-
-
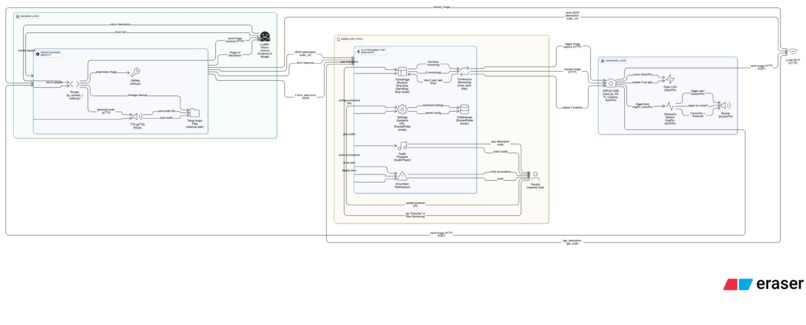
data flow diagram
-
-

-

-

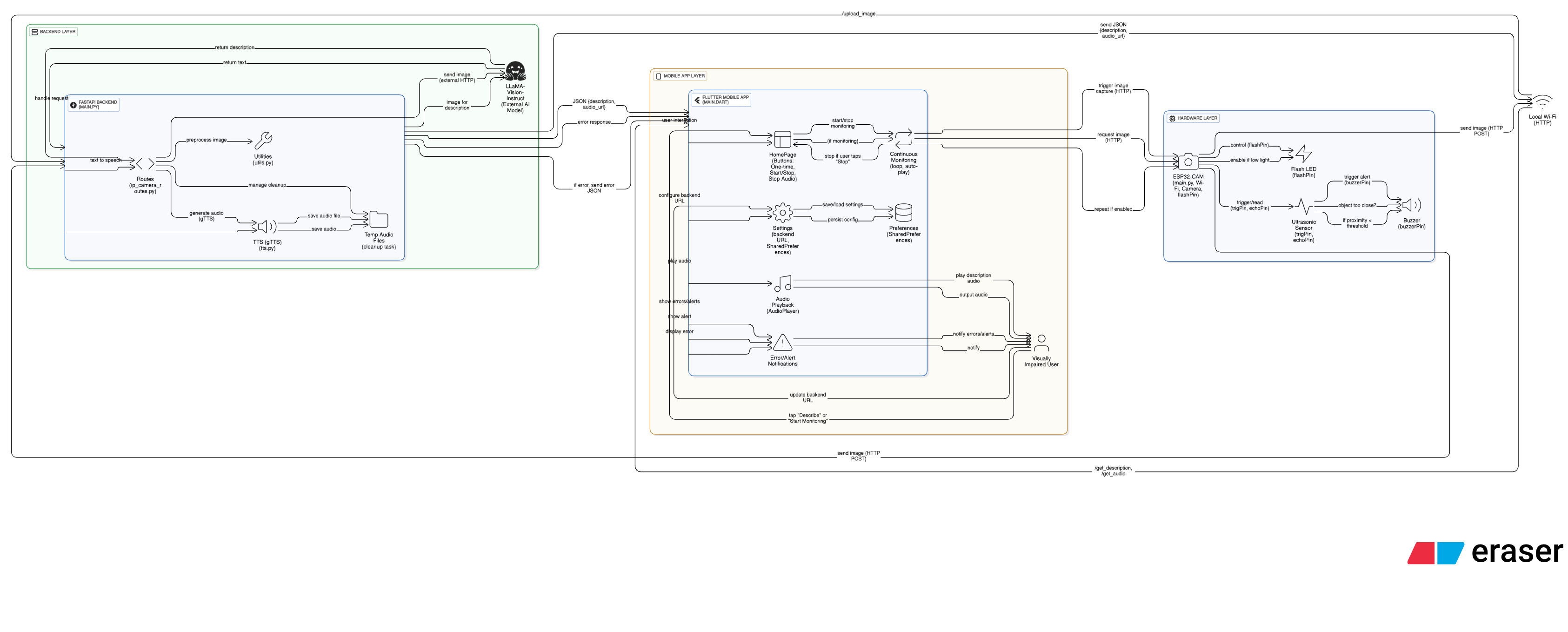


VisionMaxing
About the Project
VisionMaxing is an innovative assistive technology designed to empower partially blind and visually impaired individuals, enabling them to navigate their environments safely and independently. By combining IoT hardware, AI-driven image recognition, and a mobile interface, VisionMaxing transforms the way people perceive and interact with the world.
This system captures images of a user’s surroundings using a compact ESP32-CAM, processes these images with an AI-powered FastAPI backend using Hugging Face LLaMA-Vision-Instruct, and delivers real-time audio descriptions through a Flutter mobile application. Optional ultrasonic sensors and buzzer alerts further enhance situational awareness by warning users of nearby obstacles, ensuring safety and independence in any environment.
📺 Demo Video: Watch on YouTube
💻 Source Code: GitHub Repository
Inspiration
The inspiration for VisionMaxing comes from the pressing social challenge of urban accessibility. Millions of partially blind individuals navigate daily life with uncertainty, relying on canes, guide dogs, or pre-recorded audio tools. Yet, these solutions are either inadequate, expensive, or unable to adapt in real-time to dynamic urban environments.
I envisioned a smart, low-cost, and real-time solution that would bridge the gap between disability and independence. In the context of modern smart cities, where technology can enhance urban living, VisionMaxing provides real-time awareness, allowing visually impaired citizens to safely navigate streets, public transport, parks, and educational or commercial spaces.
This project is not just technical—it is socially transformative, giving individuals the dignity of autonomy, reducing dependency, and fostering inclusion in the rapidly evolving urban landscape.
What I Learned
VisionMaxing was a journey of technical mastery and human empathy. Some key takeaways include:
- Hardware & Embedded Systems: Integration of ESP32-CAM, ultrasonic sensors, and buzzers for real-time environmental sensing.
- AI & NLP: Fine-tuning prompts for LLaMA-Vision-Instruct to generate accurate, concise, and user-friendly scene descriptions.
- Backend Development: Using FastAPI for handling image data, AI requests, and generating audio responses in real-time.
- Mobile App Development: Building a Flutter application that is intuitive, responsive, and accessible, with continuous monitoring, audio playback, and settings management.
