
Visual Speech To Text
Visual speech recognition, also known as lip-reading, relies on lip movements to recognise speech without relying on the audio stream. This is particularly useful in noisy environments where the audio signal is corrupted; Automatic lip reading aims to recognise the speech content by watching videos. It has lots of potential applications in both noisy and silent environments. This model is based on latest paper on Lip reading to text but we tried
- Squeeze and Excitation attention model
- TimeSFormer
and tried to increase accuracy from current accuracy of 86.5 in visual model.This system can work on both visual only ,audio only or both independetly according to your choice.
 |
 |
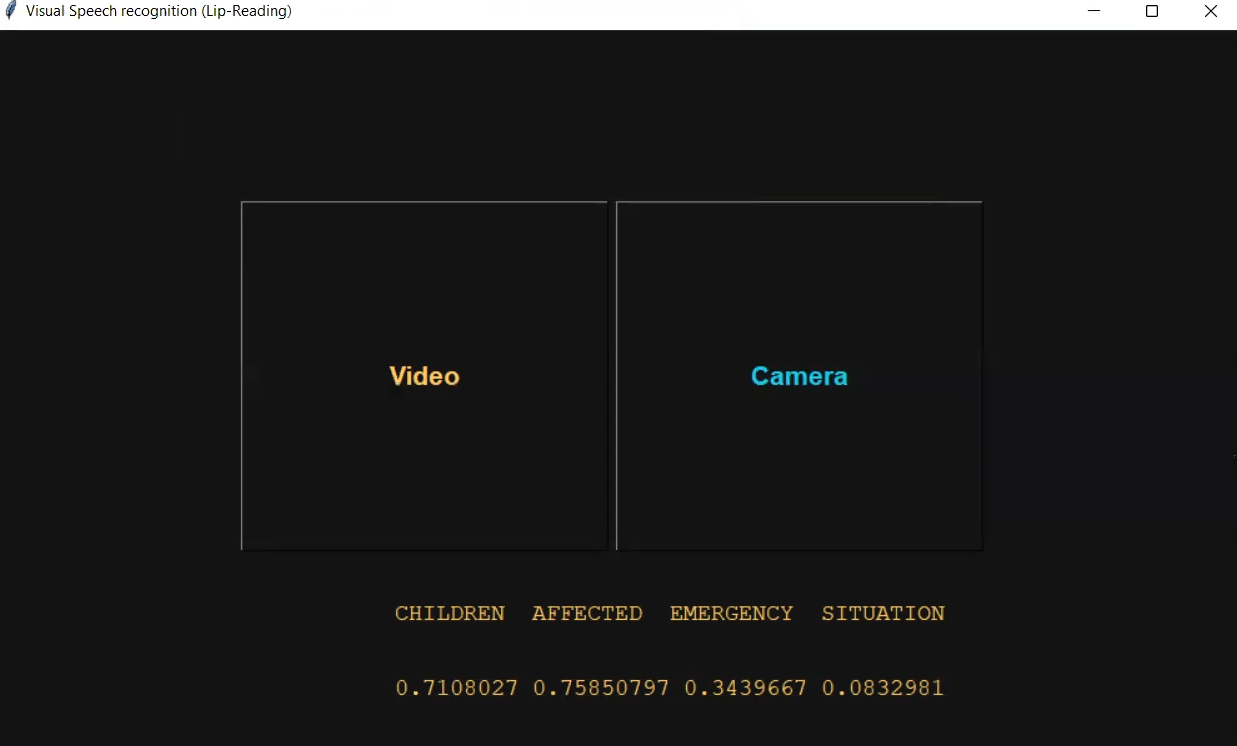
| 0. Input Image(mp4 or Live Camera) | 1. Output |
What it does
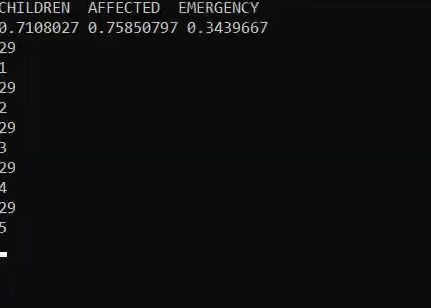
This is a system which predicts what a person is saying on the basis of lip movement of the person, in case of non-noisy environment it can also predict from only audio module or to increase accuracy you can use both (lip only + audio only independently) through which one can get an idea what a person is saying.
Inspiration
In this world which is full of noise, song, speeches, slogans there are few who can't listen to these and this is my small contribution which can make their life easier so that they can easily communicate in this world.
