-
-
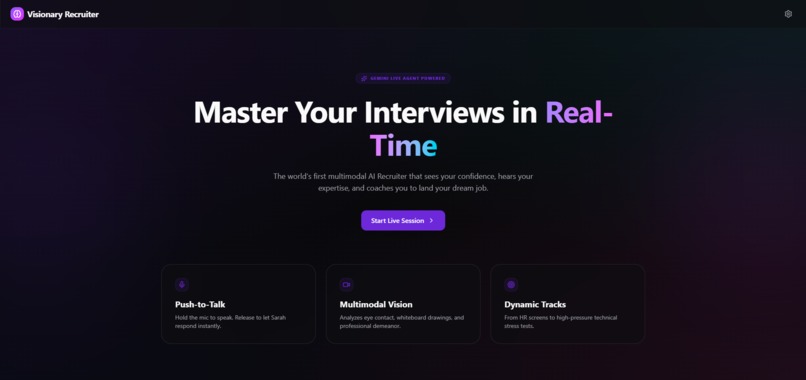
MainPage
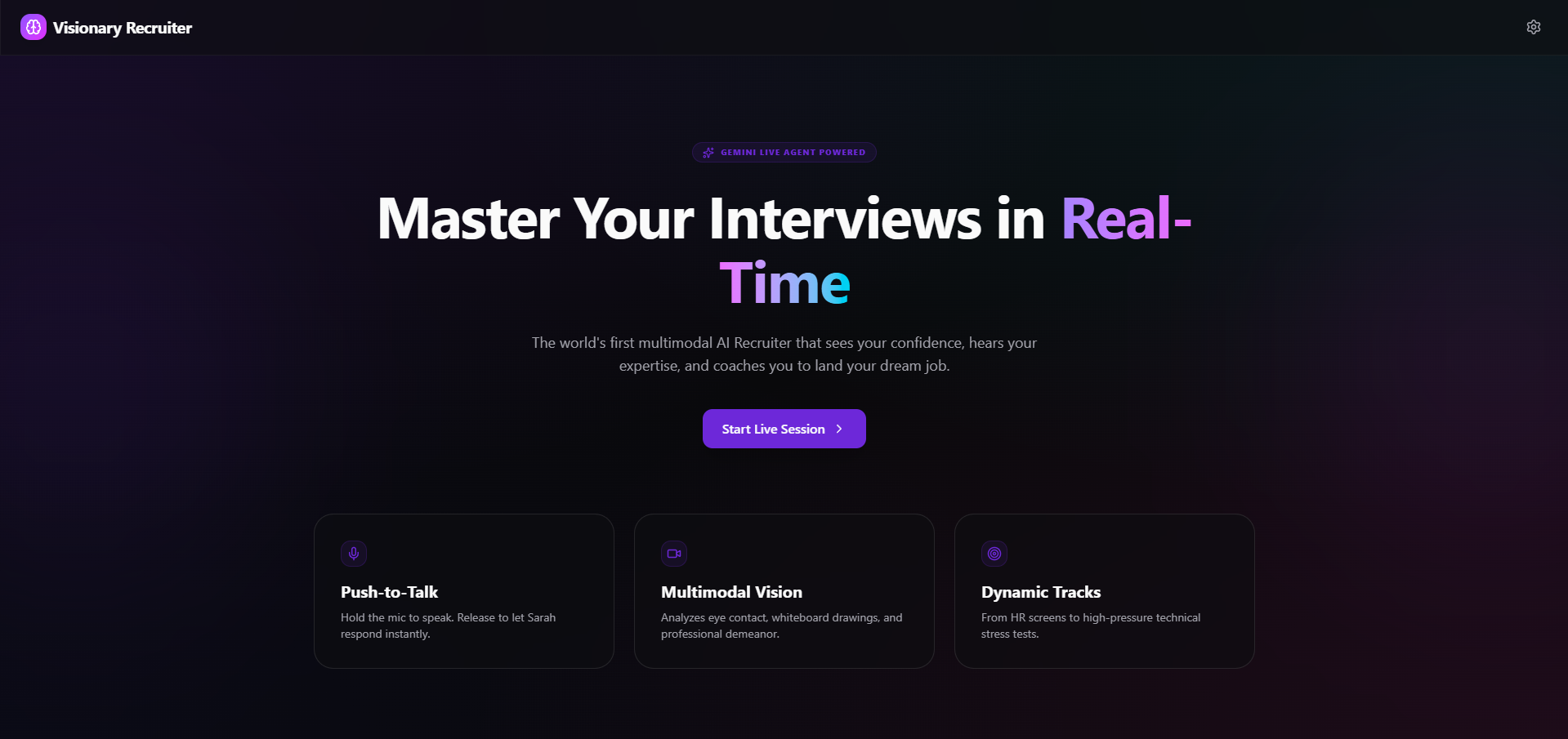
Visionary Recruiter
The Next-Generation Multimodal AI Interview Coach
Inspiration
Technical interviews are notoriously broken.
For years, candidates have prepared using static text boxes, **LeetCode grinders, and non-interactive video rubrics. But real interviews aren’t just about the code you write; they are about how you communicate under pressure, how you maintain your composure, and how you articulate the "why" behind your decisions.
