-
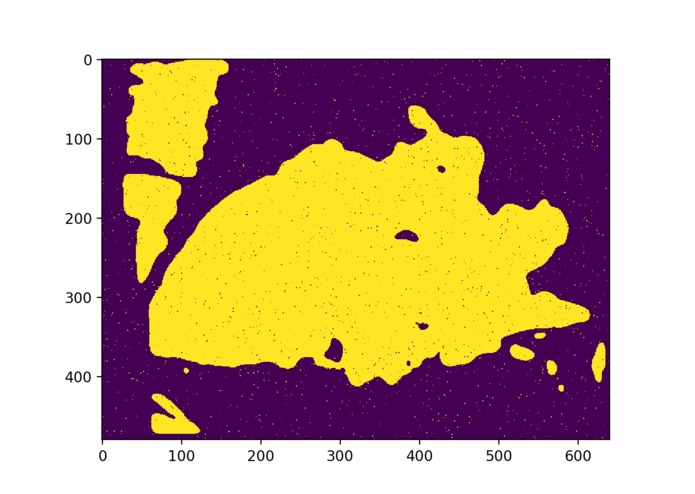
depth_process2
-
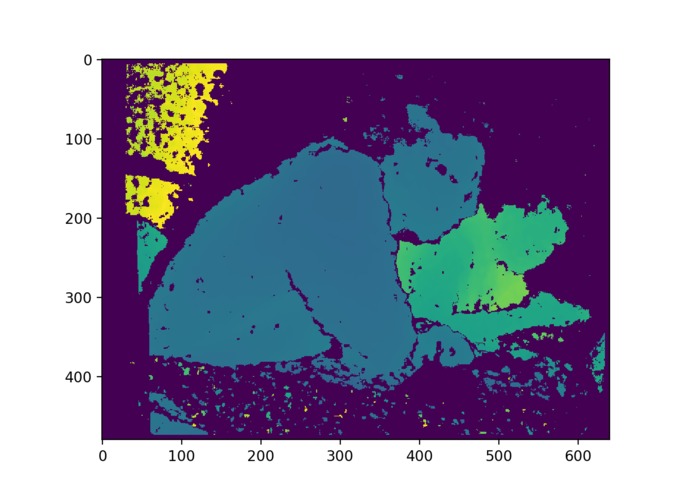
depth_proccess1
-
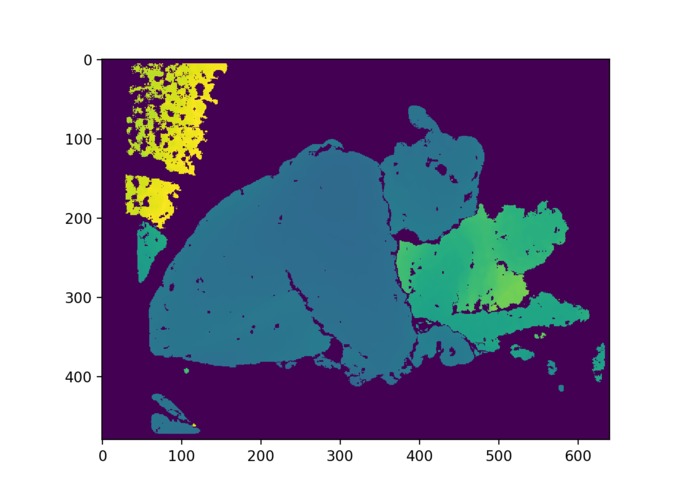
depth_process3
-
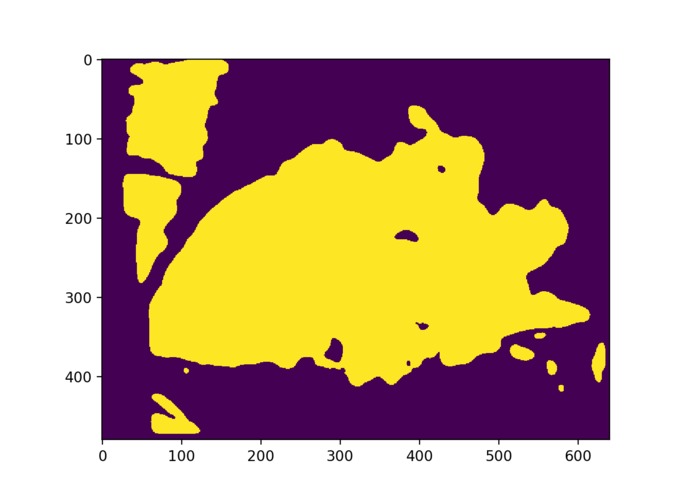
depth_process5
-
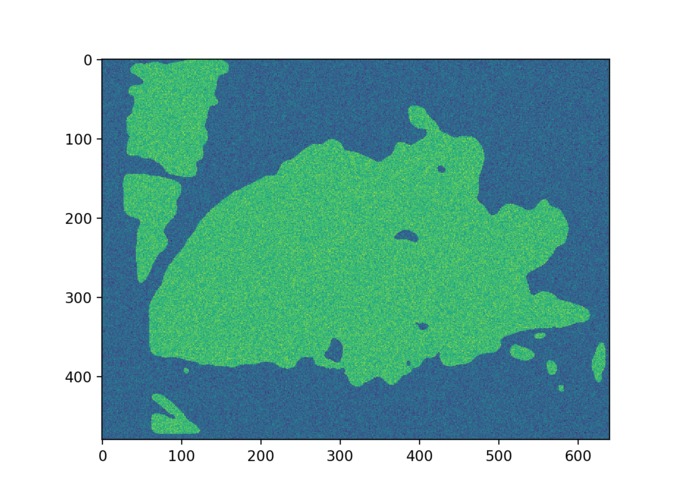
depth_process4
-
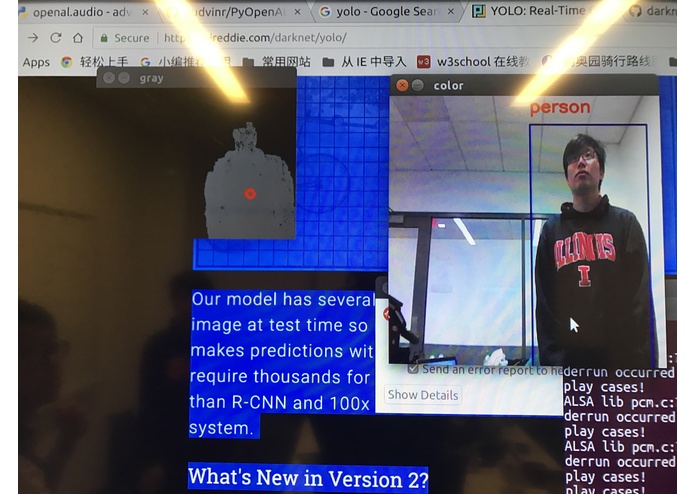
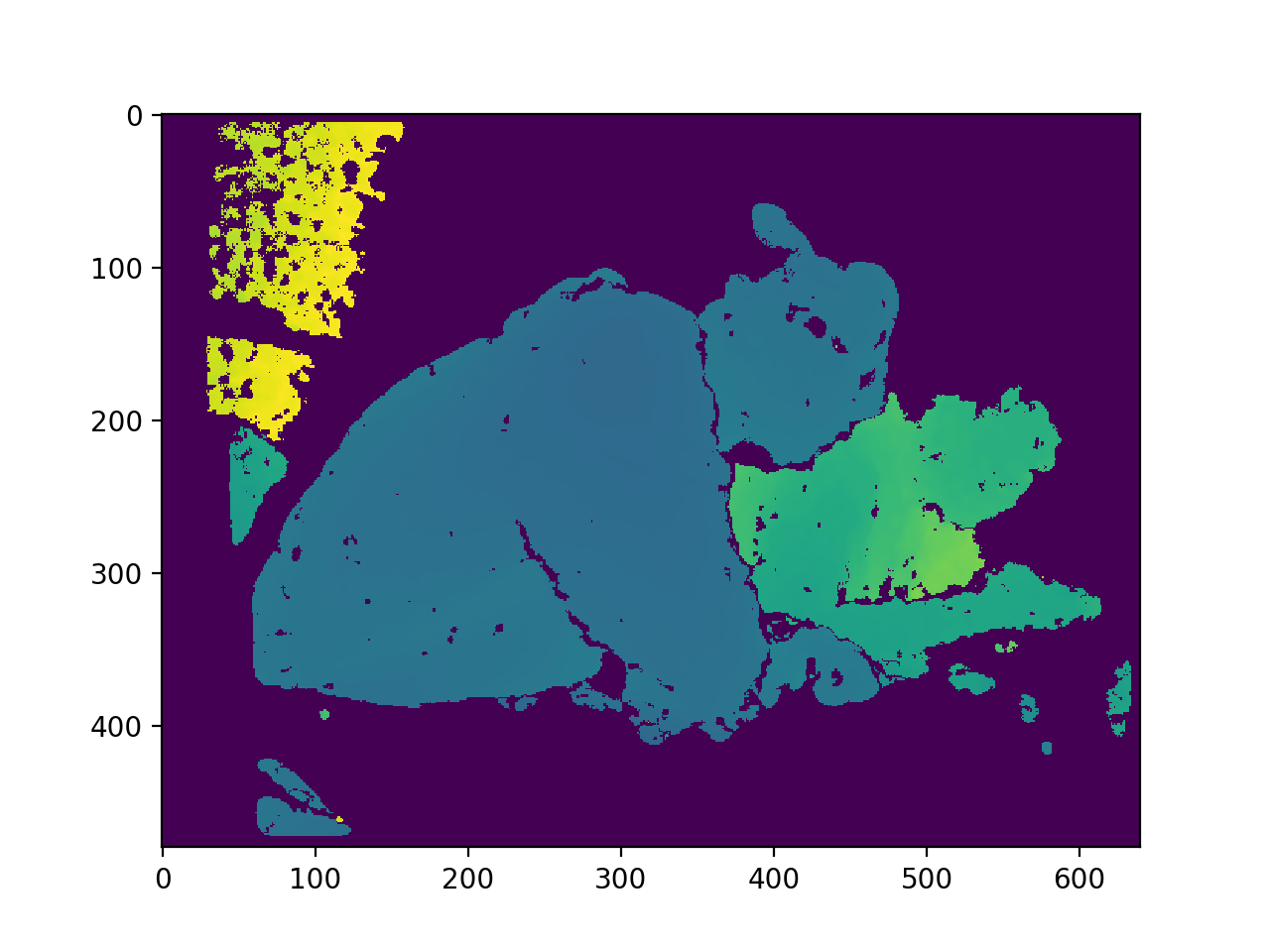
human and depth object detection
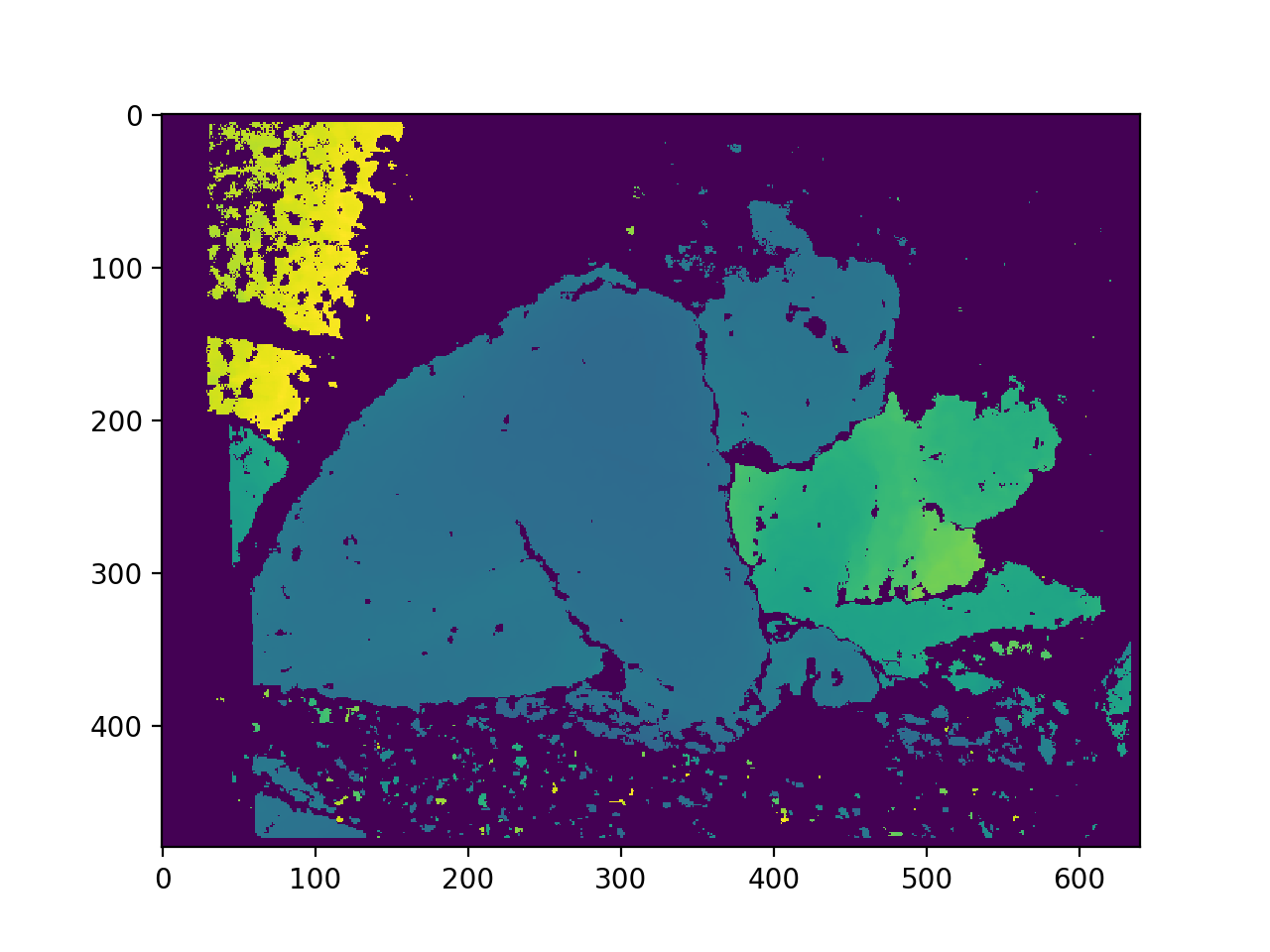
Inspiration
We are inspired by a video, three days of blindness, telling a story about the CEO of Tencent Ltd. experiencing a life of the blinds for three days. The video illustrated not only how blind people are living an inconvenient life, but also showed how they are disadvantaged in the sense of social