-
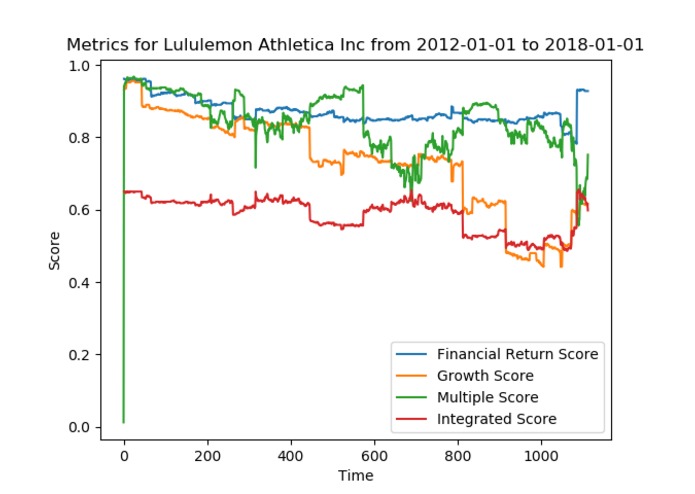
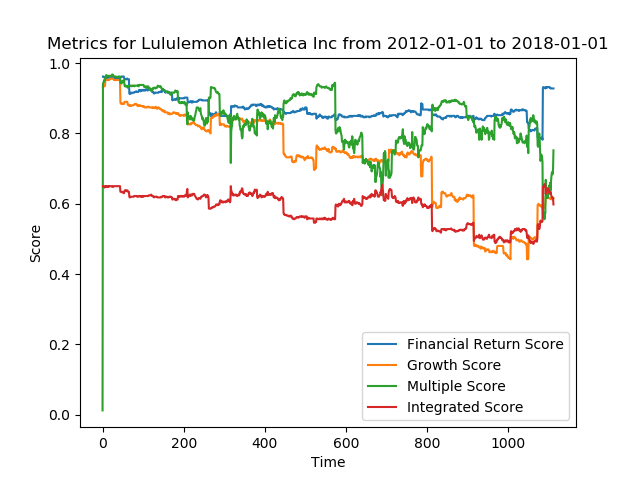
Visualization component—example: Lululemon Athletica, Inc.
