-
-
UI in dark mode
-
UI in dark mode
-
UI in dark mode
-

UI in light mode
-

UI in light mode
-

UI in dark mode
-
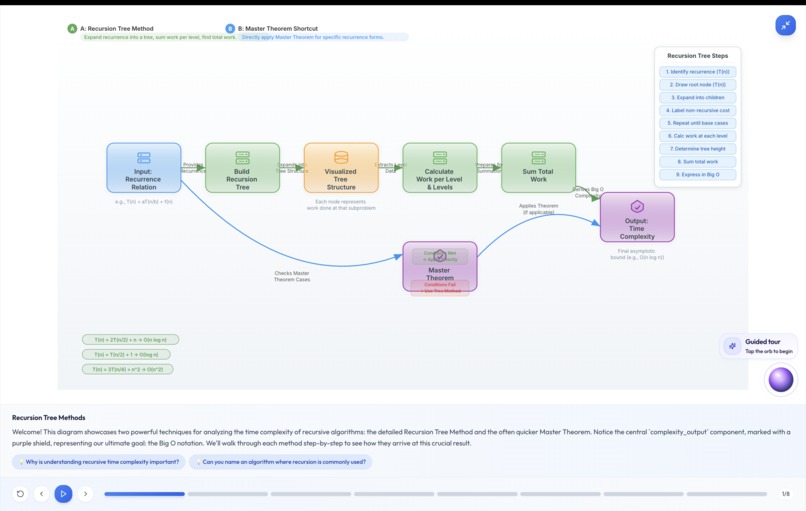
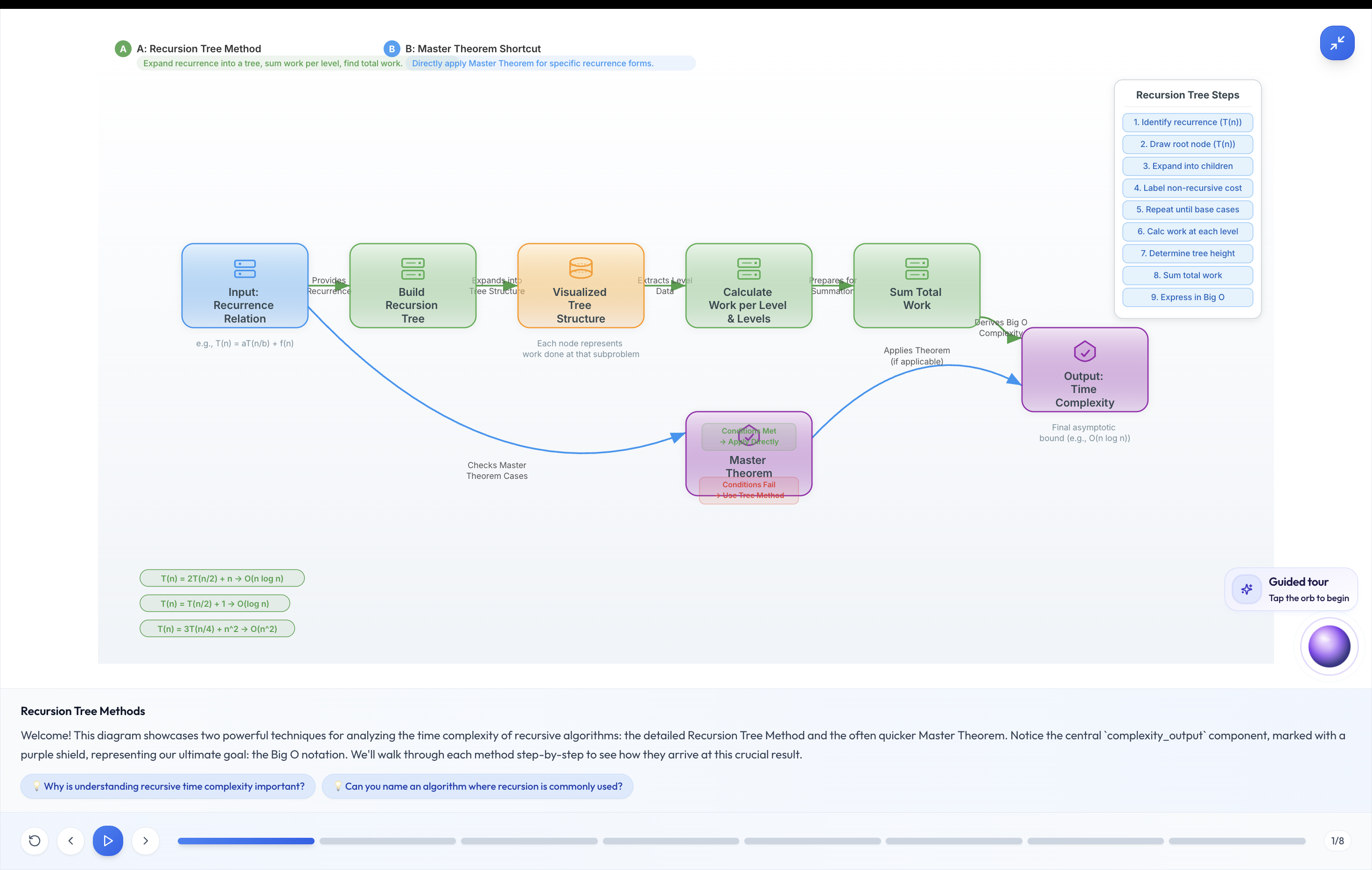
diagrams generated by Nano_banana



