-
-
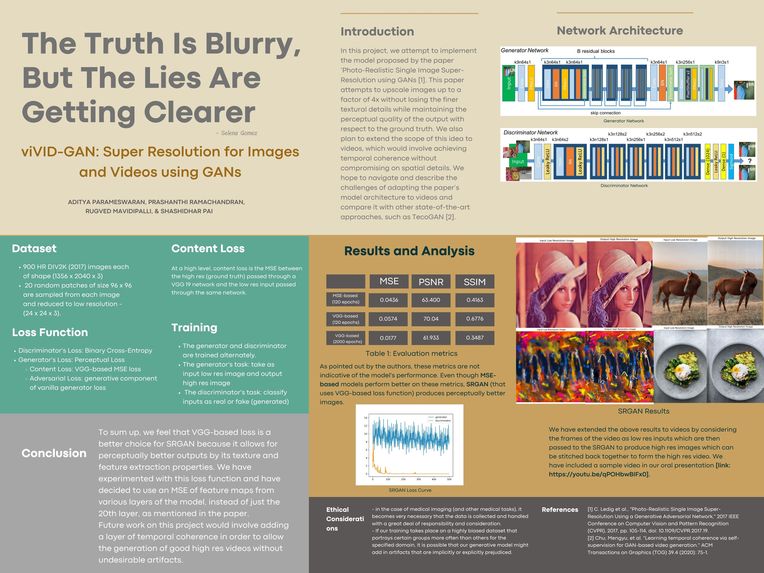
viVID-GAN: Final Poster
-
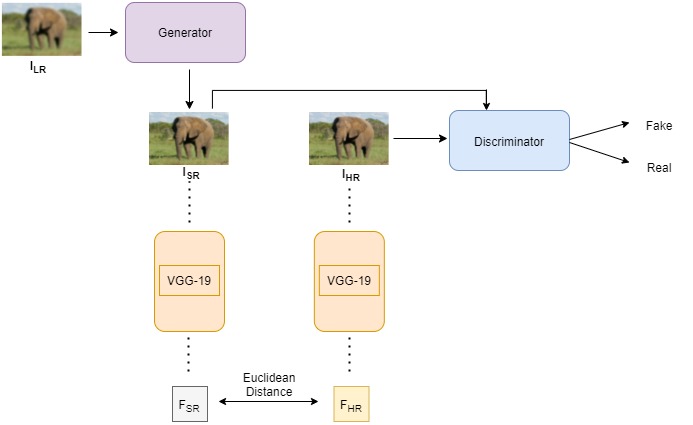
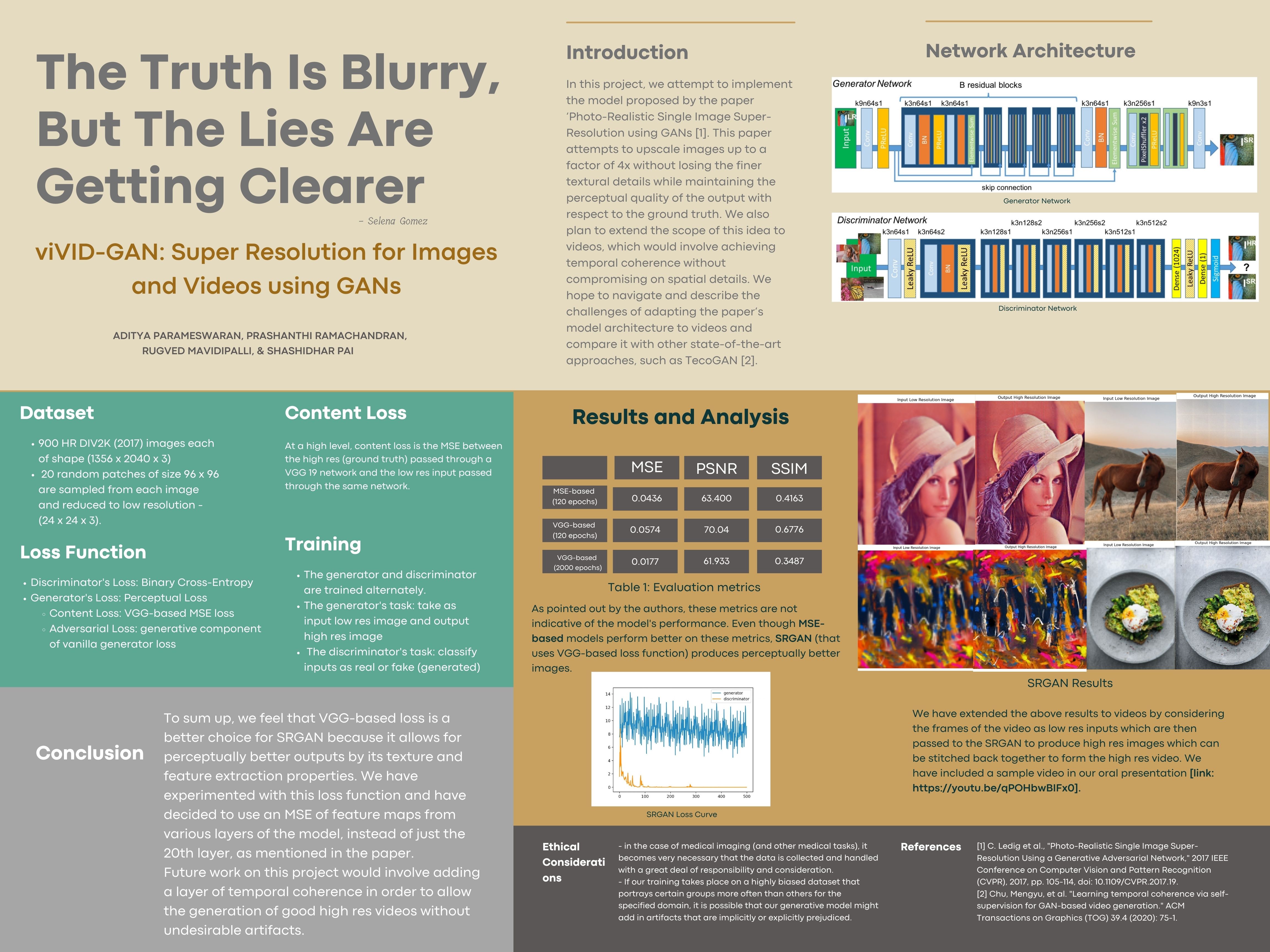
Figure 1: SRGAN Model Training
-

