-
main page
-
similarities detection from memory
-
using search to find lost object
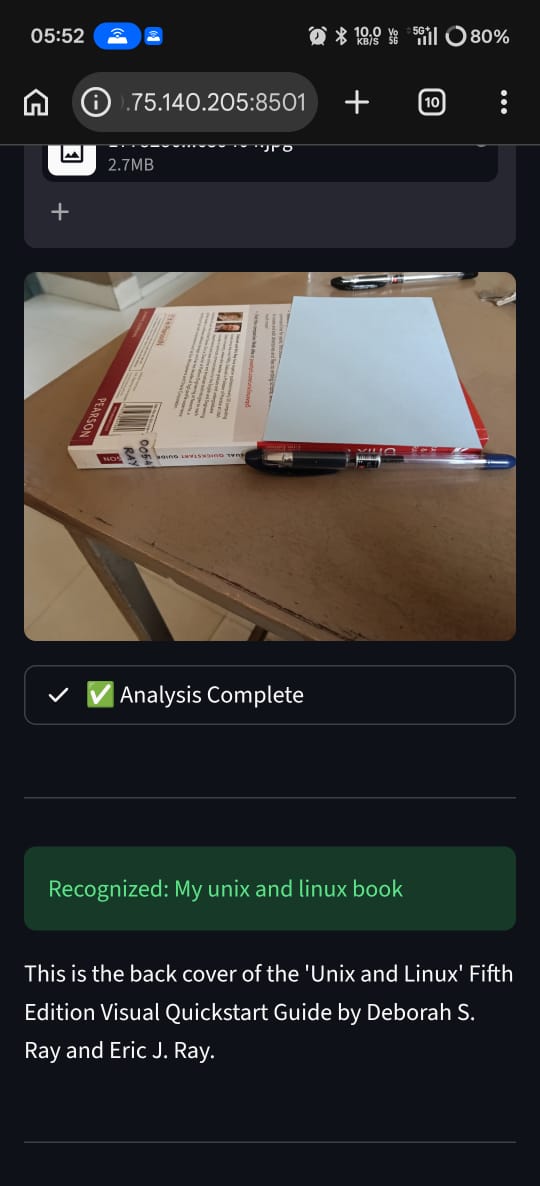
Inspiration
We waste time every day searching for things we just put down. Keys, IDs, promotional cards, wallets. It's not because we're careless; it's because human memory is unstructured and volatile. We realized a strange paradox: we carry high-powered cameras everywhere, yet we have no searchable memory for the physical world.
We asked ourselves: "What if reality itself became searchable?" VisionVault was born to reduce the friction between seeing an object and remembering where it is, acting as an external, structured memory drive for the real world.
What it does
VisionVault is an AI-powered personal memory assistant. It operates on a simple three-step pipeline:
- Capture: You snap a photo of an object you want to remember.
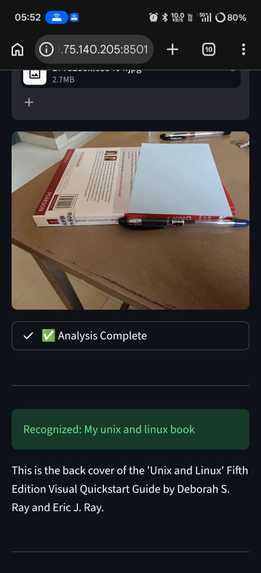
- Store: The system analyzes the image and extracts the primary object. It ignores the noise and saves a structured memory to a local vault.