status. In the recent few years, computer vision applications, with the help of deep learning, are approaching the level of human performance. We thought this might be the time to make use of the technology to bring vision back to those blind people.
What it does
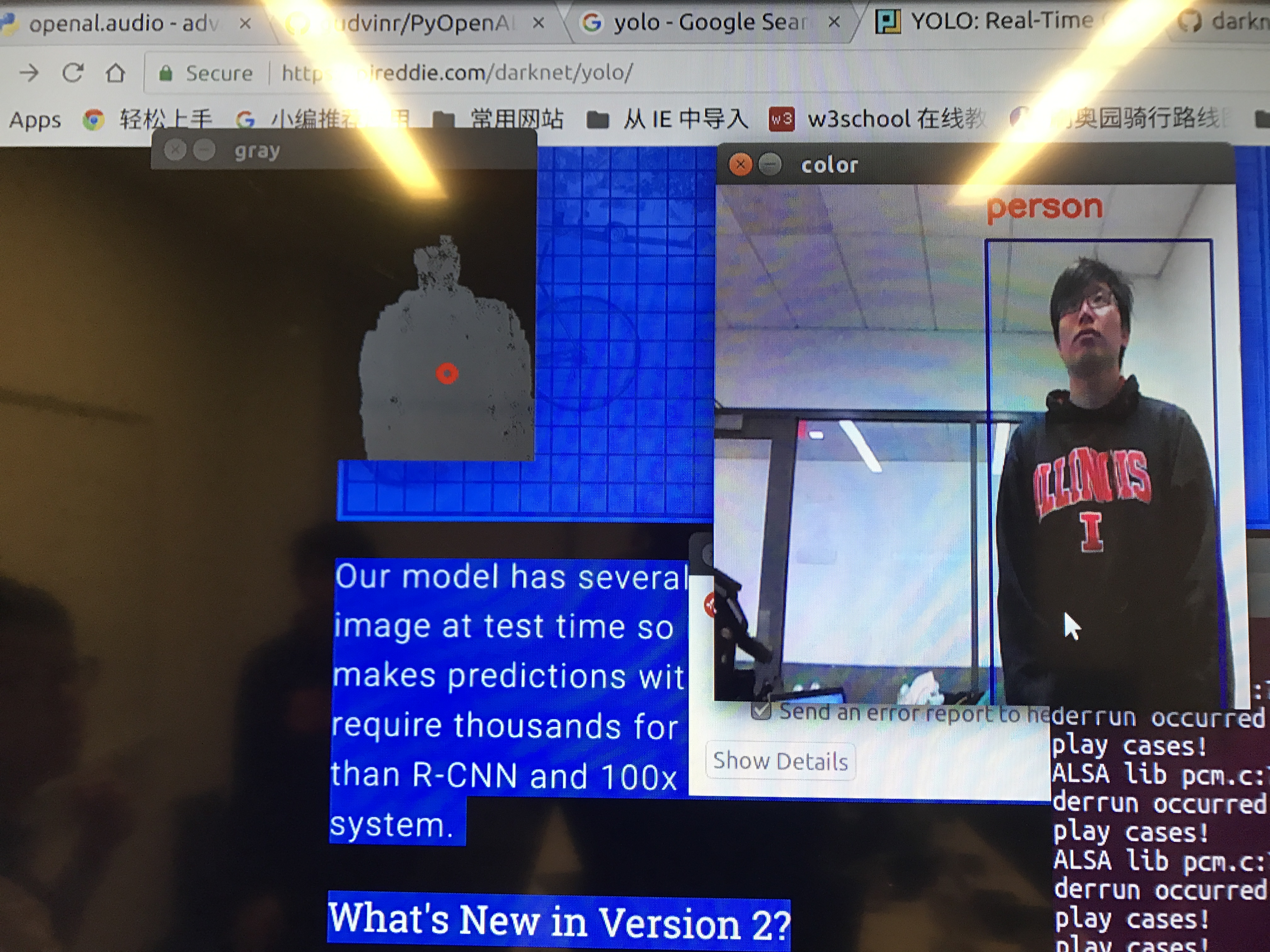
Our program takes in colored and depth image as input, and outputs audio signals to the user. Spatial obstacle information is encoded in a 3D audio map, and object recognition is converted to the language output. So, in some sense, it brings back the ability for the blinds to navigate with spatial visual information.
How we built it
We utilized Nvidia Jetson TX2 and Intel RealSense R200 RGBD Camera to do embedded real-time visual information processing. The