-
StreamSync
-
VisionSync
-
Home
Inspiration
The inception of VisionVoice was driven by the aspiration to bridge the accessibility gap in the digital world for the visually impaired. Recognizing the deep impact of visual content in our daily lives from entertainment to social interactions and navigation we sought to create an inclusive tool that translates visual experiences into auditory and textual formats. This initiative was inspired by the potential to empower visually impaired individuals to independently explore, learn, and interact with their surroundings, enhancing their quality of life and fostering inclusivity.
What it does
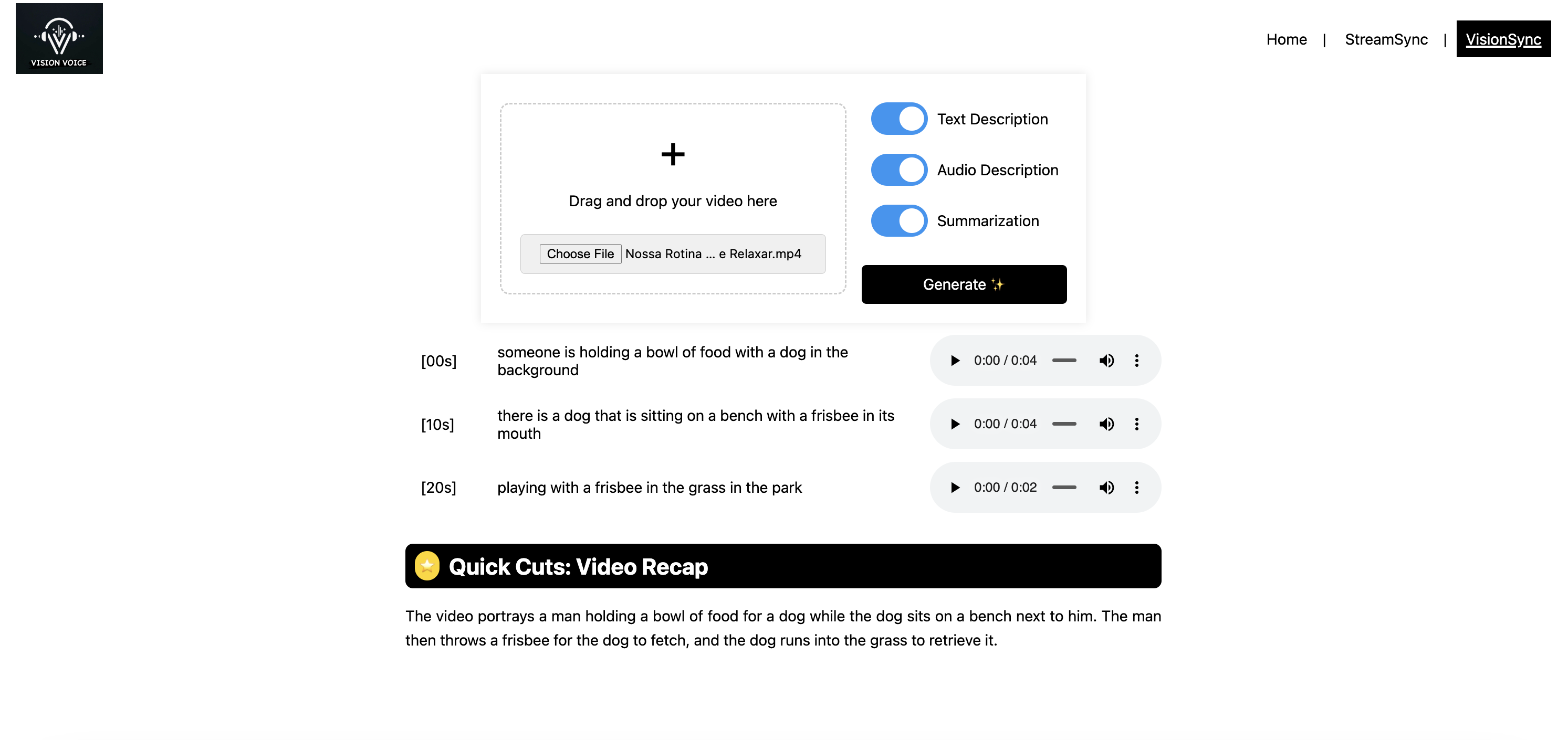
VisionVoice transforms videos into accessible formats by extracting still images at intervals and converting these visuals into audio or text descriptions. Users can choose between detailed text descriptions, synthesized audio narratives, or summarized text content for preloaded videos. The system uses AI models including Salesforce's BLIP (Bridging Language and Image Processing) for image understanding and Microsoft's T5 text-to-speech conversion, to provide rich, context-aware descriptions of scenes, actions, and events captured in the video frames. It also uses Google's Gemini 1.0 Pro model to summarize the texts.
How we built it
We used a combination of state-of-the-art (SOTA) AI models to develop VisionVoice. The process begins with sampling videos into still frames using OpenCV, followed by using Salesforce's BLIP (Bridging Language and Image Processing) model to interpret the visual content and generate descriptive text. For users preferring audio, we convert the text descriptions into speech using Microsoft's T5 text-to-speech model. For preloaded videos, Google's Gemini 1.0 Pro model is used to summarize the textual descriptions, providing concise overviews of the video content. Our development journey involved integrating these diverse technologies into a seamless workflow, user-friendly interfaces and customizable options for individual needs. On the frontend we utilized the Angular framework while our backend infrastructure is built on Python, FastAPI, and Huggingface technologies.
Challenges we ran into
Optimizing the system for low-latency performance without compromising the quality of the descriptions was a challenge for live camera feeds. That's why we ended up hosting the audio files and then doing the live stream. It was our first time working with python’s FastAPI so there was a learning curve for that. The difficult part was to integrate the backend and frontend but we managed to do it. The prompt selection for summarization for Google's Gemini model was also a challenge for us since LLMs(Large Language Models) are non-deterministic. Therefore, we had to use prompt engineering strategies to work around this issue.
Accomplishments that we're proud of
We are proud of VisionVoice's ability to provide nuanced and context-rich descriptions that go beyond mere transcription or object detection, offering visually impaired users a more immersive understanding of their surrounding environment. The successful integration of advanced AI models to interpret and narrate visual content is a testament to the innovation of our team.
What we learned
Throughout the development of VisionVoice, we gained valuable insights into the complexities of visual perception and translating visual cues into descriptive language. We learned the importance of user-centric design, especially in creating accessible technologies and the need for continuous testing and iteration to refine the user experience.
What's next for VisionVoice
Looking ahead, we aim to expand VisionVoice's capabilities to include real-time language translation, making it accessible to a global audience. We plan to use the BLIP-2 model and then set the random sampling rate to 0.1 seconds compared to the 10 seconds that we have right now. Then we take an image encoder, similar to CLIP's (Contrastive Language–Image Pre-training) image encoder because it already represents images in a joint text-image embedding. And then we can perform a dot product under normalization of the encoded image. Thus, our approach involves calculating the cosine similarity and comparing it against a predetermined threshold. For example: If the image encodings are less than 60% similar then we re-describe the frame. All of these integrations will help our service be integrated into hardwares like Meta glasses, Meta quest or Apple Vision Pro to analyze surrounding environments in real-time.
Built With
- angular.js
- blip
- cloudflare
- fastapi
- gemini
- huggingface
- python
- t5-tts
- torch
- transformers

Log in or sign up for Devpost to join the conversation.