Inspiration
When we first read Vitech's challenge for processing and visualizing their data, we were collectively inspired to explore a paradigm of programming that very few of us had any experience with, machine learning. With that in mind, the sentiment of the challenge themed around health care established relevant and impactful implications for the outcome of our project. We believe that using machine learning and data science to improve the customer experience of people in the market for insurance plans, would not only result in a more profitable model for insurance companies but improve the lives of the countless people who struggle to choose the best insurance plans for themselves at the right costs.
What it does
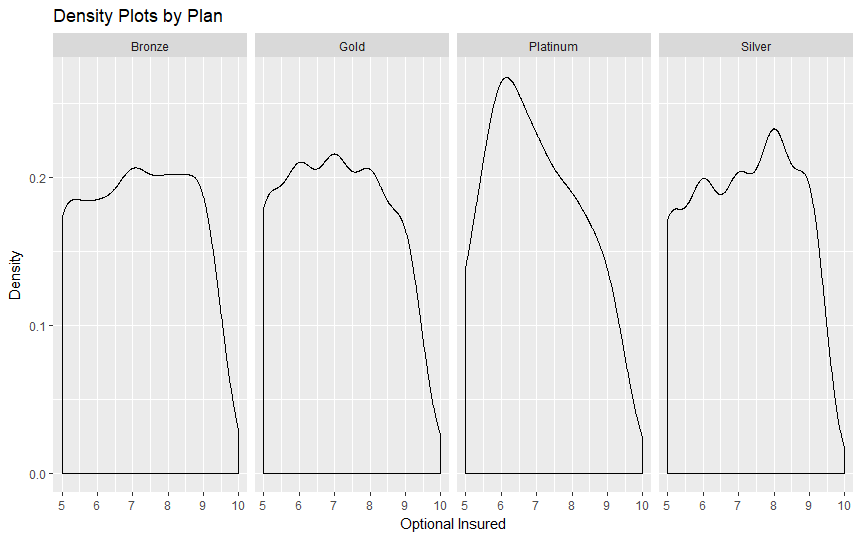
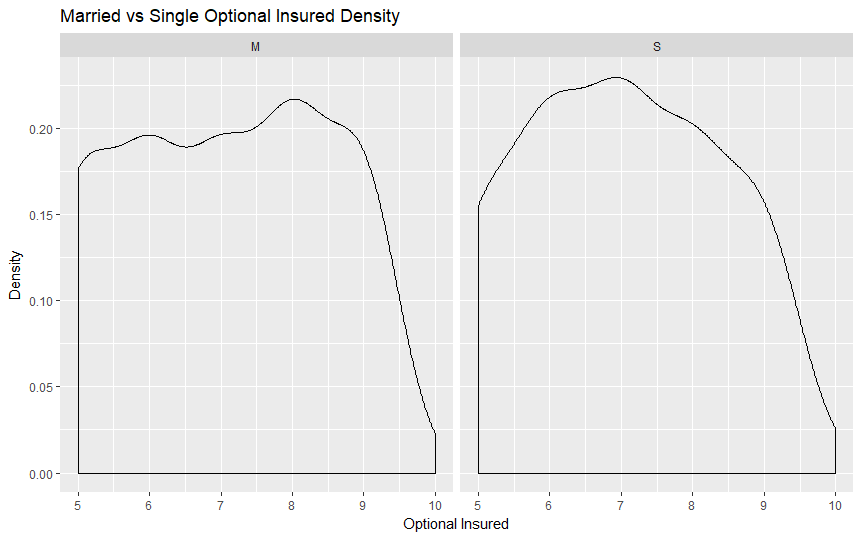
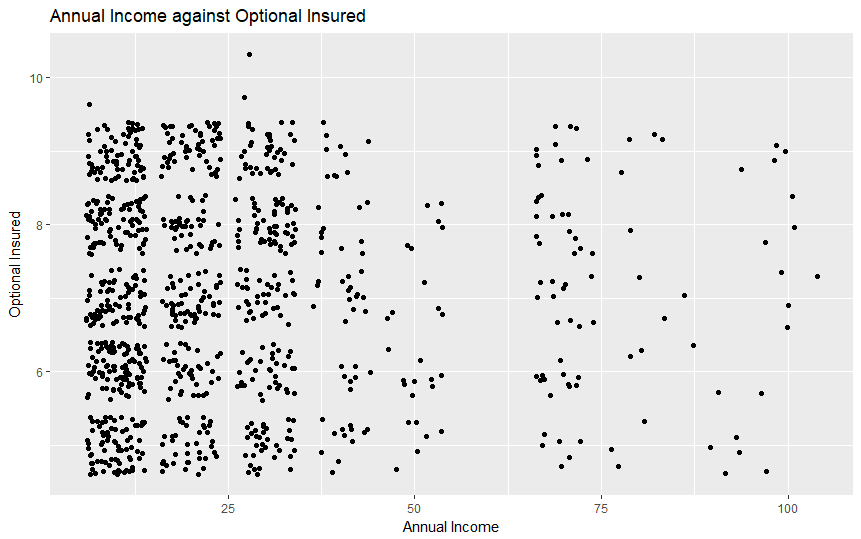
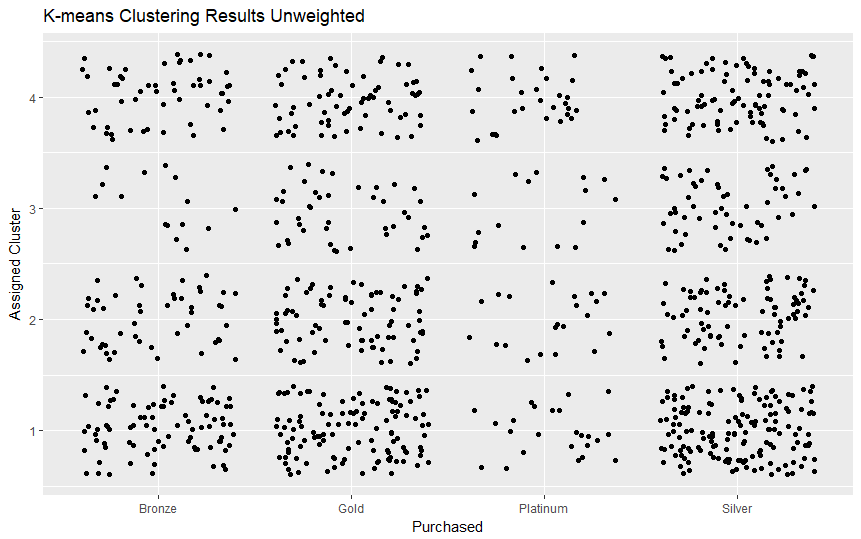
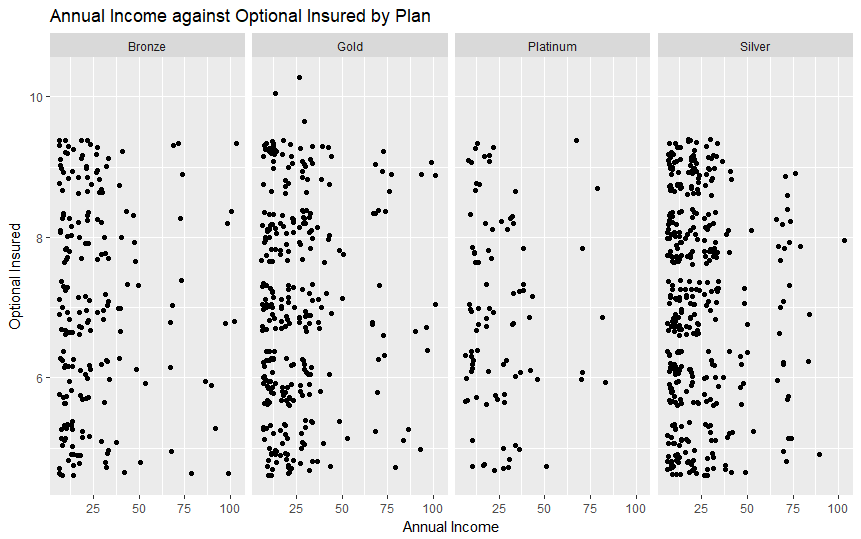
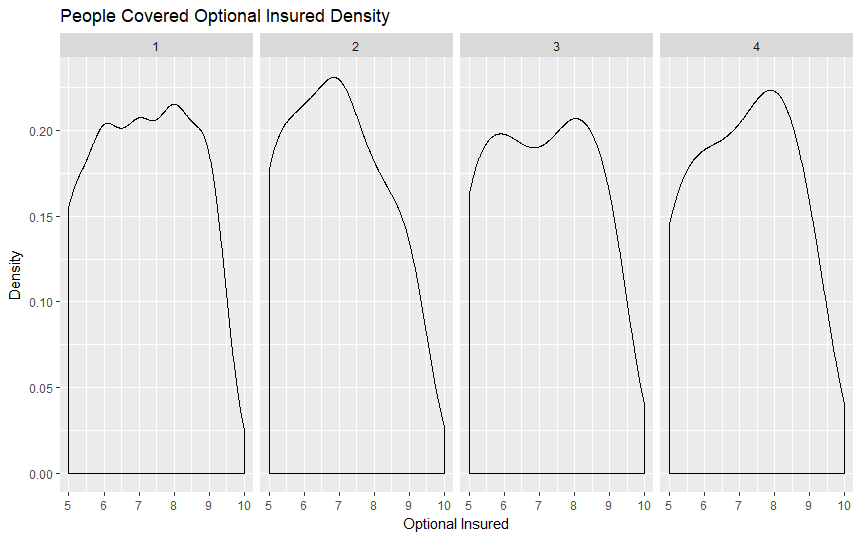
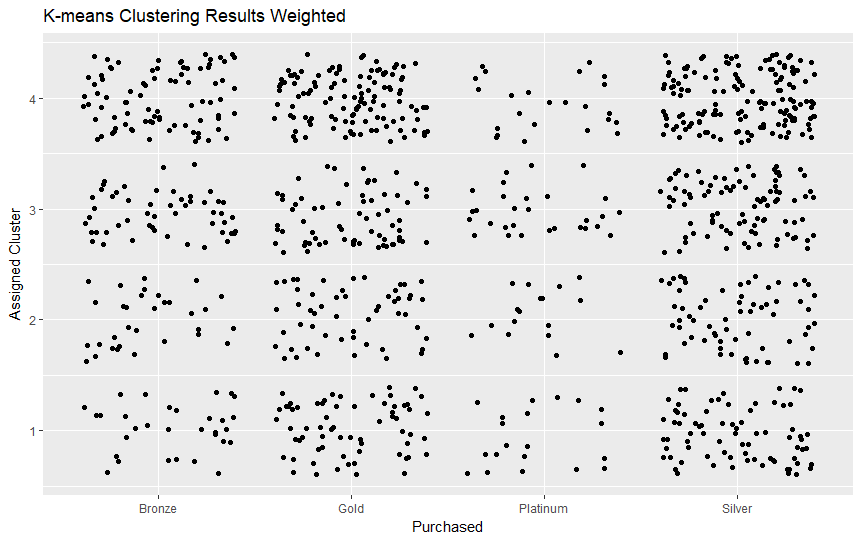
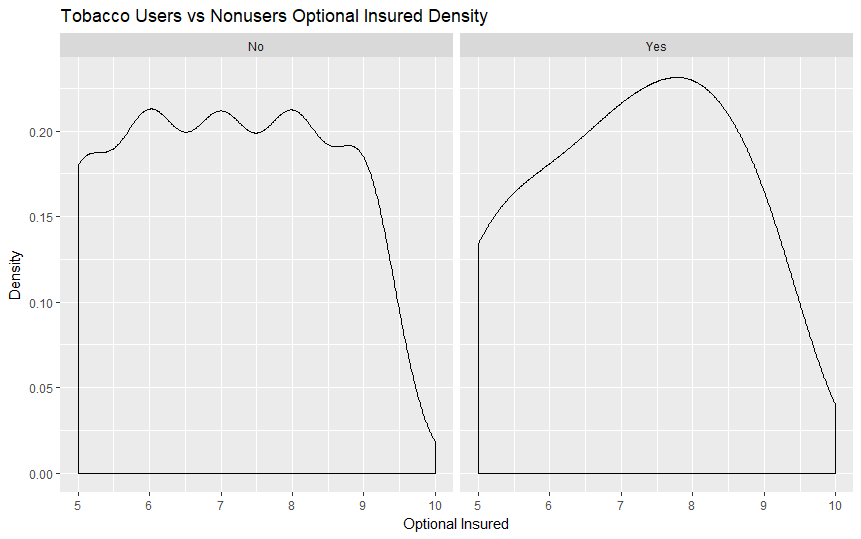