depth image is processed with traditional computer vision method. The final visual representation is the cluster of objects that are in a range of 2 meters, and then the cluster information is transformed into beeping sound in a 3D audio map representation, to alert the user about the location of the obstacles nearby. Colored images are fed into a deep learning detection model to detect common objects, and the model output is then transformed into a Text-Speech converting API to generate language output.
Challenges we ran into
All existing 3D audio generation python library built upon OpenAL is poorly documented and most of them are discontinued. So we have to write our own multi-threading logic for the audio generation. Because of hardware limitations, we had to make out object and feature detection algorithm efficient to track in real time. Also, working with the Intel RealSense R200 was challenging due to the limited documentation.
Accomplishments that we're proud of
We successfully made and pushed changes to the Intel RealSense Library and the OpenAL library for python, pushing major bug fixes to make them compatible with the Jetson TX2 platform.
What we learned
In the real world, making project build on other developing project is hard. It requires merging different libraries and writing pipeline and thread to make them work together. We also find that reading the documentation for the hardware is very important. A lot of the spec and information are in the document and can only be used if we read through them thoroughly and carefully. Additionally, it was our first time working with many services - Microsoft's Azure for accelerated deep learning, Microsoft's text-to-speech API, OpenAL for Python, Intel RealSense library, etc. - yet it's still a great learning experience for all of us.
What's next for VisionSonic
The 3D audio for the program currently does not work. We failed to find a good library for python that meets our requirement. ( Fast in real time, thread ready) At the current stage, we are only able to use mono sound to send information to the user. If 3d audio is implemented in the future, the program will be better for the realization of the location of the object.



Log in or sign up for Devpost to join the conversation.