

Inspiration
We were inspired by the sheer amount of data and what mysterious we could find.
What it does
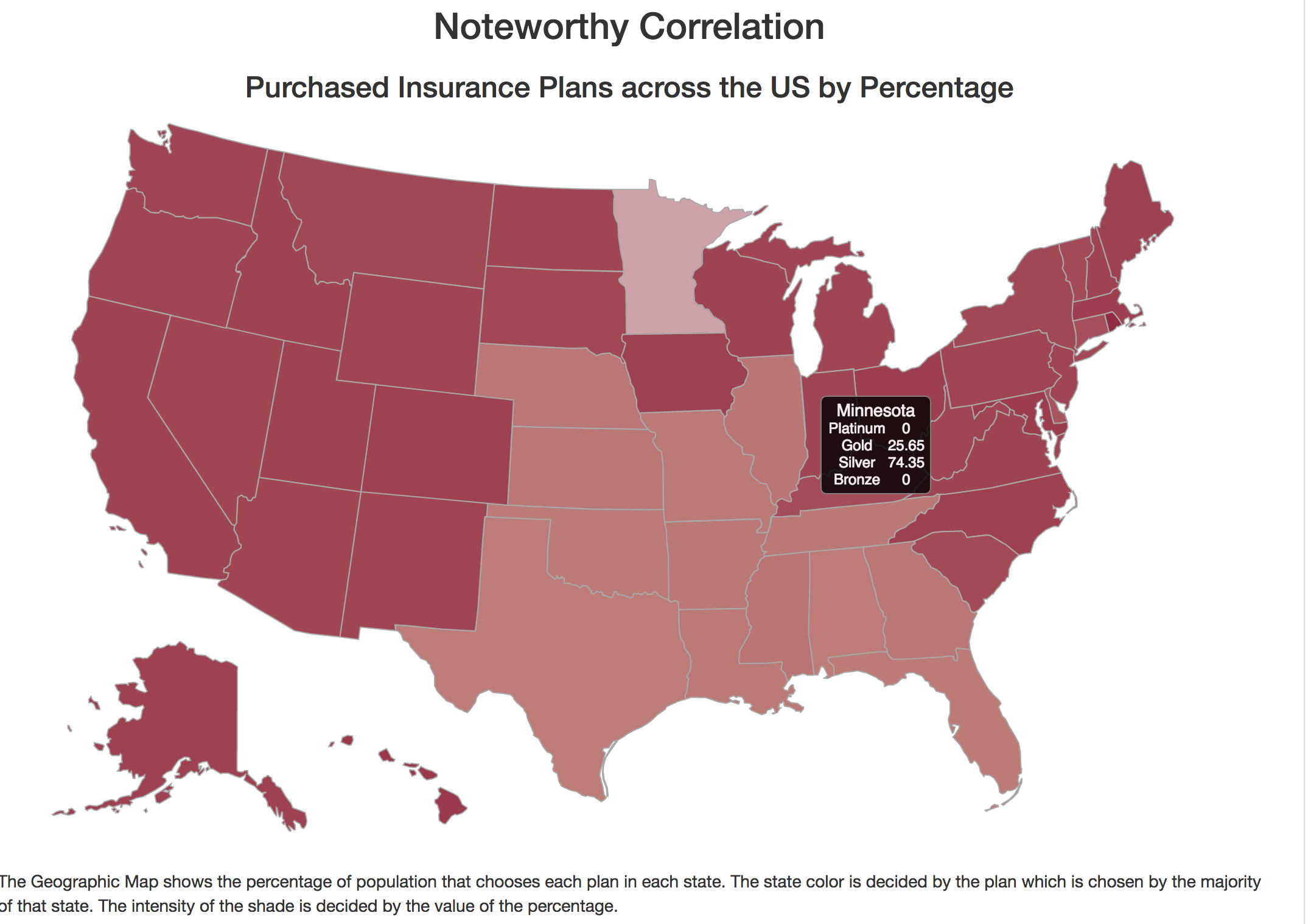
Our project involves a summary of different features we considered during data analysis. These involve interesting discussions of very unusual and unexpected trends in the Life Insurance Quoting data. We used the remaining features that do affect the premiums as features to train our machine learning model. The idea is to be able to predict quotes or choices of profiles.
How we built it
We analyzed using python's pandas library, R, and a couple JS visualization modules. The machine learning uses Tensorflow.
Challenges we ran into
We were unable to get the full data from the source due to unstable and slow internet until Saturday night.
Accomplishments that we're proud of
We were nonetheless able to inspect the data thoroughly, produce interesting data visualization and findings that lead to open-ended discussions. We also have a great UI that can be useful to customers shopping for a life insurance.
What we learned
We learned a lot about analyzing data using Pandas, Flask, and also Tensorflow.
What's next for Vitech Data Analysis
The data given is very strange. It would be interesting to look into how those data were acquired, dig into the reasons certain unexpected phenomenon were happening, and so forth. From that, perhaps a better quote-producing formula/model can be produced that takes into consideration a greater number of more relevant factors.
Log in or sign up for Devpost to join the conversation.