-
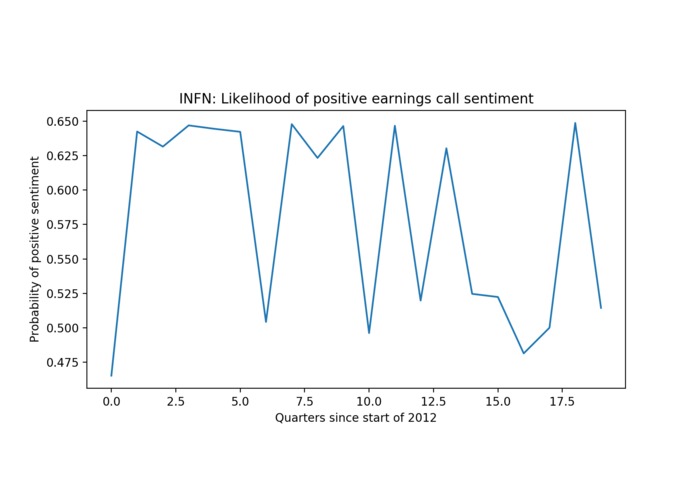
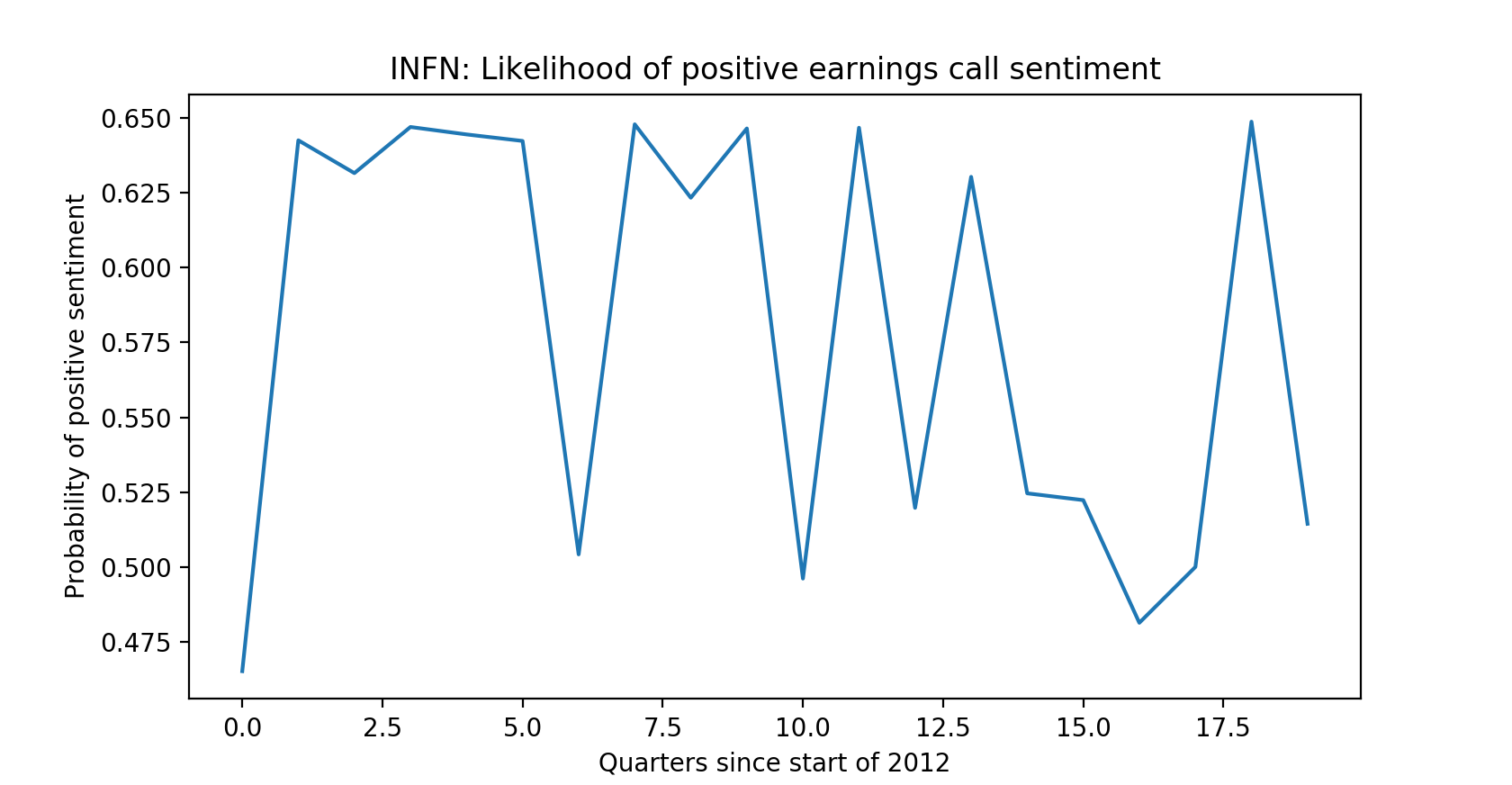
Sentiment analysis component—example: Infinera Corp.