We were inspired to build Visionary Recruiter when we saw the capabilities of the Gemini Multimodal Live API.
For the first time, we realized we could create an AI that doesn't just read your answers—it actually hears the hesitation in your voice, sees your body language through the webcam, and interrupts you when you ramble.
We wanted to build a high-fidelity emotional and technical simulation that genuinely prepares people for the intensity of elite tech interviews.
What it does
Visionary Recruiter is a real-time, multimodal AI interview coach.
It acts as a realistic "Senior Recruiter" named Sarah, interacting through a sub-second latency WebSocket connection.
The system evaluates both technical thinking and human communication signals.
Contextual Intelligence
You upload your exact resume, and the AI dynamically generates its first question based on your actual past experience.
Multimodal Evaluation
Using your webcam, it tracks:
- Body language
- Posture
If you enter the Technical Dive track, you can literally draw a system architecture diagram on a piece of paper, hold it up to the camera, and Gemini will visually grade your design logic.
Live Telemetry & STAR Analysis
As you speak, the AI constantly executes Function Calls: update_interview_metrics()
Your answer is parsed through the STAR framework:
[ STAR = Situation + Task + Action + Result ]
The system updates a live dashboard showing:
- Confidence score
- Articulation quality
- STAR completion progress
Reverse Q&A
I implemented a Wrap-Up phase where the AI prompts the user:
“Do you have any questions for me?”
This evaluates the candidate's insightfulness, mirroring real interviews.
How we built it
I architected Visionary Recruiter entirely on the edge to minimize latency and maximize the live interview feeling.
Frontend
I built a rich glassmorphism UI using:
- React
- Tailwind CSS
- Framer Motion
The product follows a 4-stage interview journey:
[ Landing \rightarrow Setup \rightarrow Live\ Room \rightarrow Debrief ]
Audio Pipeline
I leveraged the Web Audio API and created a custom AudioWorklet.
The system:
- Captures microphone input at 16kHz
- Applies an RMS-based Voice Activity Detection (VAD) noise gate
- Streams raw PCM audio instantly
The Brain
I established a bidirectional WebSocket connection to the Gemini 2.0 Flash Multimodal Live API.
I simultaneously stream:
- PCM audio data
- Base64 encoded webcam frames
This allows Gemini to see and hear the candidate in real time.
Tool Calling
I defined a strict JSON schema inside our function_declarations.
Gemini triggers these functions to update the UI instantly.
Example tool: update_interview_metrics()
This powers:
- STAR breakdown telemetry
- Confidence scoring
- Real-time interview analytics
Challenges we ran into
Audio Artifacts & Noise
Sending raw microphone data caused Gemini to hear its own voice echo, leading to hallucinations.
I solved this by building a Voice Activity Detection (VAD) system using Root Mean Square (RMS) calculations in JavaScript.
[ RMS = \sqrt{\frac{1}{N} \sum_{i=1}^{N} x_i^2} ]
Only audio chunks where the user is actively speaking are transmitted.
Function Calling Overload
If Gemini attempted to grade too many metrics simultaneously, the JSON tool calls sometimes clipped or formatted incorrectly.
I stabilized the system by:
- Enforcing strict JSON schemas
- Injecting a CRITICAL SYSTEM INSTRUCTION prioritizing tool execution structure
Multilingual Hallucinations
When users mumbled, the Live API occasionally attempted to respond in other languages.
I fixed this by hardcoding strict system prompts restricting processing and output strictly to English (US).
Accomplishments that we're proud of
- Successfully integrating concurrent multimodal streams (audio + visual evaluation of whiteboard drawings).
- Achieving sub-second latency, making the AI feel like a real impatient recruiter.
- Designing a futuristic telemetry dashboard that visualizes complex AI function calls like Live STAR breakdowns.
What we learned
Building Visionary Recruiter taught us the massive difference between REST APIs and bidirectional streaming AI systems.
State Management in Streams
Handling asynchronous toolCall responses mixed with audio streaming buffers in React without causing render thrashing required careful state design.
Prompt Engineering for Live Agents
Traditional prompting does not work well for live audio agents.
Instead, Live Agents require short and strict instructions, such as:
"Keep responses to 2–3 sentences max."
Otherwise the AI becomes too verbose and robotic.
What's next for Visionary Recruiter
Persistent Learner Profiles
Store user interviews in a database (e.g., Firebase) to track STAR improvement over 30 days.
More Tracks & Personas
Adding specialized interview tracks:
- Product Management
- Data Science
Each with different AI recruiter personalities and voices.
Video Export Summaries
Allow candidates to export a split-screen interview recording showing:
- The candidate
- The AI interviewer
- The real-time grading overlay
This can be shared with career counselors or mentors.
Built With
- framer-motion
- google-cloud-services-(firebase-hosting-/-cloud-run-for-deployment-proof)
- google-gemini-2.0-flash-(multimodal-live-api)
- lucide-react
- react
- tailwind-css
- typescript
- vite
- web-audio-api-(custom-audioworklets)


Log in or sign up for Devpost to join the conversation.