Experimental Results
-

Tensorflow Downscaling Bias
-

Issues with MSE
-
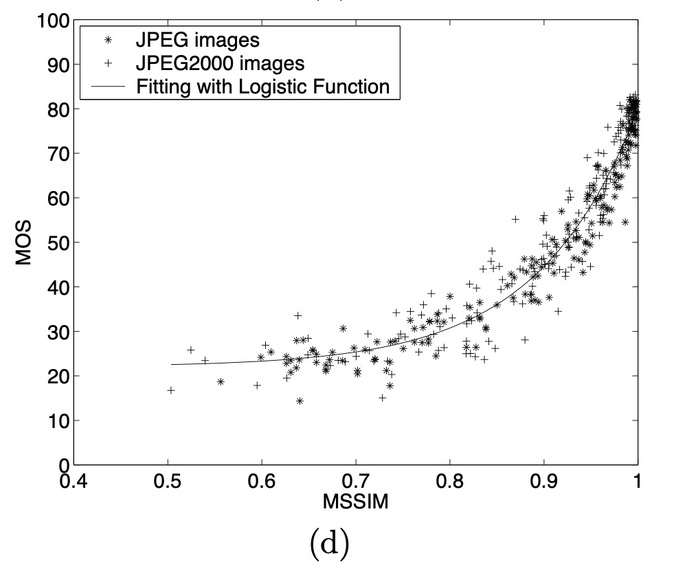
Relation between MOS and SSIM
-
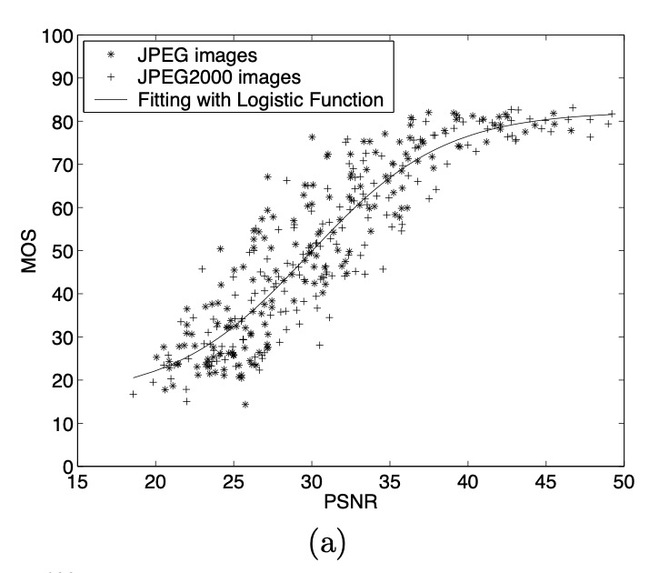
Relation between PSNR and SSIM
-