How we built it
This system is build in 2 parts
1. Preprocessing
We took all the video and preprocess in 4 steps given below all the videos are from Dataset - LRW which has more than 500,000 video to divided in train, test and validation which sum up to 500 words of various speakers and after completing these 4 steps each video it converted into npz file which of NumPy arrays to make computation faster which was done before as it took nearly a week to accomplish:-
 |  |  |  |
| 0. Original | 1. Detection | 2. Transformation | 3. Mouth ROIs |
2. Training
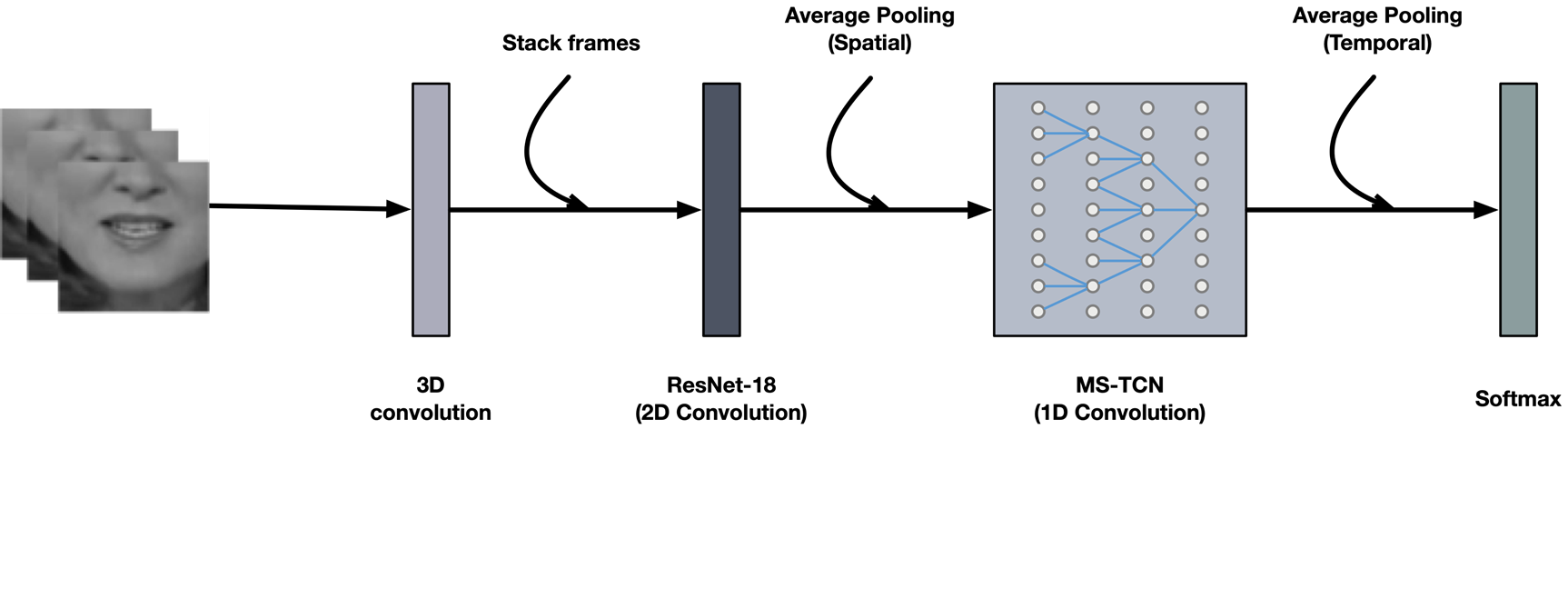
To train this model we use articture model where all videos are passed from 3D-CNN after 3DCNN we tried attention model of squeeze and excitation , TimeSFormer to increase accuracy where afterwords it passed into 18 layers of resnet and before passing it to soft max we pushed it to TCN.

How to get model
Download file from this link and place in training folder - Google Drive
How to install environment
- Clone the repository into a directory
git clone --recursive https://github.com/chiragarora01/visual-speech-to-text.git
- Install all required packages.
pip install -r requirements.txt
How to Run
To run this script, you must have CUDA + CuDnn installed with minimum of 8Gb Ram and a GPU
CUDA_VISIBLE_DEVICES=0 python main.py
Accomplishments that we're proud of
- It takes video input, place landmarks on it and predict what it is saying
- It can do this same by live feed.
- Code also consist model which can be used as only audio module
What's next for Visual Speech to Text
To make it a commercially viable product we need to make some sort of IOT device or to make a system where it takes feed from one's device, pass it to cloud, do computation there and return the desired output as this software need high computation power


Log in or sign up for Devpost to join the conversation.