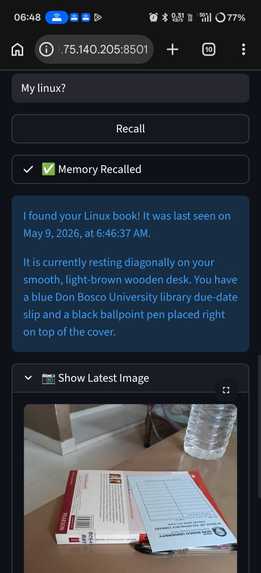
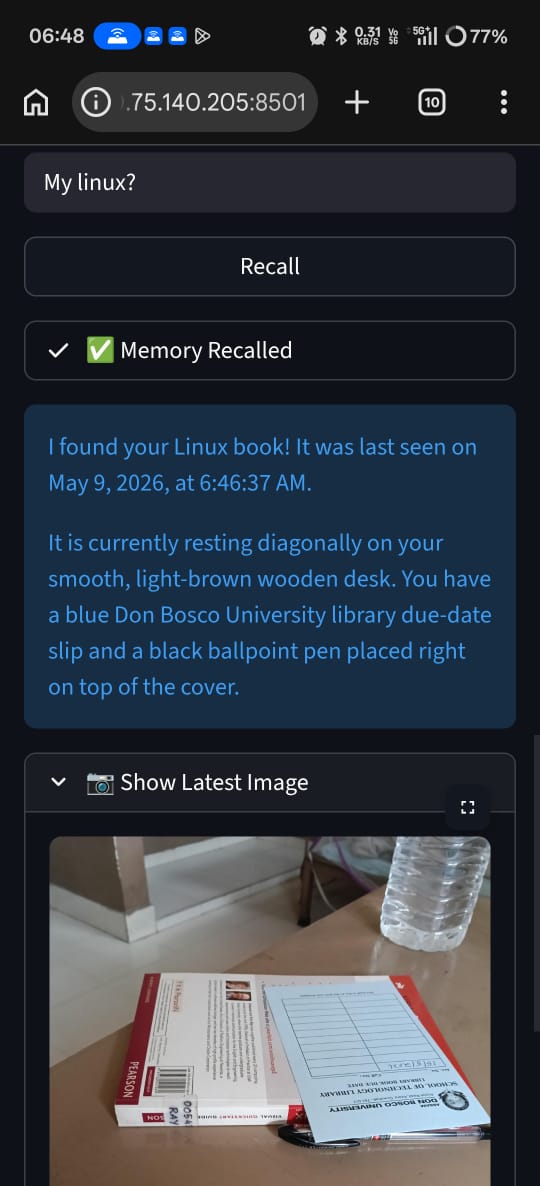
- Recall: Later, you can ask, "Where did I leave my keys?" The system queries your vault and tells you exactly where they were last seen, along with the timestamp.
How we built it
We built the frontend interface using Streamlit, optimizing it with custom CSS to feel like a native mobile app. The core backend logic is written in Python.
For our reasoning engine, we heavily integrated the Google Gemini API (gemini-3.1-flash-lite). We didn't just use Gemini as an image classifier—we used it for spatial reasoning. We engineered strict prompts forcing Gemini to output deterministic JSON. When it analyzes an image, it silently generates two crucial background data points:
secret_forensics: Micro-details like scratches, QR codes, or brand text.secret_location: The spatial relationship of the object (e.g., "sitting on a wooden desk between a water bottle and a laptop").
We also built a custom scoring algorithm for the search function that weighs exact label matches against semantic overlaps in the forensic data, ensuring accurate recall even if the user's memory is fuzzy.
Challenges we ran into
The biggest challenge was LLM hallucination and background clutter. If you take a picture of a wallet on a messy desk, standard AI models try to label everything in the frame. We had to treat the AI prompt like strict system architecture—writing absolute prohibitions into the instructions to force Gemini to isolate the single, primary subject in the center of the frame and relegate the background strictly to the location data field.
Additionally, we had to solve for local storage bloat. We wrote overwrite logic so if a user scans the same object twice, the system safely deletes the old image file and updates the JSON memory block, keeping the system incredibly lightweight and efficient.
Accomplishments that we're proud of
We are incredibly proud of successfully forcing an LLM to act as a deterministic, structured database generator. Moving from unstructured image pixels to highly specific, queryable JSON data in a matter of seconds feels like magic when you see it work live.
What we learned
We learned that the true power of multimodal APIs like Gemini isn't just in describing what an image is, but in extracting the context of where it exists in physical space. We also learned the immense value of strict prompt engineering to reign in generative models for precise, utility-driven applications.
What's next for VisionVault
Currently, VisionVault is an active memory tool—you have to consciously take a photo. The next evolution is making it a completely passive memory layer. By integrating this logic with AR glasses or wearable cameras, the system could continuously buffer and structure your physical surroundings in the background. You'll never lose something you've already seen again.


Log in or sign up for Devpost to join the conversation.