Low Resolution Image [1]
-

High Resolution Image [1]
-

Low Resolution Image [2]
-

High Resolution Image [2]
-

Low Resolution Image [3]
-

High Resolution Image [3]
-

Low Resolution Image [4]
-

High Resolution Image [4]
-

Low Resolution Image [5]
-

High Resolution Image [5]













viVID-GAN: Super Resolution for Images and Videos using GANs
GitHub Link to implementation: https://github.com/prashanthi-r/viVID
Oral Presentation: https://youtu.be/qPOHbwBIFx0
Using viVID-GAN for super-res video generation: https://drive.google.com/file/d/1X6LxbiM8xAJIHQCdeOOdaGoPZpjyJ_hy/view?usp=sharing
Check-in 2 (Reflection Post): https://docs.google.com/document/d/1Zu8s1MOnMj9okmQmjn1zE4pKFdxr_qDNcaMswG8F5sA/edit?usp=sharing
Group Members
Aditya Parameswaran, Prashanthi Ramachandran, Rugved Mavidipalli, Shashidhar Pai
Introduction
In this project, we have implemented the architecture proposed by the paper ‘Photo-Realistic Single Image Super-Resolution using GANs’ ^1. This paper attempts to upscale images up to a factor of 4x without losing the finer textural details while maintaining the perceptual quality of the output with respect to the ground truth. We extended the scope of this idea to videos, which involves achieving temporal coherence without compromising on spatial details. We have navigated and described the challenges of adapting the paper’s model architecture to videos and compare it with other state-of-the-art approaches, such as TecoGAN ^2. Further, we demonstrate that the model generalizes well on out-of-domain inputs through various biased and unbiased inputs. Finally, we examine the benefits of using a domain-diverse dataset and understand the viability of this approach for better generalization.
paper: "Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network"
Datasets:
DIV2K Dataset: https://data.vision.ee.ethz.ch/cvl/DIV2K/
Training:
To train the model the paper has used 350,000 images from the ImageNet database^3. These images were selected at random in parallel making sure that the same images are not part of the testing/validation set. As mentioned above, we have used the same number of images and methodologies.
Testing/Validation:
For our purposes, we have fed open-source images from the internet to the model and have evaluated them based on our visual perception. Some of the results have been illustrated in the linked images.
Preprocessing:
The images in DIV2K are high-resolution images without any blur. First, as the paper describes we have used a Gaussian filter on the high-resolution images. We then downsampled the images by the scale of 4 and then randomly sampled 20 patches of size 96 x 96 x 3 from the high res images. Once the patches were sampled, we downscaled them to 24 x 24 x 3 and then fed them to our model. The same was done for the testing/validation set as well. During inference, once the patches of images are passed through the model to generate high res patches, we simply stitch the outputs together to obtain a full high res image.
Related Work
Deep learning approaches towards super-resolution have been teeming. Few related works in the space are the following:
- EDSR: Enhanced Deep Residual Networks for Single Image Super-Resolution ^4
- WDSR: Wide Activation for Efficient and Accurate Image Super-Resolution ^5
- SRCNN: Image Super-Resolution Using Deep Convolutional Networks ^6
- ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks ^7
ESRGAN is closely related to SRGAN and in fact, based on SRGAN. It improves upon SRGAN by analyzing the issues that are prevalent in certain cases of SRGAN. One such issue is that SRGAN does not fully enhance certain features of the image, leaving residual blur. This can be observed in the image below:
