-
-
The project was updated and improved on TRAE
-
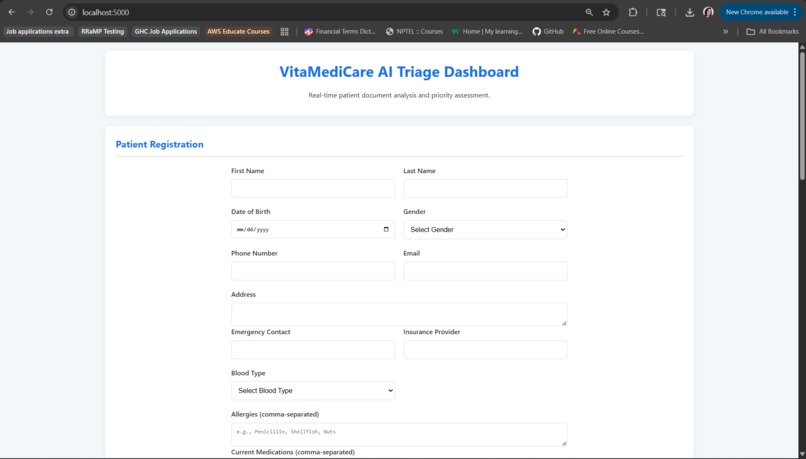
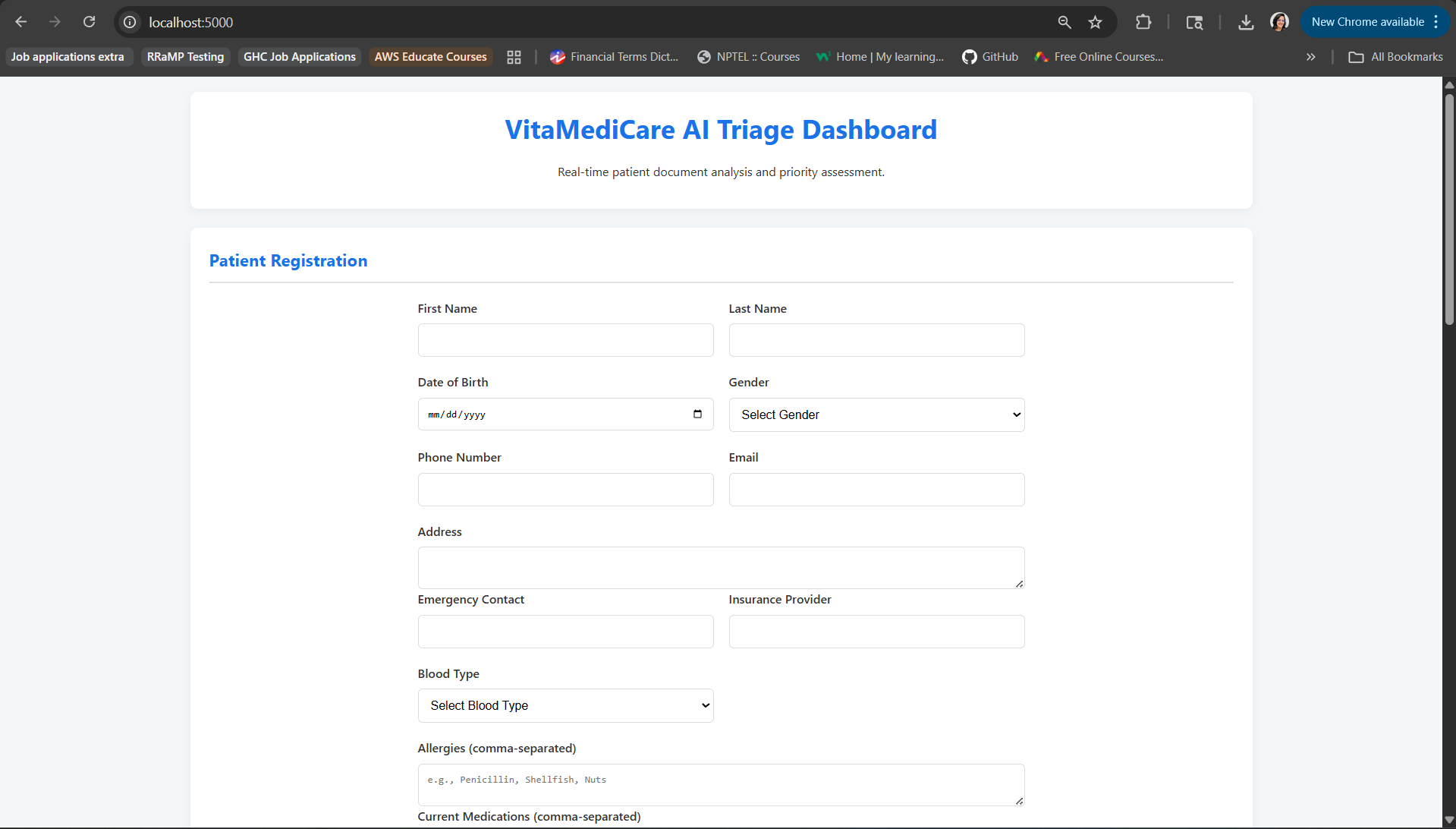
Registration Dashboard
-
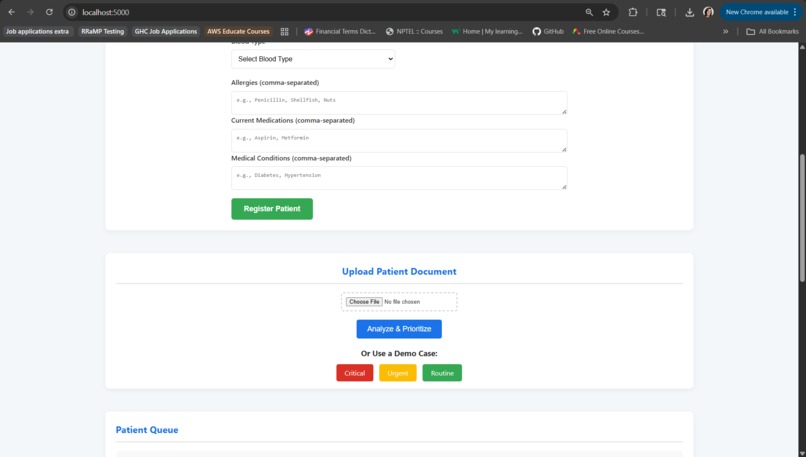
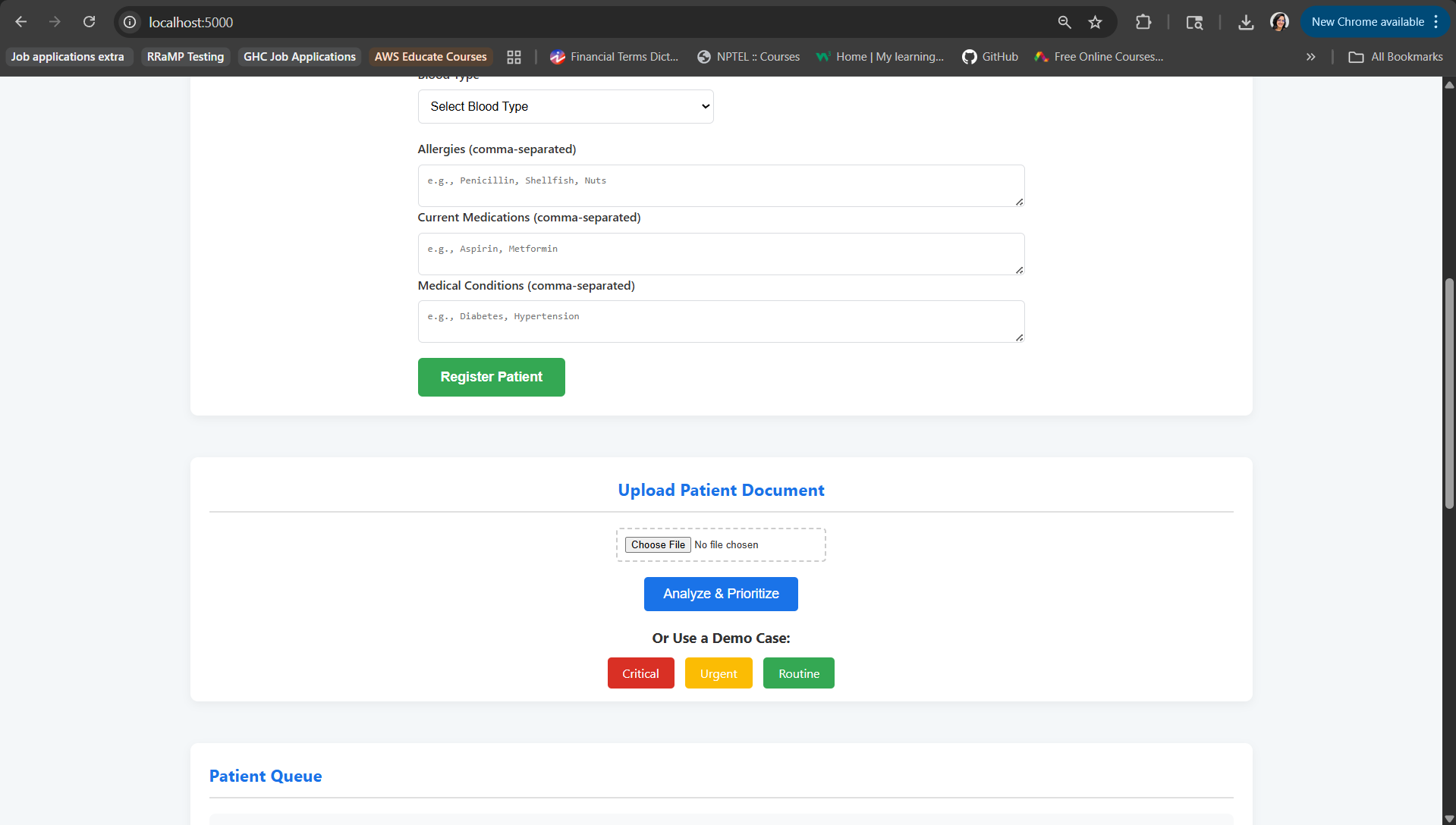
File upload section
-
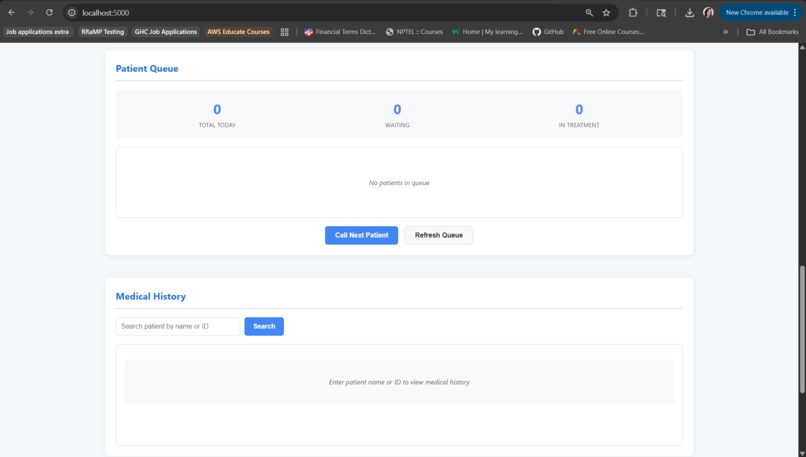
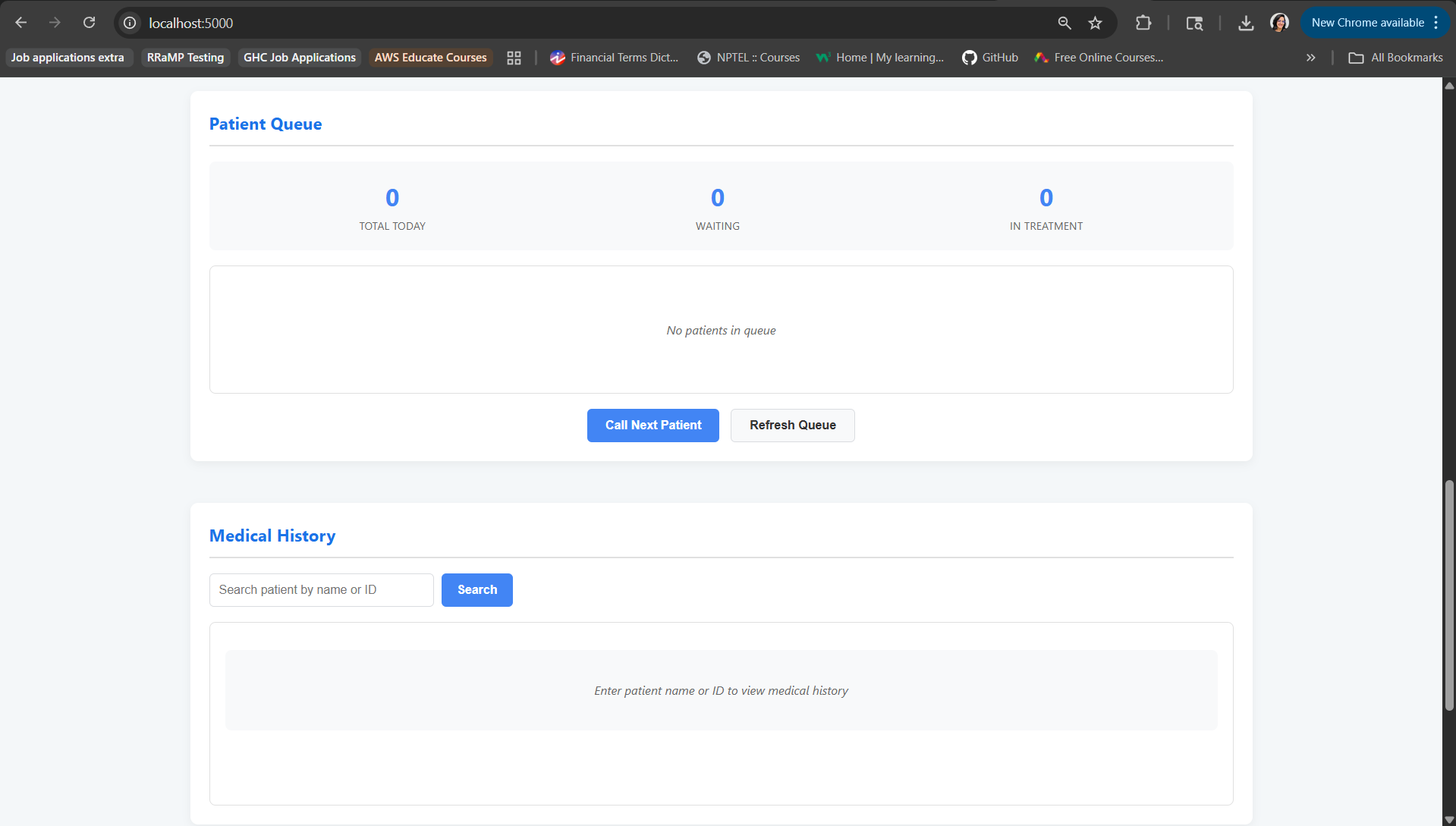
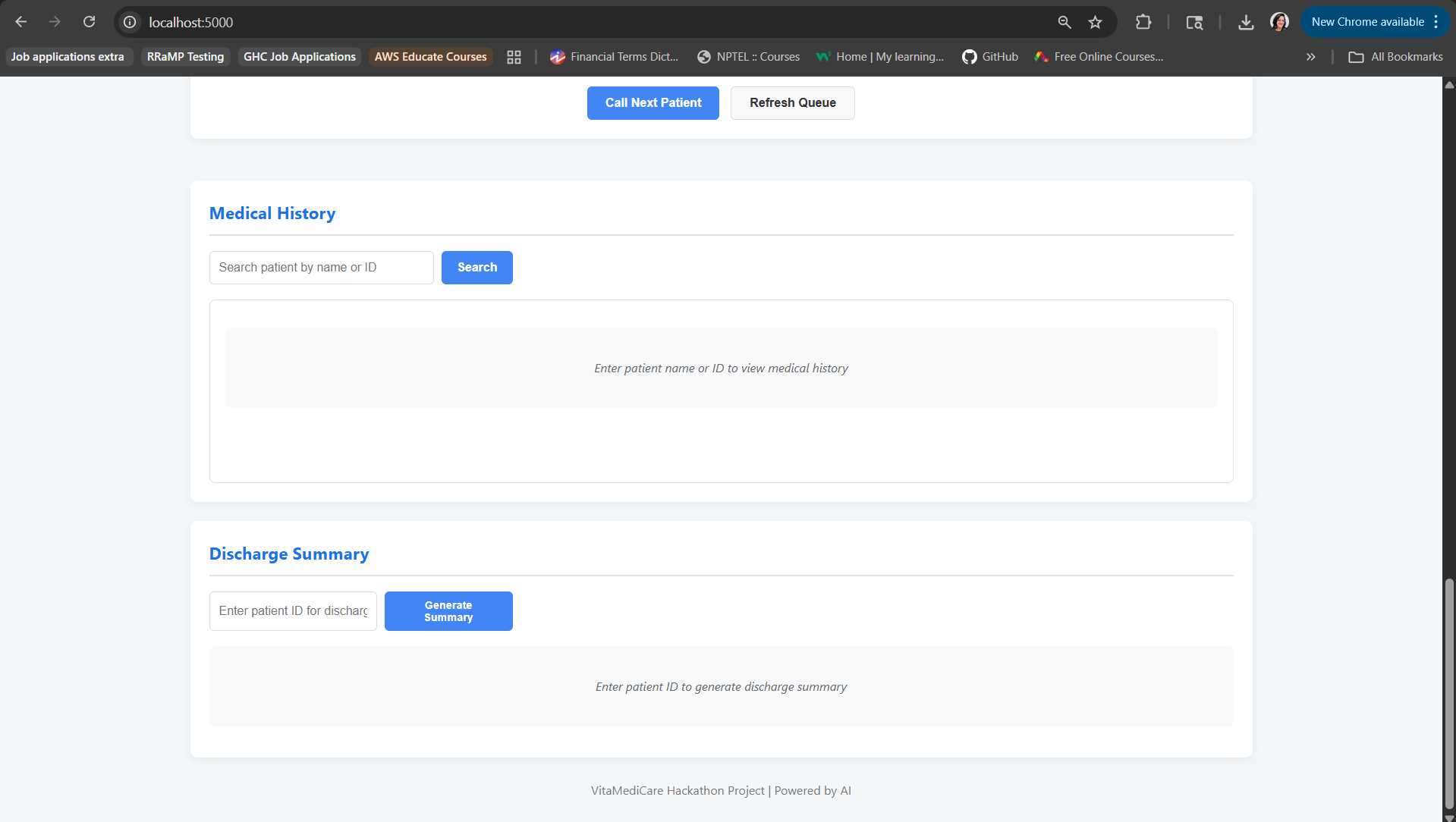
Patient Queue and Medical History Track
-
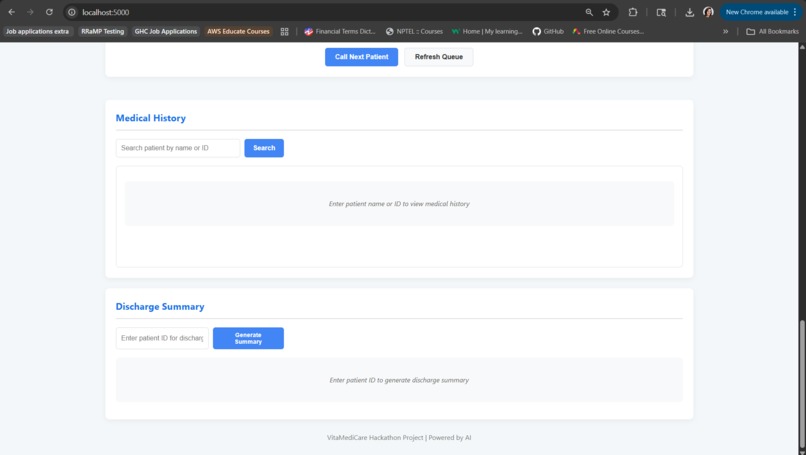
Discharge Summary Track
Inspiration:
Healthcare documentation often lives across disconnected artifacts—operative notes, lab results, discharge summaries, prescriptions, and portal messages. Patients can’t easily track the full story, and clinicians often spend time reconstructing context across pre-care preparation → active treatment → post-care recovery.
During a family member’s hospital stay, I saw how fragmented information leads to repeated questions, slower decisions, and avoidable anxiety—especially around what happened, what needs to happen next, and what changed between stages of care.
VitaMediCare AI was built to make the patient journey stage-aware and review-ready: upload a document, automatically extract structured fields for Pre / During / Post, then run a validation pass that highlights missing fields, conflicts, and follow-up questions clinicians can act on immediately.
What it does:
VitaMediCare AI turns unstructured medical documents into a structured, phase-segmented care record with a built-in “review layer.”
Core workflow (3 stages)
- Document intake & parsing:
Upload PDF/document → extract text + metadata.
Stage-aware segregation (specialized agents):
Pre-Procedure Agent: history, allergies, consent, prep checklist, labs, risk factors.
During-Procedure Agent: procedure summary, anesthesia, meds administered, key events, vitals highlights.
Post-Procedure Agent: recovery status, discharge instructions, follow-ups, prescriptions, complications.
Validation & clinical review support (validator agent):
Produces:
- Missing fields (per stage)
- Conflict flags (e.g., allergy vs meds, timeline inconsistencies)
- Questions for staff (human-in-the-loop clarifications)
What makes it “agentic” (not just extraction):
- Instead of returning raw extracted data, VitaMediCare AI returns a decision-support layer:
- “Here’s what we found”
- “Here’s what’s missing”
- “Here’s what looks inconsistent”
- “Here are the questions to resolve uncertainty”
How I built it:
Architecture (high level):
[Interactive UI] | upload / review / edits v [Orchestrator API] | routes pipeline, merges outputs v [MCP Tool Server] | extract_text() | extract_stage(pre|during|post) | validate_record() | save_record() v [Storage] JSON / SQLite (hackathon-friendly)
Why MCP: I used an MCP tool server to expose the pipeline operations (parse, stage-extract, validate, persist) as standardized “tools.” That makes the system easier to extend (swap parsers, swap models, add new tools like OCR, add new agents) without rewriting the orchestrator.