-
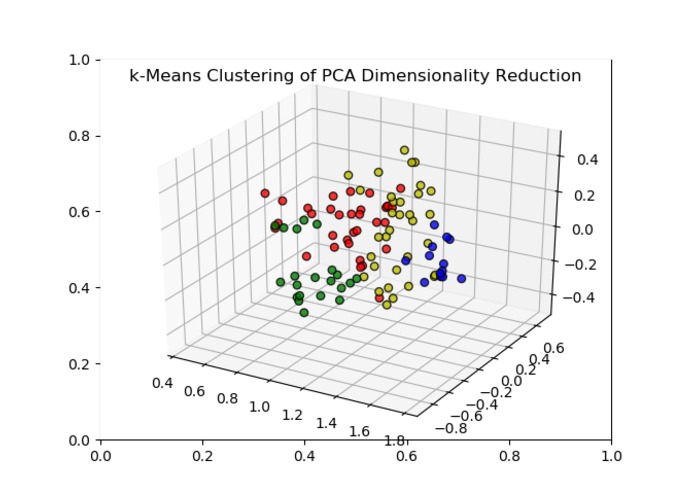
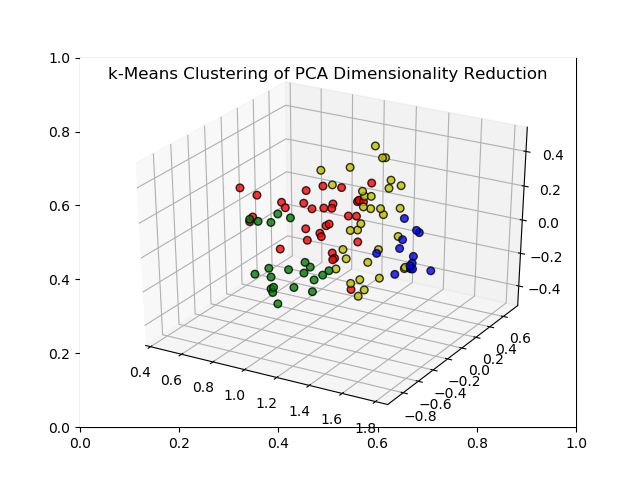
K-means clustering and PCA component—example: 4 clusters (R, G, B, Y).
Inspiration
We wanted to come up with a means of evaluating Goldman Sachs' GIR forecasting data against the market, and also against other possible predictors. This placed a heavy emphasis on meaningful visualizations of the given Marquee API data.
What it does
This project is composed of a series of Python scripts. It is divided into three components.
Visualization. This script takes in a ticker symbol and a start and end date (within the 5-year range for which we have GIR data for), and plots the four provided GS metrics—financial returns, growth, multiple, and integrated—against each update within the specified time range. This allows visually developing a sense of change in forward-looking guidance for any particular security over any supported period of time.
Sentiment analysis. In order to make this portion most interesting, we found the two securities with the highest variance in integrated score, and attempted to determine how well the sentiment of the Q&A portions of the quarterly earnings calls with shareholders predicted the GIR metrics. We obtained the Q&A portions of the earnings calls between the 1st quarter of 2012 and the 4th quarter of 2016, cleaned this data, and performed sentiment analysis to determine the likelihood of the Q&A section of the call being positive. We then graphed this probability against the number of quarters since the start of 2012. For the two securities in question, we found remarkable variance in this probability.
K-means clustering and PCA. We used the four metrics provided by the Marquee API (financial returns score, growth score, multiple score, and integrated score) to perform unsupervised learning on the dataset. First we used PCA to project the dataset from 4 dimensions into 3 to allow for easier visualization. Then, we performed k-means clustering to cluster the lower-dimensional data into 4 clusters so as to give potential clients a better understanding of the diversity in the dataset. The lower-dimensional clustering allows the user the ability to understand the similarities and differences among different stocks along axes which correspond to the greatest variance in the dataset.
How we built it
We used Python as the primary programming language for all components, with the help of libraries such as numpy, pandas, and matplotlib. We made use of a number of APIs, including Marquee for the GS data, and APIs for sentiment analysis.
Challenges we ran into
We ran into a great deal of difficulty finding an API that would give us the historical price of a given security at a particular time. The IEX API has a particularly limiting free option that makes rigorous data analysis comparing GS forecasting to actual market movement difficult, so we instead focused this portion of the project on comparing GS forecasting to other possible methods.
Cleaning data was a recurring challenge, as well. Initially, we spent a good amount of time working with the Marquee API to get the GSID to map to a ticker symbol and a company name. Ultimately, we were able to create a large local CSV file with all of the API data, so we can adopt any of our scripts to be fully local if API calls fail.

Log in or sign up for Devpost to join the conversation.