Inspiration
The way people interact with computers has not fundamentally changed for decades. Even with modern AI assistants, users still have to manually navigate websites, click buttons, fill forms, and search for information themselves.
We were inspired by a simple question: What if AI could actually use software instead of just talking about it?
Recent advances in multimodal AI models, especially Gemini’s ability to understand images, video, and text together, opened the door to a new type of system: an AI agent that can see a screen, understand the interface, and perform tasks like a human user.
VisionFlow AI was created to explore this future where AI becomes an active digital assistant that can interact with real applications and websites on behalf of the user.
What it does
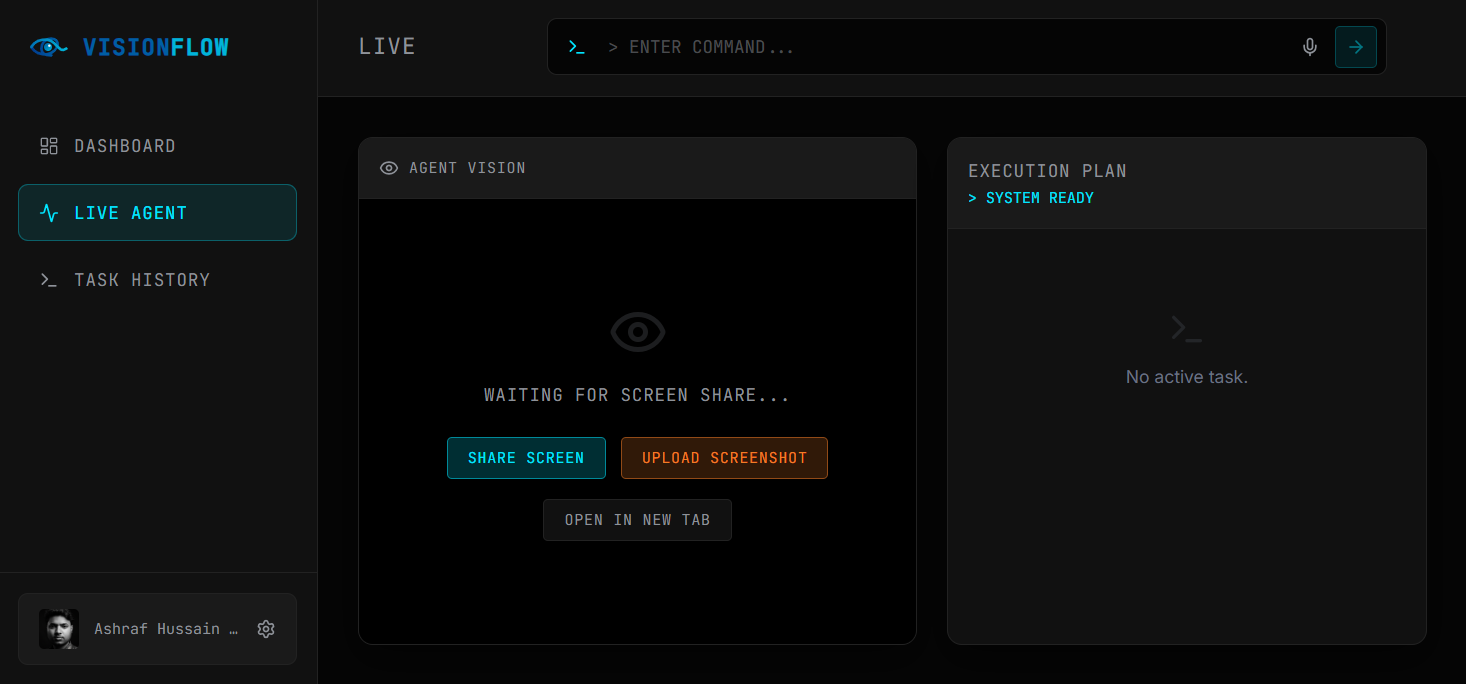
VisionFlow AI is a multimodal AI agent that understands and navigates user interfaces automatically.
Users simply give a natural language command such as: “Find the best laptop under ₹80,000 on Amazon.”