In the above image, it can be seen that certain parts of the baboon still have some left-over residual blur in the image. Whereas ESRGAN performs better with this issue. ESRGAN explores the possible architectural changes that can be made to SRGAN to solve the above-described issue. The proposed solution to this problem is to add a Residual-in-Residual Dense Block without batch normalization. The other update made is to let the discriminator train on the features before going into the activation layer. This approach improved the brightness, consistency, and texture of the output images.
Methodology
Network Architecture
The model used for the SRGAN implementation consists of two networks, the generator, and the discriminator, trained in an alternating fashion. Since we are dealing with an image generation task, we make use of convolution layers coupled with a sub-pixel convolution layer that helps us upscale the image from feature maps generated in the prior step. We also use a ResNet architecture to create deeper networks that don't suffer the vanishing gradient problem while having lesser trainable parameters. The detailed network architecture for both models are listed below:
Generator
Residual Blocks (16 blocks which are stacked together) - Each block consists of the following layers, which ends with an element-wise multiplication of the input and the block output.
- Convolution 2D Layer - 3x3 Kernel - 64 Feature Maps
- Batch Normalization Layer
- Parametric RELU
Subpixel Convolution (2 Blocks) - Each block consists of convolution layers followed by upscaling via pixel shuffling which involves laying out each corresponding pixel of r x r channels in a grid of size r x r over the original image size.
- Convolution 2D Layer - 3x3 Kernel - 256 Feature Maps
- 2 Pixel Reshufflers
- Parametric RELU
Discriminator
Convolution Blocks - This model is a standard image classification model made up of convolution layers that are stacked on top of each other
- Convolution 2D Layer - 3x3 Kernel - (64|128|256|512) Feature Maps
- Batch Normalization Layer
- Leaky RELU
Flatten Layer - We flatten the output of all the convolution blocks to feed to our Dense Layers.
Dense Layers - We finally pass the flattened array to our dense layers that output whether the input image is real or generated.
- Dense Layer - 1024 Neurons
- Leaky RELU
- Dense Layer - 1 Neuron - Sigmoid Activation Function
Training
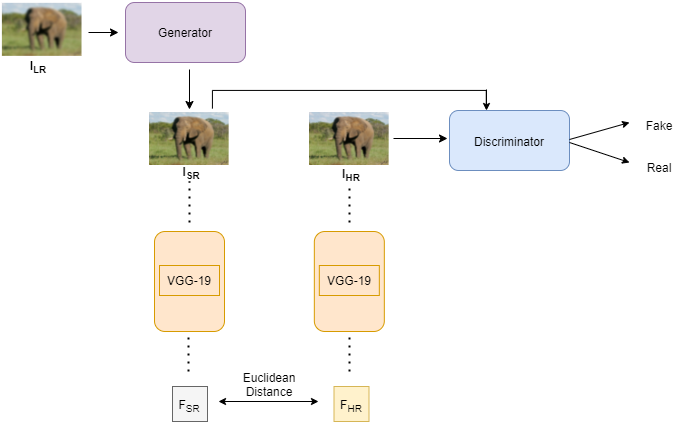
Similar to regular GANs, the architecture of SRGAN consists of two neural networks, namely the generator and the discriminator [Refer Figure 1]. The generator takes as input ILR, which is a low-resolution version of its high-resolution counterpart IHR. The generator’s task is to estimate a super-resolution image, ISR, from ILR. The discriminator’s role is to classify its inputs as real or fake. The training is done by optimizing a combination of the generator’s loss and the discriminator’s loss that is modeled as a min-max game. This adversarial component in the form of the discriminator allows the model to generate images that are from the distribution of the real training images indexed by IiHR for i in {1, 2, …, n}.
