-
Enter your details to estimate your plan
-
Machine learning models predict price and preferred plan
-
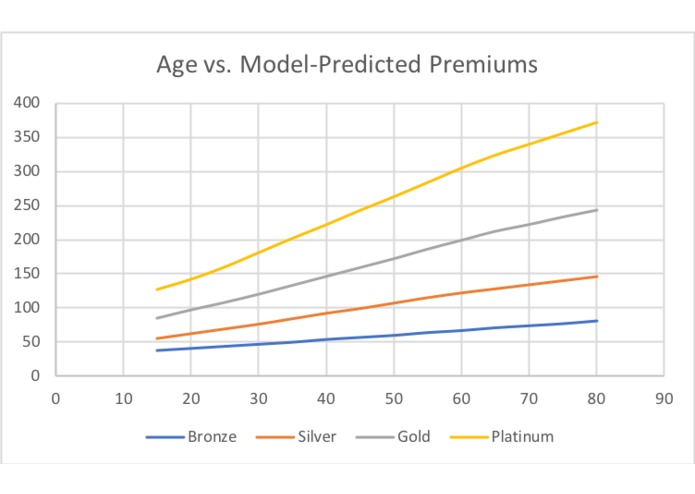
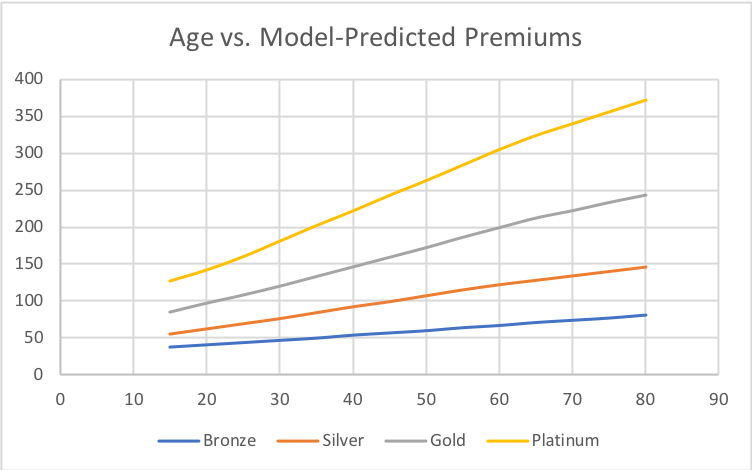
Graph of age versus model-predicted premiums
-
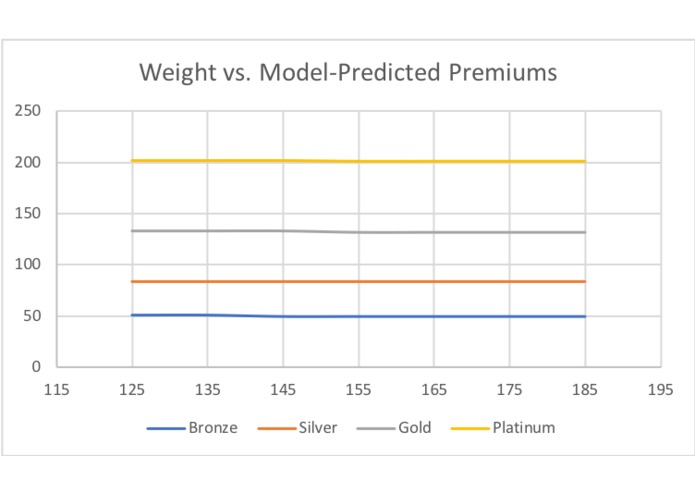
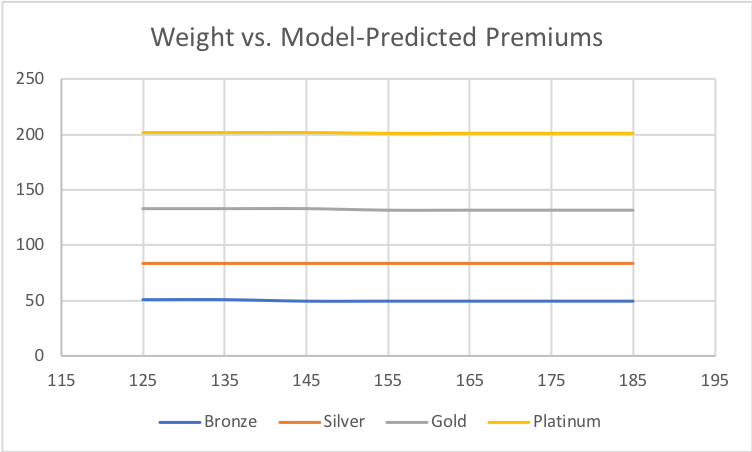
Graph of weight versus model-predicted premiums

Vitech Insurance Quote Predictor and Plan Recommender: McMaster Team #1 (The Beard) Sorry for the mess, we wish we had more time to clean up!