Our scripts are built to parse, process, and format the data provided by Vitech's live V3 API database. The data is initially filtered using Solr queries and then formatted into a more adaptable comma-separated variable (CSV) file. This data is then processed by a different script through several machine learning algorithms in order to extract meaningful data about the relationship between an individual's personal details and the plan that they are most likely to choose. Additionally, we have provided visualizations created in R that helped us interpret the many data points more effectively.
How we built it
We initially explored all of the ideas that we had regarding how exactly we planned to process the data and proceeded to pick Python as a suitable language and interface in which we believed that we could accomplish all of our goals. The first step was parsing and formatting data after which we began observing it through the visualization tools provided by R. Once we had a rough idea about how our data is distributed, we continued by making models using the h2o Python library in order to model our data.
Challenges we ran into
Since none of us had much experience with machine learning prior to this project, we dived into many software tools we had never even seen before. Furthermore, the data provided by Vitech had many variables to track, so our deficiency in understanding of the insurance market truly slowed down our progress in making better models for our data.
Accomplishments that we're proud of
We are very proud that we got as far as we did even though out product is not finalized. Going into this initially, we did not know how much we could learn and accomplish and yet we managed to implement fairly complex tools for analyzing and processing data. We have learned greatly from the entire experience as a team and are now inspired to continue exploring data science and the power of data science tools.
What we learned
We have learned a lot about the nuances of processing and working with big data and about what software tools are available to us for future use.
What's next for Vitech Insurance Data Processing and Analysis
We hope to further improve our modeling to get more meaningful and applicable results. The next barrier to overcome is definitely related to our lack of field expertise in the realm of the insurance market which would further allow us to make more accurate and representative models of the data.



Log in or sign up for Devpost to join the conversation.