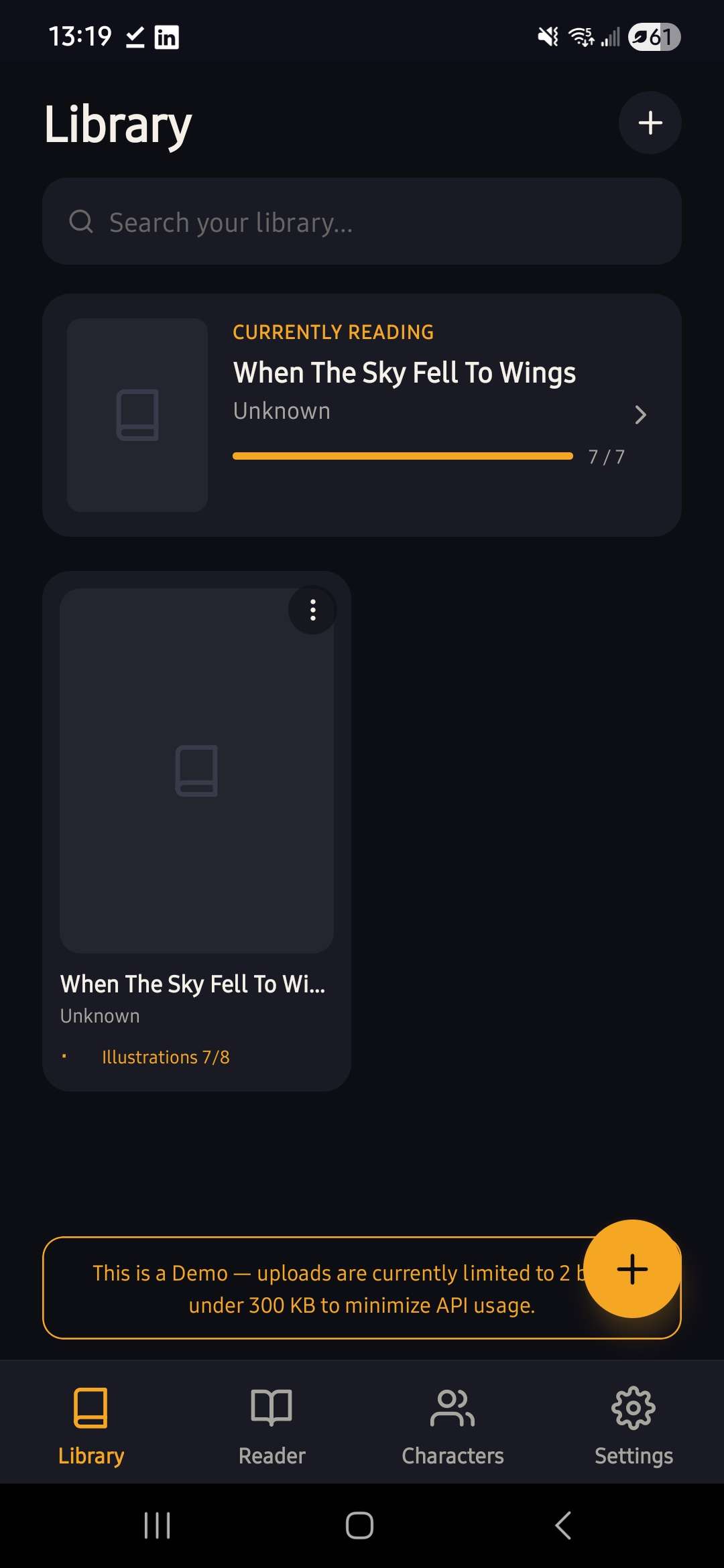
Library with book
-
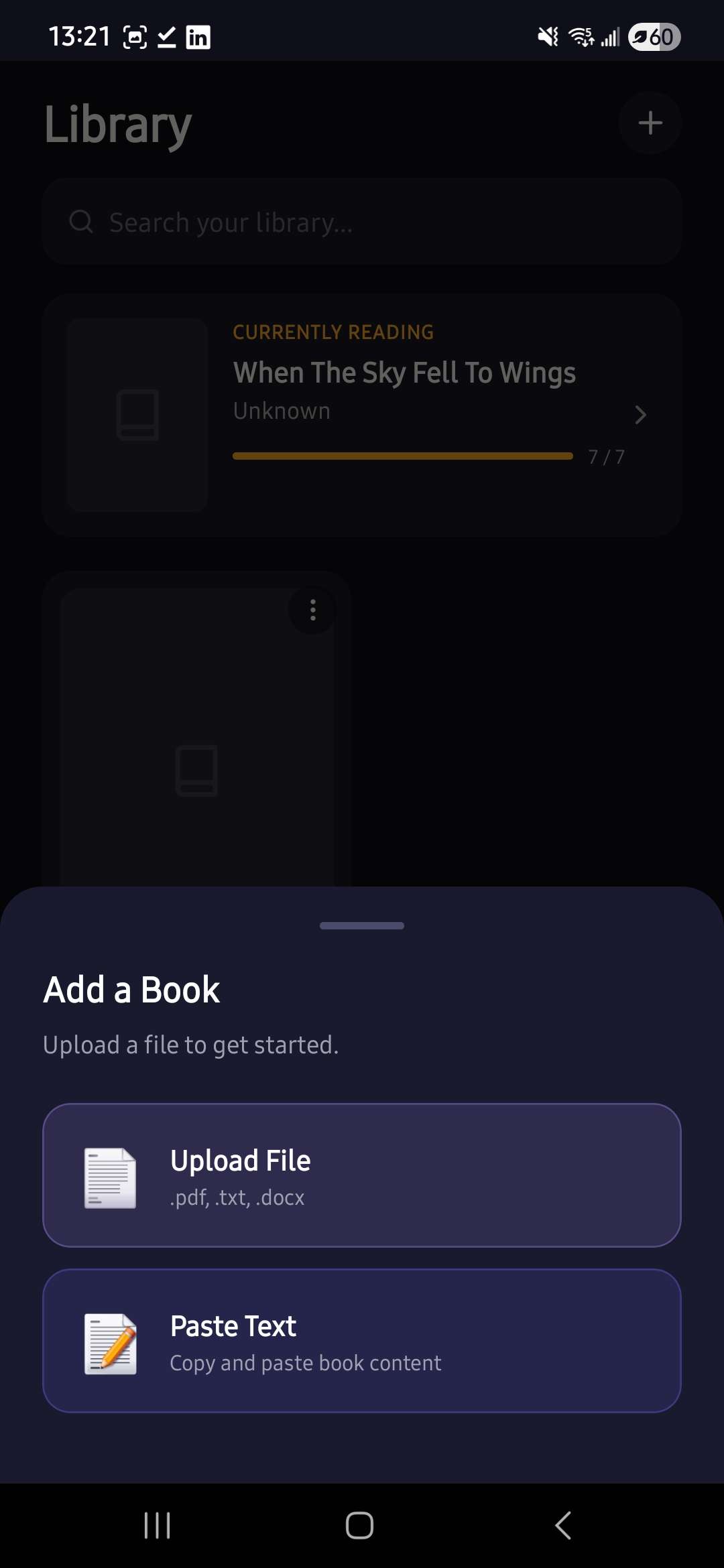
Upload pop up
-
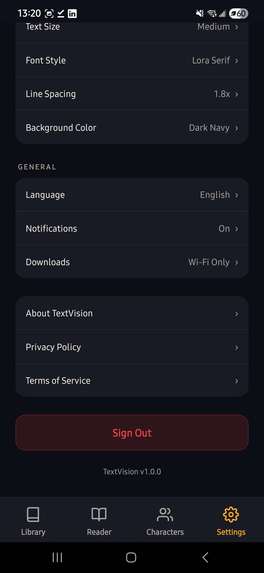
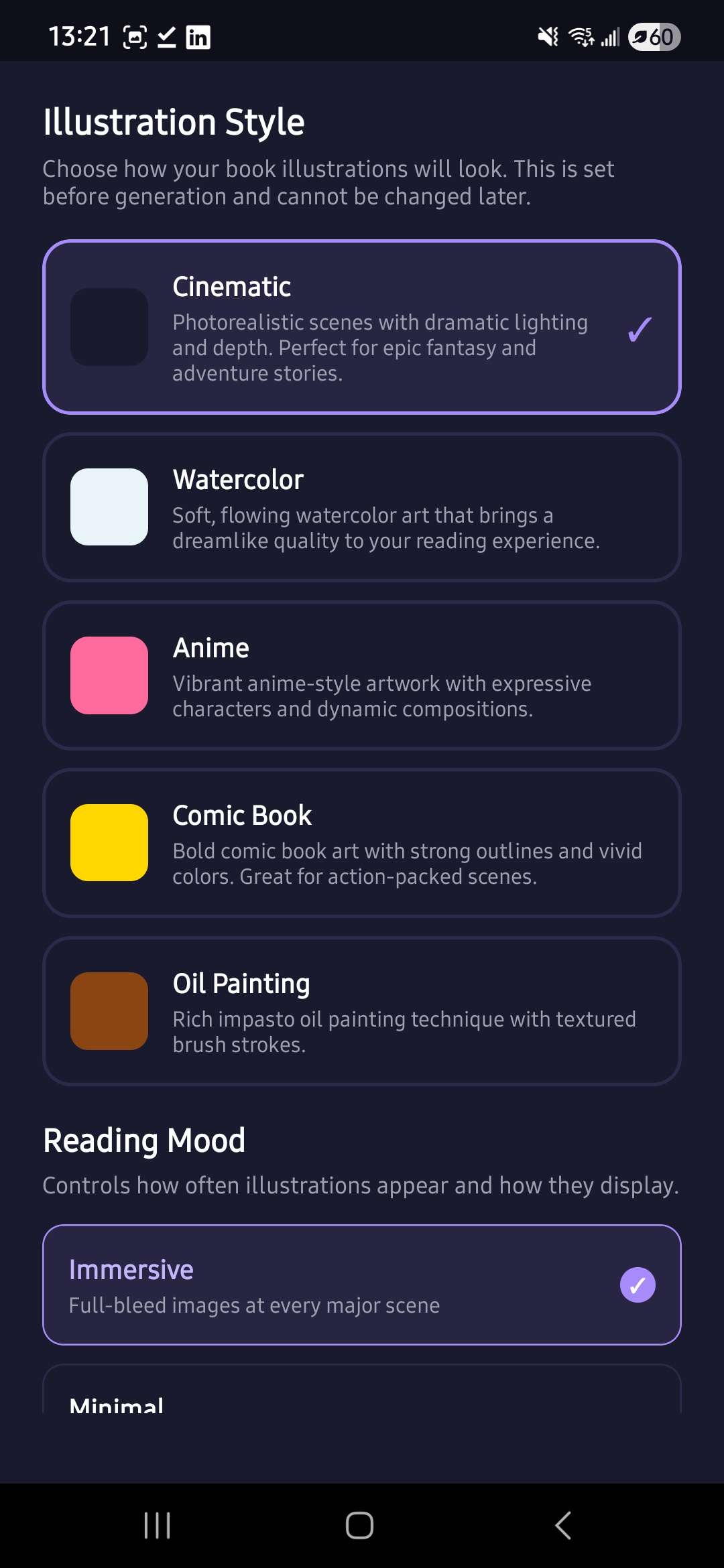
Settings screen
-
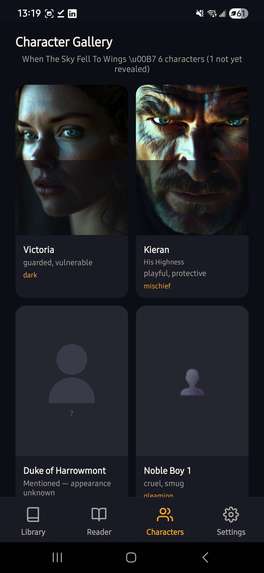
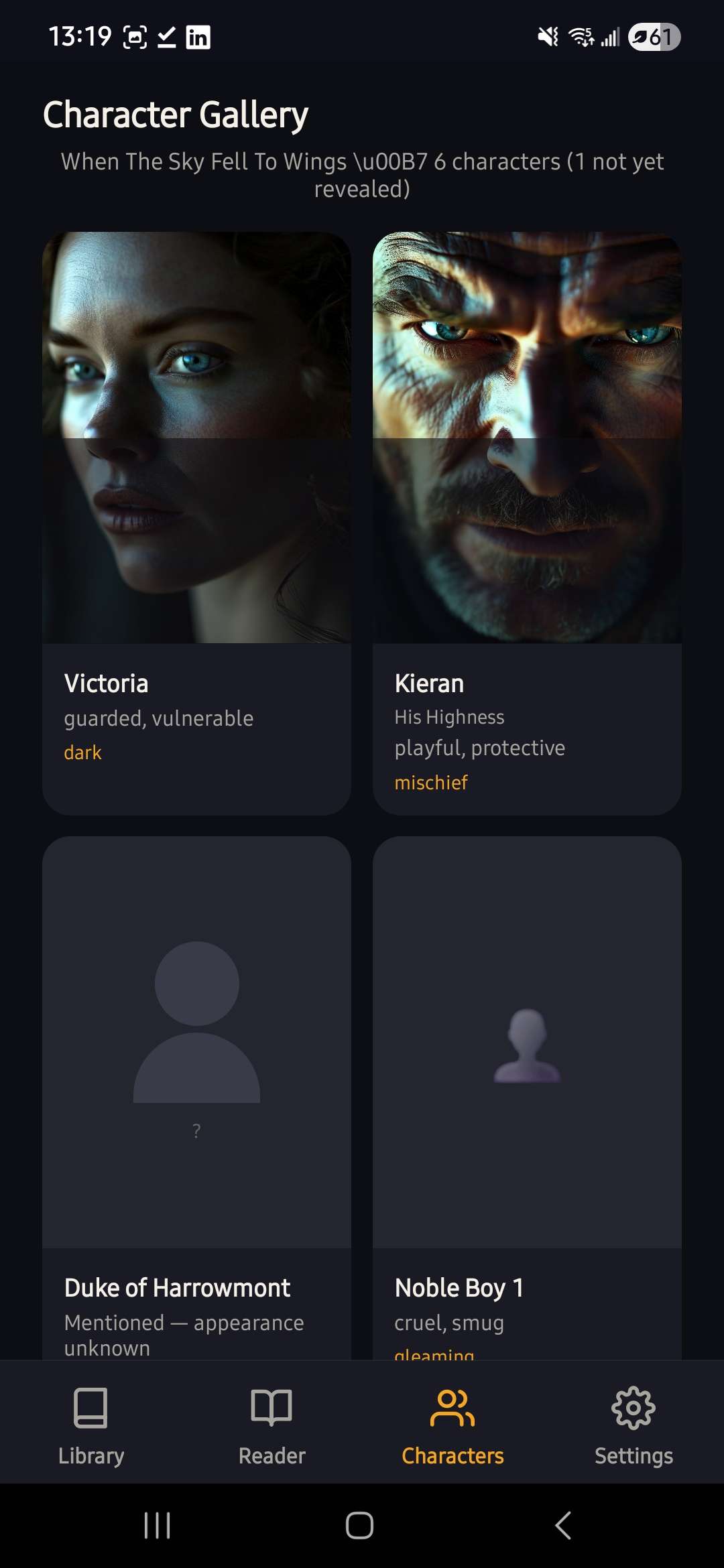
Characters Screen
-
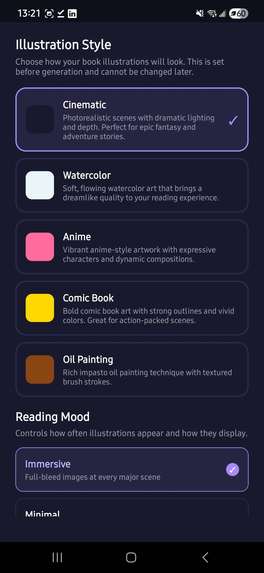
Upload Selection
-

X-ray pop up
-

Reading Screen 2
-

Reading Screen 1




Vividus (TextVision)
An AI-powered mobile app that transforms books into illustrated reading experiences — automatically generating cinematic scene images, character portraits, and a living world bible as you read.
Inspiration
As someone with ADHD I've always been a slow reader. Not because I couldn't understand the words but because I struggled to see the story. While other people talked about getting lost in books, I was getting lost in sentences, re-reading the same paragraph over and over trying to build a picture that just wouldn't come. Reading felt like work when it was supposed to feel like an adventure. That frustration stuck with me for years. And eventually, it turned into a question I couldn't shake: What if the story could just come alive in front of you? That question became Vividus (TextVision).
What it does
At the heart of Vividus is something I call the World Bible and it's the feature I'm most excited about. Behind the scenes, Nova Multimodal Embedding and a retrieval-augmented system tracks every character, location, and aesthetic detail discovered in the book. When Nova Canvas generates illustrations later in the story, it references this memory so visuals remain consistent from beginning to end. When you open a book, Vividus uses Amazon Nova 2 Lite to read through the text and extract every character, location, and aesthetic detail. It builds a persistent visual profile for the entire book. If your protagonist has red hair and a scar on her left cheek in chapter 1, she still has them in chapter 10. If the story is set in a crumbling medieval fortress, that color palette, that atmosphere, carries through every single image. No other reading tool does this and consistency is exactly what makes immersion possible.