This paper introduces a new loss function called ‘perceptual loss’ that is a combination of the generator’s loss and the discriminator’s loss. The generator’s loss is calculated as the Euclidean distance between the feature representations, FSR and FHR, obtained when IHR and G(ILR) (the reconstructed image) are passed through a pre-trained 19-layer VGG network respectively. The discriminator’s loss is computed as the summation of the negative log of the probability that G(ILR) is a ‘natural’ HR image over all the training points. During training we trained the generator separately for 100 epochs without the discriminator, using the MSE loss. After which we trained the generator and discriminator for 2000 Epochs, with random 11 (96 * 96 * 3) crops from the Div2K dataset (images of size: 1356 * 2040 * 3). Our low-resolution images were off size 24 * 24 * 3. The perceptual loss was calculated for the generator and binary cross-entropy for the discriminator. Lastly, one of the biggest changes was using just VGG layer 9 for our content loss instead of layer 20 or averaging three layers [5, 10, 15] which is another thing we tried that showed improved but the biggest improvements were seen using the VGG layer 9. Another important hyperparameter we changed is the beta 1 for our Adam optimizer with a 1e-4 learning rate.
Challenges
Storage issues and dealing with training on such a large dataset (12,800) images.
Computational and time complexity of incorporating the new perceptual loss which includes passing images into the VGG architecture and comparing feature maps.
Designing and implementing a reliable mean opinion score experiment for evaluating the model.
Training this architecture requires heavy compute power so we used Colab Pro to train the model. This led to extremely fast training.
Metrics
paper: "Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network" The paper uses a combination of classic and novel measures to compare images and evaluate models. Below listed are the metrics, loss functions, and evaluation metrics used in the paper to quantify their results. We will work towards implementing the paper best-performing model.
Mean Square Error (MSE)
Defined as the pixel-wise average squared difference between the original image and the processed/reconstructed image. The lower the MSE the better the quality of the compressed, or reconstructed image.
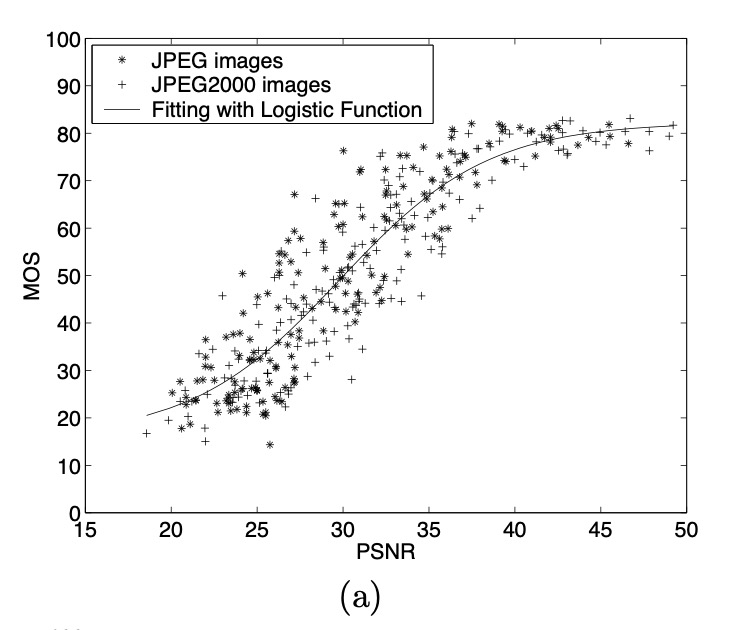
Peak signal-to-noise ratio (PSNR) ^8
Is the ratio between the maximum possible power of a signal(255 for images) and the noise(MSE) which affects the fidelity of its representation. The ratio is used as a quality measurement between the original and a reconstructed image, in our case original high res image vs the output image. The higher the PSNR, the better the quality of the compressed, or reconstructed image.
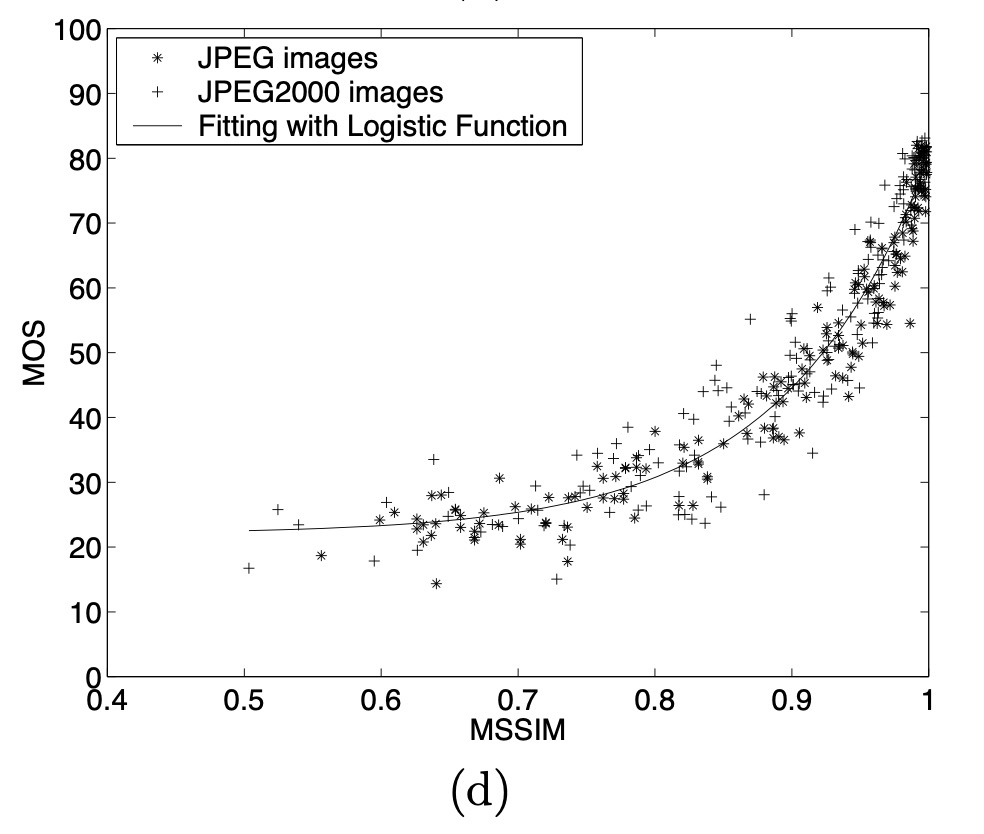
Structural Similarity Index (SSIM) [^9]
The Structural Similarity Index (SSIM) is a perceptual metric that quantifies image quality degradation between the original image and a processed image(in our case reconstructed). Higher the SSIM score, the closer the similarity to the original image. "SSIM actually measures the perceptual difference between two similar images. It cannot judge which of the two is better: that must be inferred from knowing which is the original and which has been subjected to additional processing such as data compression/reconstruction."
Loss Functions:
Pixel-wise loss functions such as MSE struggle to recover the high-frequency details, as by minimizing MSE we eventually end up taking an average across all solutions in the possible solution subspace. This averaging across the solution subspace leads to the output being overly smooth with poor perceptual quality.
The paper thus eliminates the drawbacks of averaging due to minimizing MSE by using a GAN-based network where we replace the MSE based content loss with a content loss that is calculated on the feature maps of the VGG network. This loss is now more invariant to changes in the pixel space and captures a loss more at a perceptual level.
Perceptual Loss Function
This paper improves on the previous implementation detailed in Jhonson et al. and Bruna et al. by designing a novel perceptual loss function calculated as a weighted sum of the content loss and an adversarial loss.