The system then:
- Captures the screen or webpage
- Uses Gemini’s multimodal vision capabilities to interpret the UI
- Identifies important elements such as buttons, search bars, and menus
- Breaks the user’s request into actionable steps
- Executes actions like clicking, typing, scrolling, and filtering
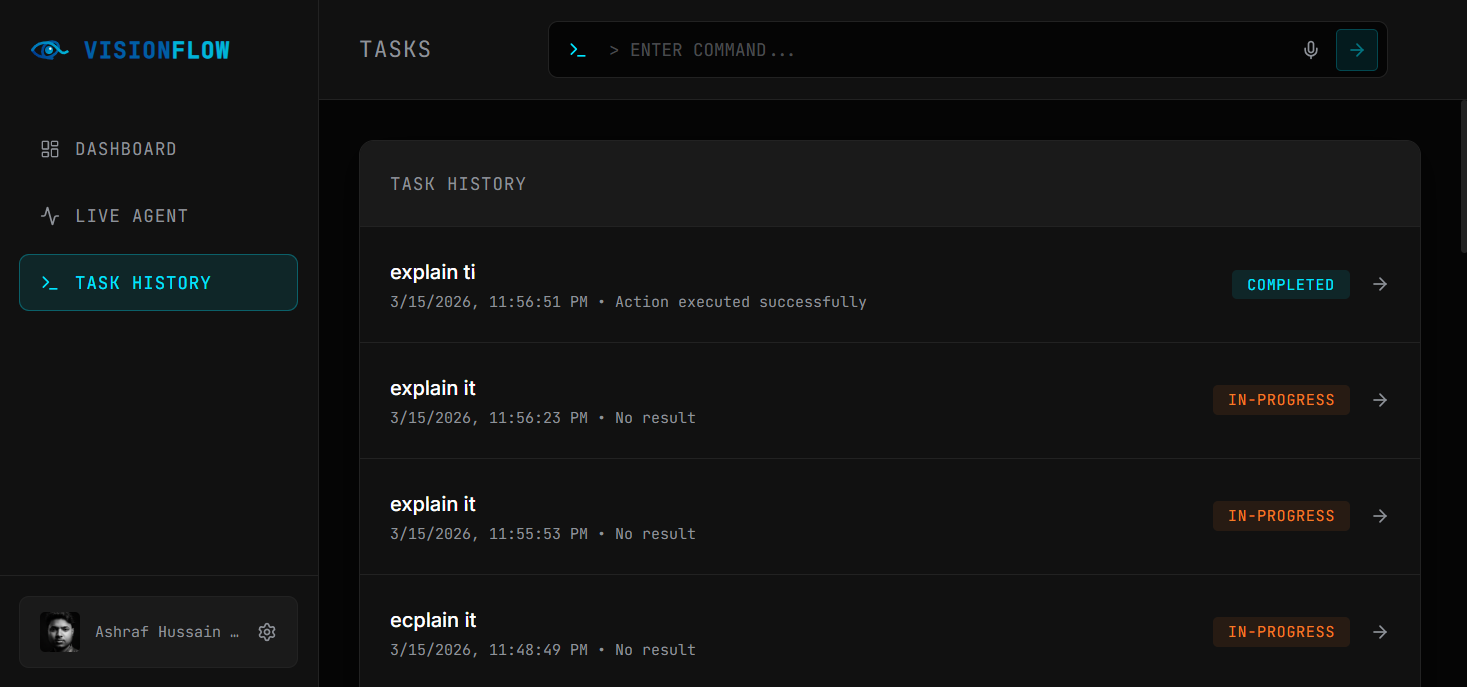
- Returns the results to the user with explanations Instead of manually performing repetitive tasks online, users can delegate them to the AI agent. This creates a powerful new interaction model where AI becomes the user's hands on the internet.
How we built it
VisionFlow AI was designed as a multimodal agent system running on Google Cloud. The system consists of several components working together:
Frontend Built with Next.js and React Provides a conversational interface where users can give commands Displays live task progress and results
AI Agent Backend Built using Node.js Handles user commands and coordinates the AI workflow Gemini Multimodal Intelligence Gemini models process screenshots and understand UI elements The model generates reasoning steps and suggested actions
Task Planning Engine Breaks high-level instructions into smaller steps Creates a structured action plan Automation Layer Implemented using Playwright Executes actions such as clicks, typing, and scrolling Google Cloud Infrastructure
The system runs entirely on Google Cloud using: Vertex AI for Gemini model access Cloud Run for scalable backend deployment Firestore for session and task storage Cloud Storage for screenshots and logs This architecture allows the AI agent to observe, reason, and act in real time.
Challenges we ran into
Building an AI system that can interact with real interfaces introduced several challenges.
UI Interpretation
Web interfaces are highly variable. Buttons, forms, and layouts differ across websites, which made it difficult to reliably detect actionable elements.
Action Planning
Turning a natural language instruction into a structured set of actions required careful prompt engineering and agent design.
Multimodal Latency
Processing screenshots with AI models while maintaining real-time responsiveness required optimizing the workflow and reducing unnecessary requests.
Automation Reliability
Automating browser interactions across different layouts and dynamic pages required building robust error handling and retry mechanisms. These challenges pushed us to design a more modular and resilient agent architecture.