Screenshots and some nifty images available in the "Images" folder
Important Notes:
WIFI is super unreliable, front end may not connect with server Front-end may be slow as the server side code wasn't fully realized Front-end relies on the server side to be hosted (on a users laptop)
Quoting the Price (Machine Learning):
A wide neural network was used to model the quoted price for each plan. Unfortunately there was little time/processing power to play around with the hyperparameters of the network, however for price prediction were able to achieve a low mean squared error (between 10-12 each plan) which would be an average absolute error of around $3 in the montly plan price. Four seperate regression networks were for each plan using 5500 randomly selected entries from the database of people. As there were too many ICD codes to process, we condensed the codes into their hierarchical buckets and tracked the number of "high", "medium", and "low" risk conditions per bucket and fed that into the network. The network parameters and hyperparameters were saved to two files per network and loaded as needed. Network could be improved with more training time and data
Code:
bronze_quote_model.py: model for the network used to quote prices for the bronze plan (Mean Square Error ~ 10) silver_quote_model.py: model for the network used to quote prices for the silver plan (Mean Square Error ~ 11) gold_quote_model.py: model for the network used to quote prices for the gold plan (Mean Square Error ~ 12) plat_quote_model.py: model for the network used to quote prices for the platinum plan (Mean Square Error ~ 12) fitData.py: used by the server to compile the saved network data and make predictions Guessing the Purchased Plan (Machine Learning):
Guessing the plan the customer picks was one of our ambitious goals. We were able to construct a basic wide neural network for classification(no reason for width instead of depth) however there was not enough time or processing power to tune the hyperparameters. Prediction accuracy was low for the test data we used, indicating that either not enough training data was used, or that there was no relation between parameters and plan chosen Initially the quoted price plans were included in the parameters, however we found that these did not actually affect the accuracy of our network for the limited training data we had. In the end, this classification network made use of the same 5500 randomly selected entries as the regression networks.
Code:
picker_model.py: model for the network used to quote prices for the bronze plan (Accuracy ~ 35%) fitData.py: used by the server to compile the saved network data and make predictions Dependencies:
Main architecture: Anaconda Python 5.0.1. simplejson for encoding and decoding JSON requests. The default http.server Python package reponses to requests. The server is hosted on DigitalOcean's Cloud Ubuntu servers. neural network makes use of scipy, numpy, pandas, scikit-learn, tensorflow, and kerasss This program makes use of the Keras package with tensorflow for the neural network. Problems Encountered and Overcome:
Unfortunately there were many limiting factors towards training our model. The primary issue we ran into was the lack of internet connectivity which restricted our ability to work on this problem, given the big data nature of the problem. Our initial intention was to host all the parameters we needed in a Google Cloud bucket and make use of the Google Cloud Platform's machine learning to make use of the platforms power and robustness.
Future Work and Improvements:
Most statistical analysis should be performed to analyze the networks and the correlations amongst variables. Given additional time, we would like to tune the neural network parameters/hyperparameters as well as explore different classifiers/clustering algorithms to find more emergent features.
Built With
- css3
- html5
- http.server
- javascript
- jquery
- keras
- numpy
- pandas
- scikit-learn
- scipy
- tensorflow




Log in or sign up for Devpost to join the conversation.