Content Loss:
Is derived from a VGG based MSE loss. It is obtained from the Relu activation layers of the pre-trained VGG model with $\Phi$i,j which indicated the feature map obtained by the j-th convolution (after activation) before the i-th max-pooling layer within the VGG network.
Adversarial Loss:
In addition to the content losses, the authors also add the generative component of the GAN to the perceptual loss [^10], [^11], making the model favor solutions that reside on the manifold of natural images.
Evaluation - Quantifying Success
Performance - Mean Opinion Score (MOS) [^12]
The authors have performed a Mean Opinion Score test to quantify the ability of different approaches to reconstruct perceptually convincing images. The MOS test involved 26 human raters to assign a score from 1 (Bad) to 5 (Excellent), 29328 ratings were obtained, where each rater rated 1128 images. This is used as a metric to compare the performance of different models. Note that due to time constraints, we have evaluated our generated images solely based on the team members' visual perception instead of MOS.
Content Loss comparison
In addition to MOS, the paper also compares multiple content loss metrics like MSE, PSNR, and SSIM across different models. It is seen that pixel-wise loss functions fail to capture the perceptual quality index of images. We also plan to implement these metrics to compare different models.
As pointed out by the authors, these metrics are not indicative of the model's performance. Even though MSE-based models perform better on these metrics, SRGAN (that uses VGG-based loss function) produces perceptually better images.
Ethics
Our training data consists of 350,000 images randomly sampled from the ImageNet dataset. This data has been the go-to standard for most image-based tasks because it is the biggest dataset of its kind. As it consists of images scraped off the internet, it comes with human-like biases about race, gender, weight, and more ^13. Further, since we use pre-trained models (VGG-19) in the calculation of our losses, the biases that have accumulated over many iterations by these large models creep into our task. For instance, a recent paper exposed biases within the TensorFlow implementation of downscaling where an image of a cat is ‘downscaled’ to an image of a dog^14. In his paper, Dr. Ben Green talks about an instance where this takes place where he details projects aimed at deploying game theory and machine learning to predict and prevent the behavior from “adversarial groups”. According to him, this project overlooks fundamental questions like the legitimacy of data provided by the LAPD on gang suppression (a biased dataset), an entity that has a well-documented history of abusing minorities in the name of gang suppression ^15.
In our case, since we put forward a generative task of super-resolution of images, we considered cases that could potentially take the form of what Dr. Ben Green mentions in his paper. For instance, let’s suppose the Super Resolution model was used in surveillance footage restoration to increase the resolution of potential crime scene images/videos. If our training takes place on a highly biased dataset that portrays certain groups more often than others for the specified domain, it is possible that our generative model might add in artifacts that are implicitly or explicitly prejudiced. There are well-documented examples, such as the case of the PULSE algorithm converting a pixelated image of Obama to a high-resolution image of a white man because of racial biases in training data ^16.
