-
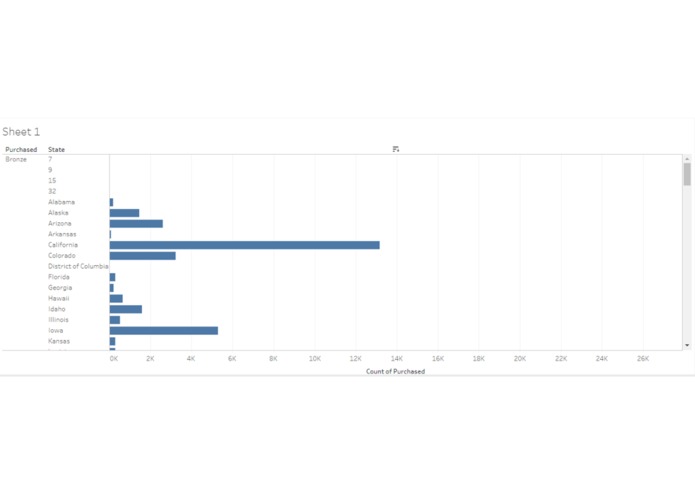
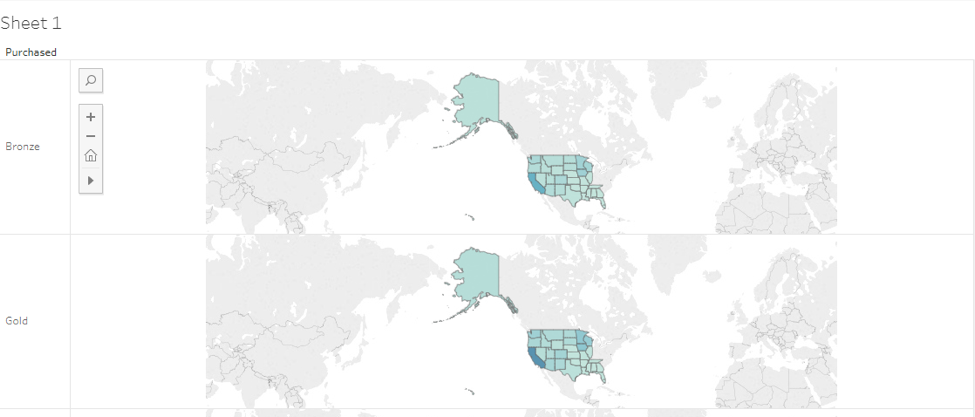
Relationship between plan level & state
-
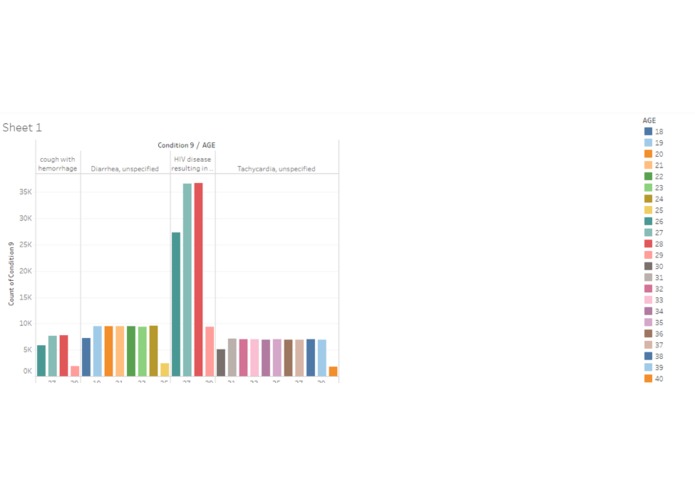
Commonality of preconditions
-
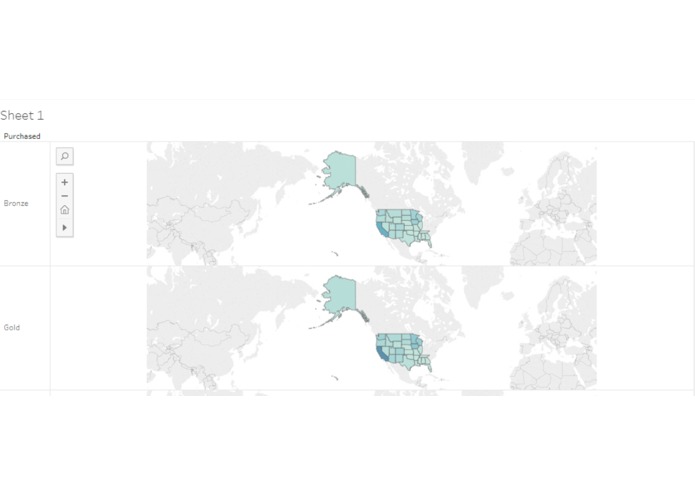
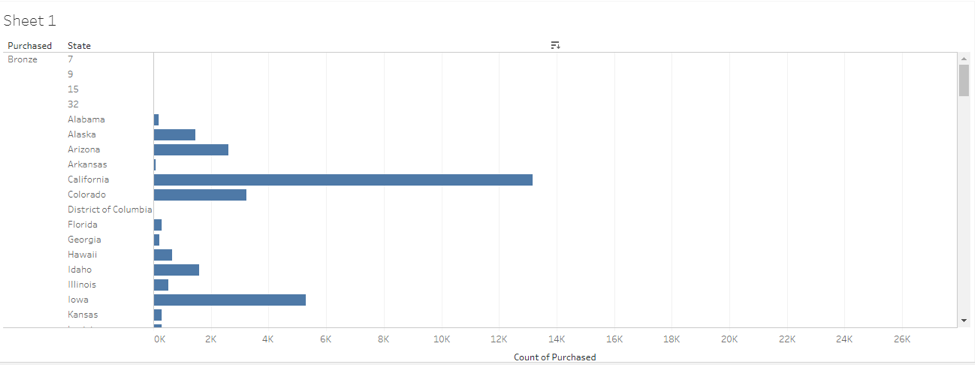
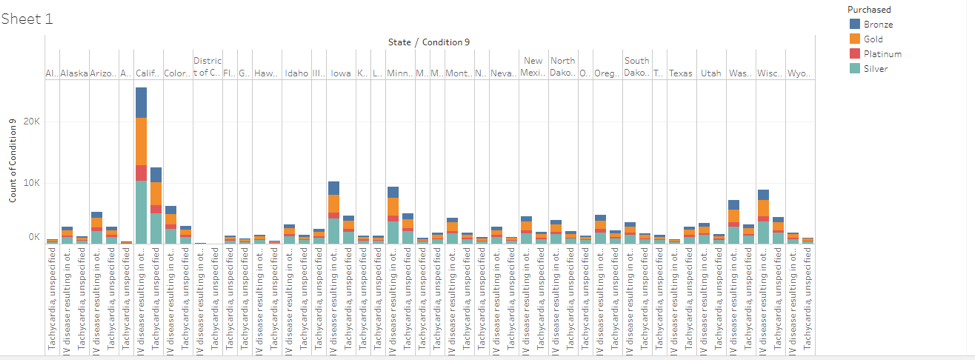
Insurance holders by state
-
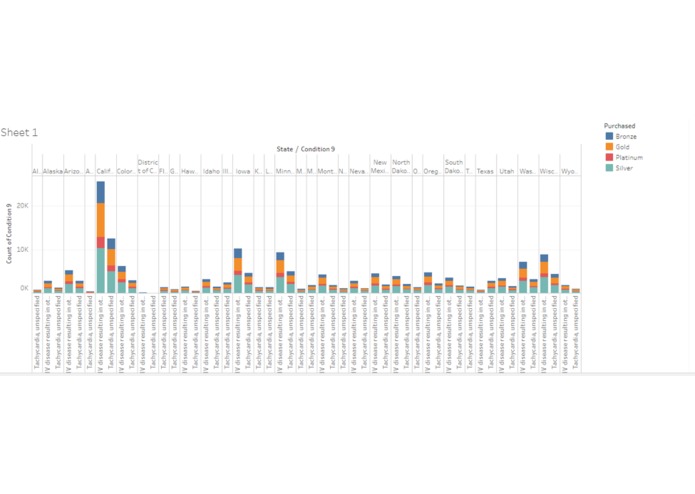
Common preconditions by state
-
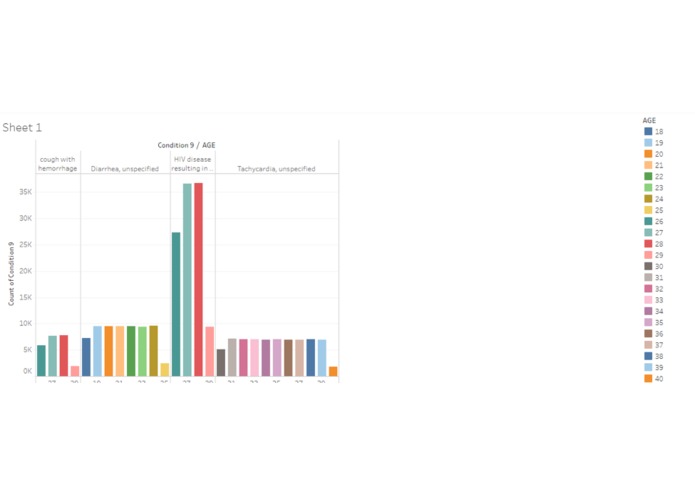
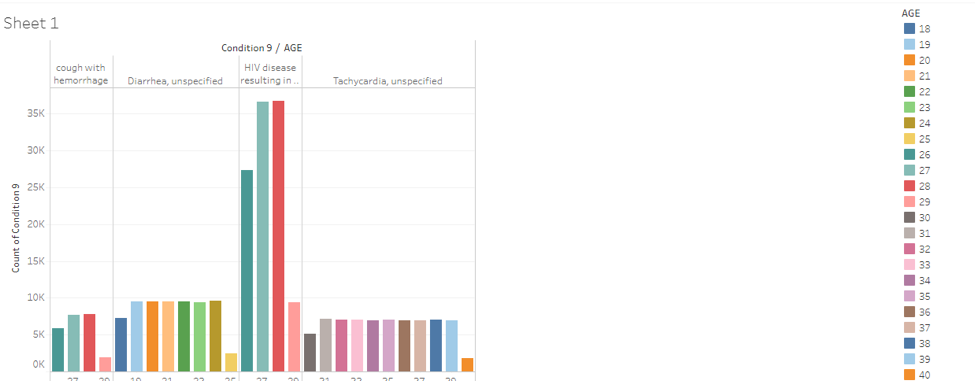
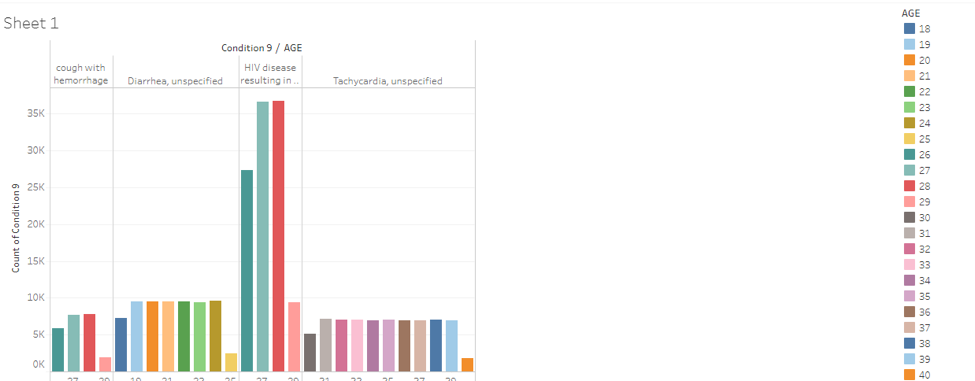
Representation of the conditions with the age distribution
Introduction
For this project, we are analyzing Vitech's health & insurance data to identify key variables that might affect the decision making process to determine the appropriate plan for a specific client. We use Solr query to process the data to a large JSON file, utilize data warehousing techniques to clean and segregate the data, then leverage machine learning methodologies and relevant Python libraries (Panda, Numpy, Scikit-learn) to analyze the data. We also use Tableau to generate data visualization and illustrate relationships between key variables in the case.
What's challenging
Extracting the data was not easy since it only allows to get ten data records at a time so we iterated through the entire data set and appended the new set of data to a large JSON file for later processing. Building the feasible machine learning model was also tricky because we have limited exposure to this subject domain, but after extensive research, we determined that K-means clustering works best under this scenario and successfully improved the predictive accuracy by 7%.

Log in or sign up for Devpost to join the conversation.