Inspiration
As a teacher for a Compilers and Languages course, I watched students struggle to grasp abstract data flows from static 2D slides. I realized that traditional "passive learning"—reading dense PDFs or watching fixed videos—acts as a barrier, especially for neurodivergent learners or those without access to elite mentorship. We were inspired to turn "knowledge as a privilege" into "knowledge as a right" by building an interactive playground that lets students talk to diagrams and see concepts move in real-time.
What it does
Visual CS is a multimodal educational platform that transforms static technical documents and research papers into interactive, animated lessons. Users can upload a PDF and immediately engage with: Conversational Diagrams: Powered by Gemini Live, allowing students to ask real-time questions about architectural flows (like Rate Limiters or Lexers). Dynamic Animations: Custom 24-second videos generated by Veo that visualize complex, moving concepts that static images can't capture. Immersive Audio: Lyria-generated study beats that provide a focused, high-fidelity auditory environment for learning.
How we built it
Our architecture is a complex multimodal pipeline. We use Gemini 1.5 Pro to parse dense documents and generate structured lesson scripts. These scripts are then fed into a parallel processing backend: Visuals: We engineered a custom "chunking" logic to bypass the 8-second video limit of Veo, generating multiple segments and concatenating them into a seamless 24-second lesson. Interaction: We integrated the Gemini Live API to provide a voice-synced, real-time feedback loop between the user and the generated diagrams. Audio: Lyria was utilized to create background scores and narrations that align with the visual transitions, all rendered together as an MP4 for the end user.
Challenges we ran into
The biggest technical hurdle was the "8-Second Barrier" with Veo. Creating a meaningful CS lesson in 8 seconds is nearly impossible. We had to build a backend system that could take a long script, break it into logical "visual chunks," ensure the style remained consistent across all generations, and then programmatically stitch them together with synchronized audio. We also faced significant latency challenges when trying to keep the "talking diagram" responsive while the model processed complex PDF context.
Accomplishments that we're proud of
We are incredibly proud of successfully concatenating multiple AI-generated components into a single, cohesive user experience. Moving from a raw research paper to a fully rendered 24-second animation with a live-interactive tutor in under a minute felt like magic. Additionally, achieving this level of multimodal integration—Gemini, Veo, and Lyria working in harmony—within the hackathon timeframe was a massive win for our team.
What we learned
We learned that the future of education isn't just about "better content," but about active interaction. Building this project taught us how to manage complex state transitions in LLM backends and the nuances of multimodal prompt engineering. We also discovered how powerful "scaffolding" can be—taking a concept that feels like a "black box" and peeling back the layers through animation and conversation.
What's next for VisualCS
Our next step is focused on Global Accessibility. We plan to implement multilingual support so that a student can upload a paper in English and have it explained to them in their native tongue via Gemini Live. We also aim to develop a "low-bandwidth" mode that exports these interactive lessons into lightweight, offline formats to ensure that students in digital-poor environments aren't left behind.
Built With
- css
- docker
- fastapi
- ffmpeg
- google-cloud
- google-gemini-api
- google-lyria
- google-oauth
- google-veo
- html
- next.js
- pnpm
- postgresql
- pydantic
- python
- radix-ui
- react
- redis
- sql
- sqlalchemy
- tailwind-css
- typescript
- zod
- zustand

Log in or sign up for Devpost to join the conversation.