-
-

Visionary is a revolutionary mobile app that allows the visually impaired to better interact with their world.
-
Visionary provides easy to use, accessible controls in a simple and clean UI.
-

Users have the option to select an image from their camera roll or take a new image with their camera.
-

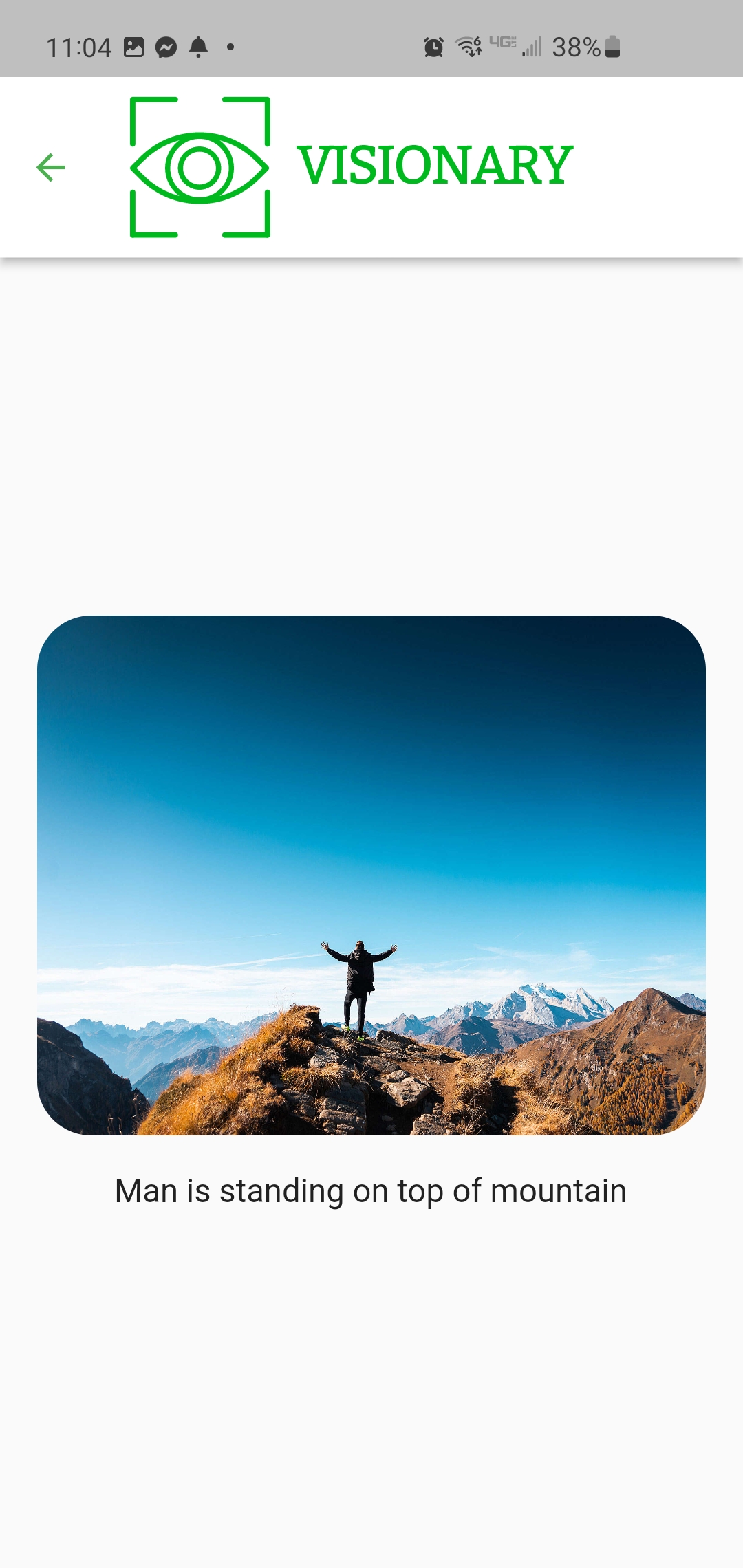
Visionary allows users to upload images and will generate a text description of the image.
-

Visionary also allows users to understand the objects contained in a scene using object detection.
-

Text OCR is used to allow users to upload images of text, and Visionary reads the output out loud.





Inspiration
It is estimated that over 36 million people around the world are blind and 216 million are severely visually impaired. However, with the groundbreaking, bleeding-edge technology that is currently being developed and researched today, we were inspired to make bleeding-edge research into a practical and novel app that helps the visually impaired navigate the world. Thus, we developed Visionary, a revolutionary mobile app that provides the visually impaired with an easy to navigate tool that gives them insights into the visual world.
What it does
The application’s landing page guides the user to three different menus that have easily accessible functionalities. The app steps the user through each element in the page through audio instructions. The three main functionalities of our app include Text OCR (converting images of text into audio of the text that is spoken out loud), Object Detection (recognizing the objects present in the image), and Image Captioning (generating a sentence to describe a particular image or scene). For each functionality, the user is able to take images with their phone or select images from their photo gallery to perform Text OCR and computer vision algorithms. Our video provides an example of Visionary being utilized in the real world to assist the visually impaired.
How we built it
To implement the machine learning aspect of our application, we combined computer vision using the Keras library and Natural Language Processing, trained our machine learning model on a huge data set in order to recognize common objects, and deployed the functionality to a Flask server API. In order to feature object detection on our app, we used computer vision libraries, tflite, and mobilenet to recognize the setting and set an overall description of the user's surroundings through the objects detected. Finally, to combine all these technologies together on a nice user interface, we used flutter to build our mobile app and design it to be accessible to blind individuals.
Challenges we ran into
- Developing the machine learning models used in the application
- We face many issues with Keras, TensorFlow, and integration models in the Flutter application
- Our machine learning model was complex and had multiple components involved, so rather than converting the model to TF-Lite form, we created a flask API server to handle the machine learning algorithms developed.
Accomplishments that we're proud of
We are very proud of our successful creation of the Flask server to resolve errors regarding combining ML algorithms with the Flutter mobile app. Additionally, we are proud of getting our image captioning to work considering the fact that it is a cutting edge technology that we were able to apply in a useful and applicable manner.
What we learned
We learned how to better integrate ML models with Flutter and TensorFlow. Additionally, we learned how to combine Computer Vision technologies with Natural Language Processing. We also learned how to use Flask to use an API that we can access from Flutter. Finally, we gained a deeper understanding of how Flutter works.
What's next for Visionary
We plan to expand our application to a wider audience not only in the U.S., but internationally as well, in order to advance accessibility for the visually impaired around the world. We also plan on adding more advanced functionalities, such as piecing together information from object detection and image captioning to create more complex and sophisticated image descriptions. Additionally, we plan to train our image caption network on a larger dataset to improve performance.



Log in or sign up for Devpost to join the conversation.