Inspiration
Because of the emergence of the COVID-19 pandemic, students were forced to adapt to virtual learning. Studying past data from a virtual learning environment can help teachers identify which students are more at risk of withdrawing or failing the course in this new learning environment. Then, teachers are able to give additional support to these students, who might fail or withdraw without support.
With a goal of making virtual education more inclusive, we studied the demographics of students and the connections to engagement and final results (pass, fail, distinction, withdrawn). We studied the multifaceted aspects of student identity and background in order to understand how intersectionality (of gender, poverty level, and disability) may impact their ability to engage or succeed in online courses. By studying the Multiple Deprivation Index, we analyzed whether poverty level impact's student experience.
We also built a tool to help teachers predict which students need the extra support in order to pass the course. Providing some information, the model predicts whether students will fail, pass, pass with distinction, or withdraw if they do not receive any outside help.
As teachers understand which student is at risk of struggling with a course, they can better support them. Supporting students in poverty can take children out of the school-to-prison pipeline, brightening their futures. We also studied which activity types best help students with disabilities succeed in courses. It is important to support all students and see what activity type best supports the disadvantaged students that might not have the opportunity to succeed without the teachers' help.
In addition, many students are wondering whether they can succeed in a remote environment or not. We came up with a classification based ML solution that uses the dataset we cleaned, transformed, and analyzed; so that we can determine whether a student simply has a chance of passing or failing the course (based on the data).
What it does
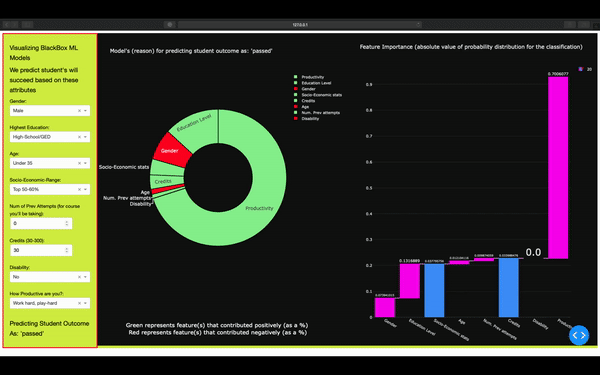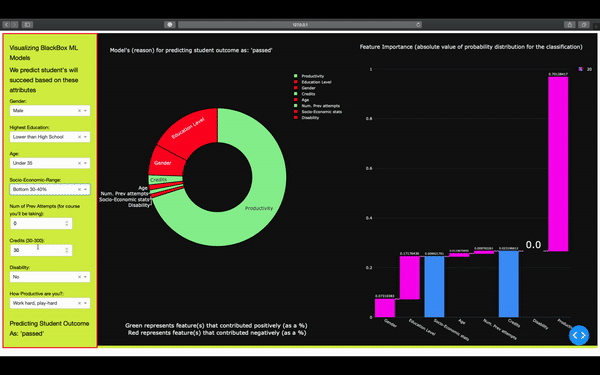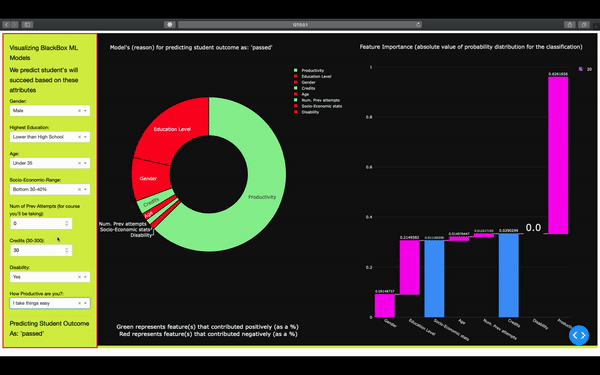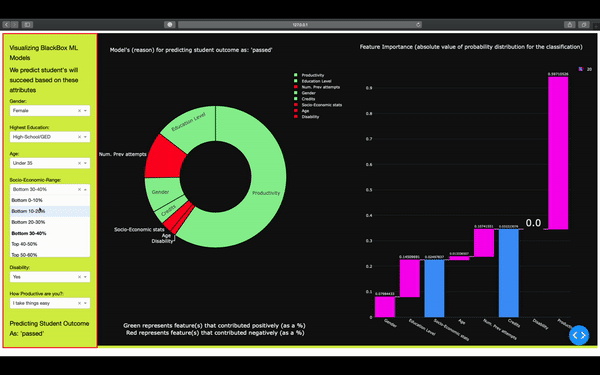
On the front end, the user selects different attributes. On the backend, these options are translated into a vector that's fed into the ML model for predicting the student's outcome in the semester (pass or fail). ML model returns back the outcome, as well as the different attributes that contributed to the outcome. Here we know exactly which feature/attribute influenced the model.
How we built it
We analyzed the datasets to see what affects whether a student will pass, fail, withdraw, or pass with distinction. We used this information to build a tool that teachers can use to identify which students need support in order to pass the class. We used Plotly Dash for front-end and for graphing.
DATASET: https://analyse.kmi.open.ac.uk/open_dataset
Challenges we ran into
During one part of our work time, Julia was under a tornado warning and lost power for over 18 hours. This limited the amount of time we could work together on this project.
In addition, the dataset was from the UK. Credits in the UK don't work the same way as they do in the US. For example, our dataset contained a range from 30-300. In addition, the attribute which described the highest education certificate of the student was in accordance with the UK's definitions. Thus we had to do research to correctly translate this back to US equivalent terms.
Accomplishments that we're proud of
We managed to extract and feature engineer a new attribute (productivity). We built a machine learning pipeline that utilized an XGBoost classifier model, Bayesian Optimization, and for classifying, hyperparameter tuning, and reducing the chances of overfitting our data.
What we learned
We learned that making sure that students are engaged when learning is important for their success in the course. Teachers should make sure that their virtual education platforms and websites encourage engagement so that students learn actively instead of just passively listening to a lecture.
What's next for Analyzing Virtual Education Platform
We hope to put this helpful tool up on the web so teachers can use it!






 Gomes")



Log in or sign up for Devpost to join the conversation.