While these implicit biases may be harmless for regular tasks, they may have serious implications when it comes to practical tasks such as using SuperRes for medical imaging systems. One consequence of a biased medical imaging model is the generation of false positives and false negatives. For instance, incorrect detection of tumors or cancers. Contrary to common expectation, even a really good model cannot be treated as an objective metric for medical diagnosis. False negatives and false positives can come at the cost of high monetary loss and trauma for the patients involved. Therefore, in the case of medical imaging (and other medical tasks), it becomes very necessary that the data is collected and handled with a great deal of responsibility and consideration.
Results:
All results can be seen in the image Image gallery. We have extended the above results to videos by considering the frames of the video as low res inputs which are then passed to the SRGAN to produce high res images which can be stitched back together to form the high res video. We have included a sample video in our oral presentation [link: https://youtu.be/qPOHbwBIFx0].
To sum up, we feel that VGG-based loss is a better choice for SRGAN because it allows for perceptually better outputs by its texture and feature extraction properties. We have experimented with the VGG loss function and have decided to use an MSE of feature maps from various layers of the model, instead of just the 20th layer, as mentioned in the paper.
Future work on this project would involve adding a layer of temporal coherence in order to allow the generation of good high res videos without undesirable artifacts.
Image Super-Resolution:
- Low Resolution Image [1] High Resolution Image [1]
- Low Resolution Image [2] High Resolution Image [2]
- Low Resolution Image [3] High Resolution Image [3]
- Low Resolution Image [4] High Resolution Image [4]
- Low Resolution Image [5] High Resolution Image [5]
Video Super Resolution
- Live Video super-resolution using our model can be found here: https://youtu.be/CnQBXg7LD8s
Division of Labour
We have identified the following aspects of this project:
Division of Labour
- Image Preprocessing: Shashidhar
- Discriminator design: Aditya and Prashanthi
- Generator design: Shashidhar and Rugved
- Putting everything together: Everyone
- Training Setup: Aditya
- Training and Experimentation: Rugved
- Hyperparameter Tuning: Everyone
- Loss Function: Aditya and Prashanthi
Existing implementations
https://github.com/leftthomas/SRGAN https://github.com/krasserm/super-resolution https://github.com/AvivSham/SRGAN-Keras-Implementation
Reflections:
This project was firstly very interesting to work on, as it involves multiple complicated architectures. One of the most important learning aspects was using another model to calculate our loss. Also, as known training GAN's are complicated we learned a lot making our way through these problems. This project also introduced us to understand the challenges in the space of data engineering all the way across to training big architecture models. Lastly, understanding many aspects of the presented architecture by the model was vital since it was the most challenging.
[^9]: Image Quality Assessment: From Error Visibility to Structural Similarity by Zhou et.al. : https://ece.uwaterloo.ca/~z70wang/publications/ssim.pdf [^10]: Perceptual Losses for Real-Time Style Transfer and Super-Resolution: https://arxiv.org/abs/1603.08155 [^11]: Super-Resolution with Deep Convolutional Sufficient Statistics: https://arxiv.org/abs/1511.05666 [^12]: Image Quality Assessment: From Error Visibility to Structural Similarity: https://www.cns.nyu.edu/pub/lcv/wang03-preprint.pdf









Log in or sign up for Devpost to join the conversation.