- System Architecture: Orchestrating a multi-component system where hardware, AI backend, and mobile app communicate seamlessly over Wi-Fi networks.
- Social and Emotional Awareness: Understanding the challenges visually impaired users face, shaping technical decisions to maximize usability, safety, and empowerment.
How I Built It
The system is modular and scalable, consisting of three core components:
1. Hardware Layer – ESP32-CAM
- Captures images at multiple resolutions (
lo,mid,hi) depending on network and lighting conditions. - Optional ultrasonic sensor detects obstacles and triggers buzzer alerts for immediate feedback.
- Streams images to the backend over Wi-Fi.
Distance calculation formula:
$$ \text{Distance (cm)} = \frac{\text{Pulse duration (μs)} \times 0.034}{2} $$
Code snippet:
float getDistance() {
digitalWrite(trigPin, LOW);
delayMicroseconds(2);
digitalWrite(trigPin, HIGH);
delayMicroseconds(10);
digitalWrite(trigPin, LOW);
long duration = pulseIn(echoPin, HIGH);
return duration * 0.034 / 2; // distance in cm
}
2. Backend Layer – FastAPI + AI
- Receives images via HTTP endpoints.
- Processes images using LLaMA-Vision-Instruct to produce contextual, user-friendly textual descriptions.
- Converts descriptions into audio using gTTS, providing immediate feedback.
- Manages continuous requests efficiently to ensure low-latency real-time performance.
File structure example:
backend/
├─ main.py
├─ ip_camera_routes.py
├─ tts_utils.py
├─ requirements.txt
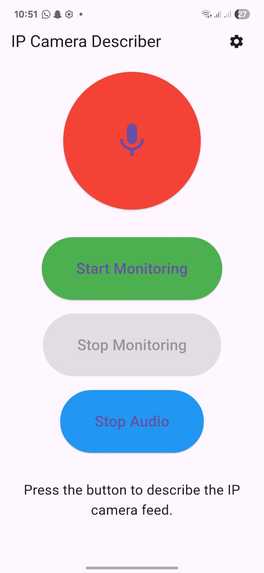
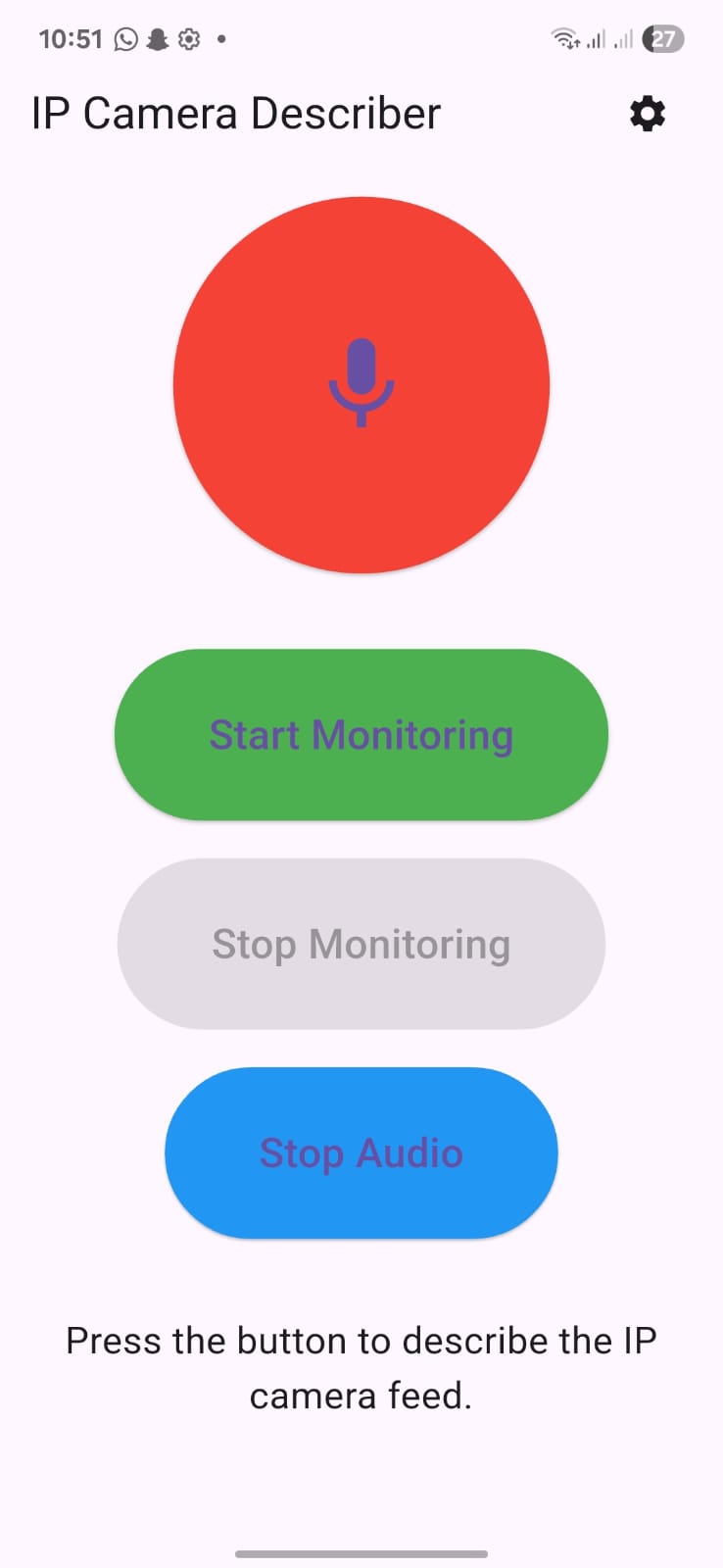
3. Mobile Layer – Flutter App
- Intuitive interface with one-time description, continuous monitoring, and audio control buttons.
- Plays audio feedback in real-time, supports start/stop monitoring.
- Stores backend URL using SharedPreferences for easy configuration.
- Designed with accessibility in mind, including large buttons, clear labels, and minimal visual clutter.
File structure example:
mobile_app/
├─ lib/
│ └─ main.dart
├─ pubspec.yaml
Challenges Faced
- Real-Time Performance: Ensuring low-latency feedback across hardware, backend, and mobile app.
- Network Reliability: Managing intermittent Wi-Fi and data packet loss.
- Prompt Engineering: Crafting AI prompts that produce concise, clear, and contextually relevant descriptions for partially blind users.
- Hardware Constraints: Memory and processing limitations of ESP32-CAM.
- Continuous Monitoring: Synchronizing repeated audio descriptions without overlap or lag.