From there, a Smart Trigger Point engine using Amazon Nova 2 Lite analyzes the text to find only the moments worth illustrating: dramatic reveals, emotional peaks, new characters stepping into the scene, breathtaking new locations. It doesn't generate an image for every paragraph.
Vividus ingests any book (PDF), automatically:
- Extracts a World Bible — characters, locations, themes, and relationships powered by Amazon Nova 2 Lite
- Detects trigger points — key narrative moments across every page that deserve illustration
- Generates scene illustrations — cinematic AI images via Amazon Nova Canvas, placed inline at exactly the right paragraph
- Creates character portraits — reference images for each character, used to ensure visual consistency across all generated scenes
- Reveals characters progressively — the Characters tab reflects only who you've met so far, respecting spoilers
- Streams updates in real time — a WebSocket connection pushes new images to your device the moment they're ready
How we built it
TextVision was developed in four phases. First, we built the core foundation, including user authentication, book uploads, and the processing pipeline. Next, we added the AI layer to analyze stories, detect key moments, and generate illustrations. In the third phase, we enabled real-time delivery so images appear for readers as they are created. Finally, we refined the reading experience with features like inline illustrations, character highlighting, and book management, along with building the demo version. The mobile app was built using React Native with AWS services for authentication and backend support.
Backend (AWS):
- Amazon Cognito — user authentication
- API Gateway (REST + WebSocket) — authenticated endpoints and real-time push
- AWS Step Functions — orchestrates the 6-stage ingestion pipeline: format detection → text extraction → structure normalization (For PDF format) → world bible extraction → trigger point detection → character portraits → scene illustrations
- Amazon Bedrock — Nova 2 Lite for text understanding and extraction; Nova Canvas for image generation; Nova Multimodal Embeddings for semantic character/location retrieval
- Amazon DynamoDB — keep track of books, world bibles, trigger points, generated images, user connections
- Amazon S3 + CloudFront — book storage and global CDN delivery of generated images
- Amazon SQS — decouples image generation from WebSocket delivery
- AWS CDK — entire infrastructure as code, deployable with a single command
Challenges we ran into
Nova Canvas 1024-character prompt limit
- Our assembled prompts which includes: character descriptions + scene context + style modifiers, regularly exceeded the limit. This leads us to building a layer-dropping strategy that preserves complete semantic layers rather than hard-truncating mid-sentence.
Anti-spoiler character system
- One of the trickiest problems we faced was preventing spoilers. Our pipeline requires the AI to read ahead in the book to build a consistent “world model,” which means it can see information the reader hasn’t reached yet. That creates a real risk of revealing major plot details too early. To solve this, we had to track first_mentioned and first_described page numbers per character, with three visibility states (hidden, mentioned, described), while maintaining backward compatibility with legacy records.
Accomplishments that we're proud of
- A fully end-to-end pipeline that takes a raw PDF and delivers a fully illustrated book to a mobile reader — automatically, with no human intervention
- Character portrait generation that feeds into scene illustrations for visual consistency across a whole book
- A real-time reading experience where images appear inline as you read
- A complete AWS serverless architecture deployed entirely through CDK
What we learned
- Amazon Nova 2 Lite is remarkably capable at structured extraction, especially in our use case of world bible generation, trigger point detection, and chapter analysis all work with well-crafted prompts
- Nova Canvas produces high-quality cinematic images but requires careful prompt engineering; character descriptions must lead the prompt (not trail it) for reliable character depiction
- Building for real readers means thinking about spoilers, reading pace, and the emotional tone of a scene. AI generation without those constraints produces technically correct but narratively jarring results
- Serverless Step Functions pipelines are powerful but require careful state design — every branch needs an explicit
.next()and every catch needs a named fallback state
What's next for Vividus (TextVision)
- Agentic image validation — a micro-agent loop that checks generated images against the world bible description and regenerates if characters look wrong or scene details don't match
- Audio narration — Amazon Polly integration to read pages aloud with illustrations synced to narration position
- Social reading — shared highlights, annotations, and the ability to see how other readers' illustrations differ from your own
- Author tools — let authors upload their own reference art to guide the visual style of their book's illustrations
- iOS release — currently Android-only; iOS via TestFlight is next
Built With
- amazon-web-services
- bedrock
- cdk
- cloudfront
- cognito
- dynamodb
- javascript
- python
- rest
- s3
- typescript
- websocket


Log in or sign up for Devpost to join the conversation.