Accomplishments that we're proud of
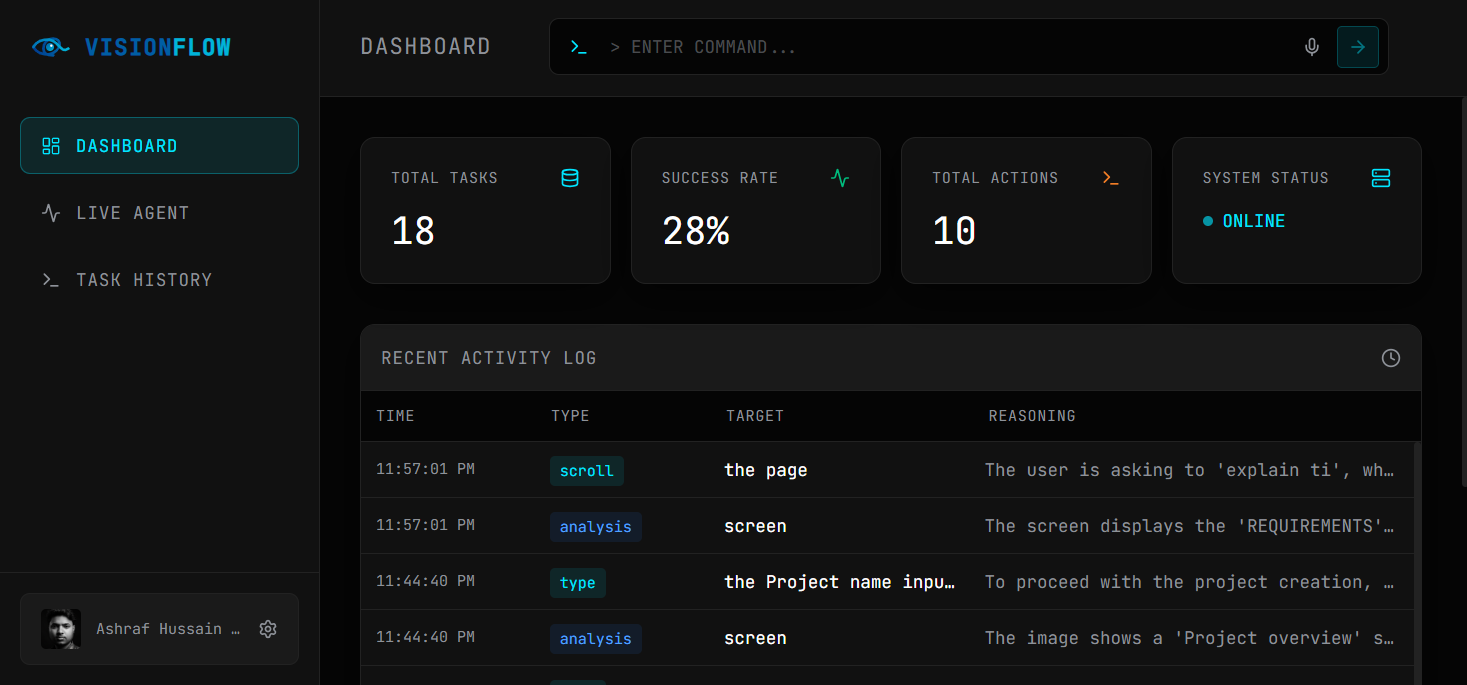
One of our biggest achievements was successfully building a fully functional multimodal AI agent that can observe and interact with real user interfaces.
We are proud that VisionFlow AI demonstrates: Real vision-based UI understanding Autonomous task planning Real-time web automation Seamless integration with Google Cloud and Gemini models
Most importantly, the system shows how AI can move beyond chatbots to become active digital collaborators.
What we learned
This project gave us valuable experience in several emerging areas of AI engineering:
- Designing multimodal AI agent systems
- Using Gemini models for visual reasoning
- Implementing autonomous task planning
- Integrating AI with browser automation tools
- Deploying scalable AI applications on Google Cloud We also learned that the future of AI assistants lies not just in conversation, but in action AI systems that can actually perform tasks in the digital world.
What's next for VisionFlow
VisionFlow AI is only the beginning. There are many exciting directions for future development.
Smarter Agents
Adding multi-agent collaboration where specialized agents handle planning, reasoning, and execution.
Cross-Application Automation
Extending the system to control not just browsers but also desktop applications and productivity tools.
Personal AI Workflows
Allowing users to create custom automation pipelines for daily tasks.
Learning from Users
Enabling the agent to learn workflows by observing user behavior. Our long-term vision is to build an intelligent AI assistant that can seamlessly operate across the entire digital ecosystem, making human-computer interaction faster, simpler, and more intuitive. VisionFlow AI is a step toward that future.


Log in or sign up for Devpost to join the conversation.