Each challenge required iterative testing and optimization, balancing accuracy, speed, and usability.
🌍 Smart City Relevance
VisionMaxing is not just an assistive device—it is a Smart City enabler.
✔️ Improves independent mobility for visually impaired citizens
✔️ Integrates with smart traffic lights, transport APIs, and mapping systems
✔️ Scales to community-wide accessibility services (elderly, disaster management)
✔️ Aligns with universal design standards for inclusive infrastructure
By ensuring safety, dignity, and independence, VisionMaxing directly contributes to inclusive Smart Cities of the future.
🚀 Hackathon Track Alignment
- Smart Cities & Infrastructure 🏙️
- IoT + AI Track ⚡
- Vision & Media Track 👁️
- Civic UX Track ♿
Multimodal AI Integration
- Vision (ESP32-CAM + LLaMA-Vision)
- Language (Scene narration)
- Audio (Text-to-Speech real-time feedback)
📈 Key Learnings
- Embedded Systems: ESP32-CAM programming & image streaming
- AI & NLP: Prompt engineering for concise scene descriptions
- Backend Orchestration: FastAPI APIs for low-latency AI + TTS processing
- Mobile Development: Accessibility-first Flutter UI design
- Human-Centered Design: Technology built with empathy for end-users
🔮 Future Improvements
- Face & Text Recognition → Identify people and landmarks
- Offline AI Models → Run on-device without internet dependency
- Voice Command Support → Hands-free control
- Multi-language Audio → Inclusive for global populations
- Smart City Integration → Connect with public IoT infrastructure for dynamic guidance
🏆 Impact
VisionMaxing demonstrates how affordable AI + IoT can be applied for real social good, transforming urban accessibility and bridging the gap between disability and independence.
In the context of Gen AI Chakra Hackathon, this project embodies the Solarpunk vision of technology that:
- Works in harmony with people and cities
- Enhances human dignity and autonomy
- Builds inclusive, sustainable, and human-centered futures
Summary
VisionMaxing combines hardware, AI, and mobile technology to revolutionize accessibility for the visually impaired. It transforms ordinary environments into safe, understandable, and navigable spaces, empowering individuals and setting the stage for smarter, more inclusive cities.
This project is a testament to the potential of technology to create social good, demonstrating how affordable innovation can enhance independence, safety, and quality of life for millions of people.

Log in or sign up for Devpost to join the conversation.