Agents:
- Pre/During/Post Extraction Agents: Strict JSON schema output (phase-specific) Stage prompts optimized to reduce cross-contamination (“post-op details” leaking into “pre-op”)
- Validator Agent: Detects missing fields and contradictions Generates short, actionable questions for clinicians Encourages transparency: flags uncertainty rather than “guessing”
Interactive UI
- Uploads a document and displays results in three tabs: Pre-Procedure / During / Post
- Shows “review layer” panel: Missing fields, conflict flags, questions
- Allows editing extracted fields (human-in-the-loop correction)
Technology Stack:
Backend + orchestration
- FastAPI (or Node/Express) as the orchestrator API
- MCP tool server for standardized tool endpoints (parsing, extraction, validation)
- Optional: WebSockets/SSE for progress updates (“Parsing…”, “Extracting Pre…”, etc.)
Document processing
- PDF text extraction (fast text-based parsing)
- Optional OCR fallback for scanned PDFs (only if needed)
AI / LLM layer
- 3 stage extraction prompts (Pre/During/Post)
- 1 validator prompt (missing/conflict/questions)
- Optional retrieval layer: embeddings + vector store for cross-document patient history search
UI
- Gradio (fastest hackathon UI) or React/Next.js
- Editable structured output + export
Storage
- SQLite / JSON (hackathon-friendly)
- Optional: cloud storage for uploaded docs
Challenges I ran into:
- Stage segmentation reliability
- Clinical notes are messy; sections aren’t always labeled consistently.
Solution: stage-specific prompts + light heuristics for section targeting.
Hallucination risk in medical contexts
Extraction models sometimes “fill in” fields.
Solution: strict schema + validator agent + “unknown/not found” allowed outputs.
Large notes & performance
Long patient histories can blow up tokens and slow response.
Solution: stage-focused extraction + bounded text windows + optional retrieval.
Balancing comprehensiveness with usability
Too much data overwhelms users.
Solution: highlight what matters most: missing fields + conflicts + next questions.
Accomplishments that I'm proud of:
- End-to-end agent pipeline aligned to real clinical phases
Built a complete flow from upload → extraction → phase segregation → validation → UI review.
Validator layer that makes outputs actionable
Instead of dumping raw JSON, the system produces a clinical “review checklist”: missing fields, conflicts, and staff questions.
Tool-based design via MCP
Modular pipeline: easy to add OCR, new agents, new validations, or swap models without changing the whole system.
Human-in-the-loop UX
Designed for real workflows: extracted fields are editable, and the system clearly surfaces uncertainty instead of guessing.
Privacy-first direction (within hackathon constraints)
Built assuming de-identified demo docs; structured output designed to support consent-based access later.
What I learned:
Technical
- How to build multi-agent pipelines that don’t fight each other (stage specialization matters).
- How to reduce hallucinations with schema constraints + validation passes.
- How to structure a system around tools (MCP) for extensibility and clean interfaces.
- How to design an app for fast review: extraction is only half the problem—triage and clarity matter.
Domain + product
- Clinical workflows are phase-based; aligning AI outputs to phases makes adoption easier.
- A good healthcare UX prioritizes: “What’s missing?” “What’s conflicting?” “What should I do next?”
Execution
- In a hackathon, scope discipline wins: a tight pipeline with a strong demo story beats 10 half-built features.
What's next for VitaMediCare AI:
- OCR fallback for scanned documents + structured citations to page/line snippets.
- FHIR-compatible export (structured resources instead of only JSON).
- Longitudinal timeline view across multiple visits and documents.
- Role-based experiences: patient view vs clinician view.
- Safety upgrades: policy checks, stronger provenance/citations, model confidence calibration.
- Integrations: telemedicine summaries, wearable data ingestion, multilingual support.
Built With
- devswarm
- git
- langchain
- node.js
- rag
- react
- restapi
- trae
- typescript
- vscode

Log in or sign up for Devpost to join the conversation.