-
-
(Permission prompt screen) Visionary AI begins with secure access – requesting camera permission to enable real-time environmental narration
-
(Loading spinner / eye logo screen) "Launching Visionary AI – the intelligent observer initializing, ready to act as scene narrator."
-
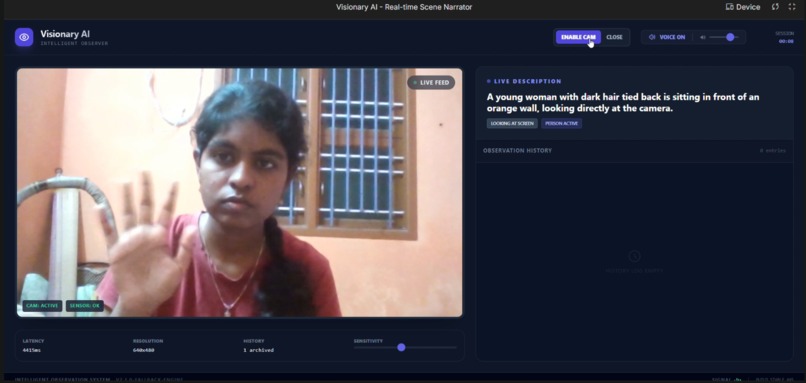
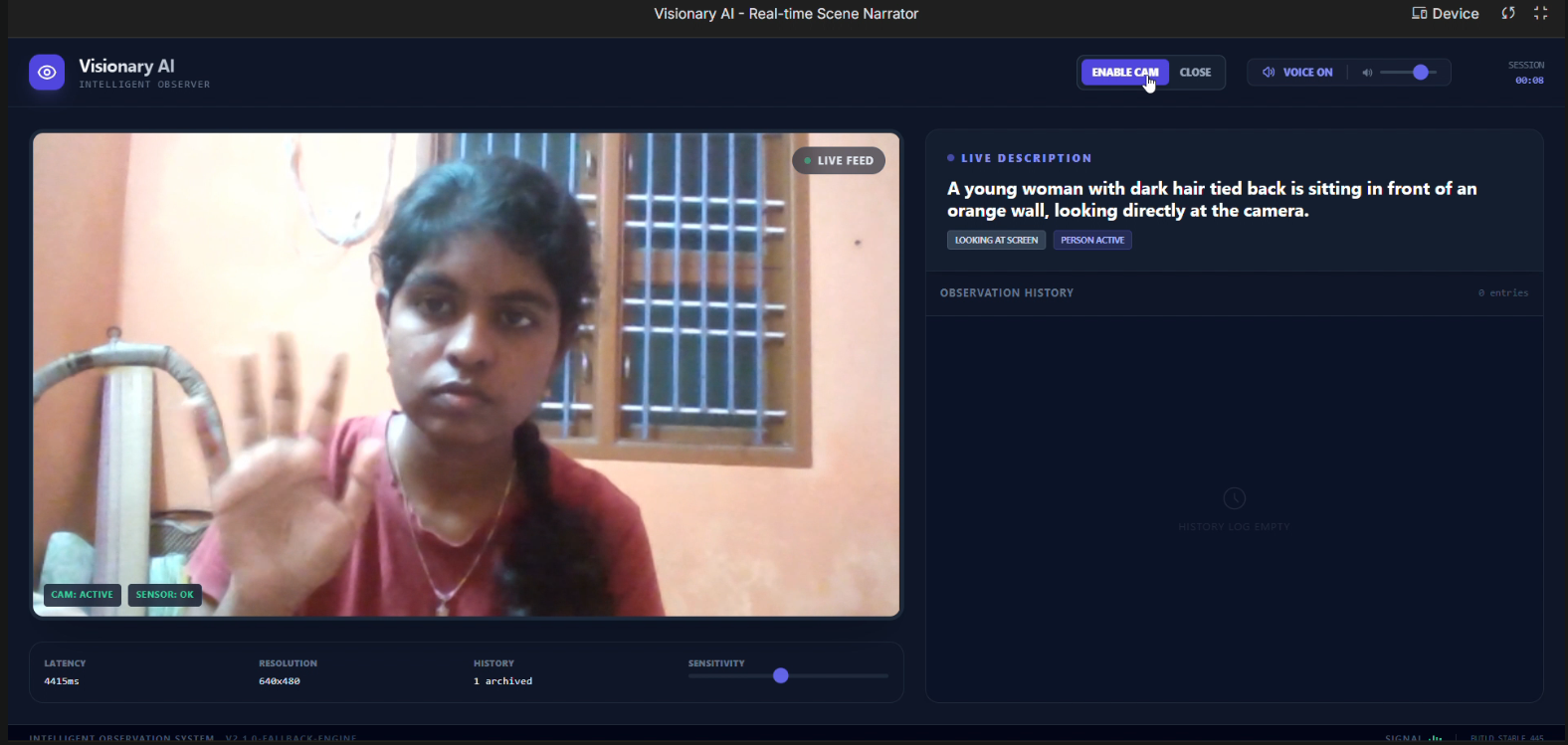
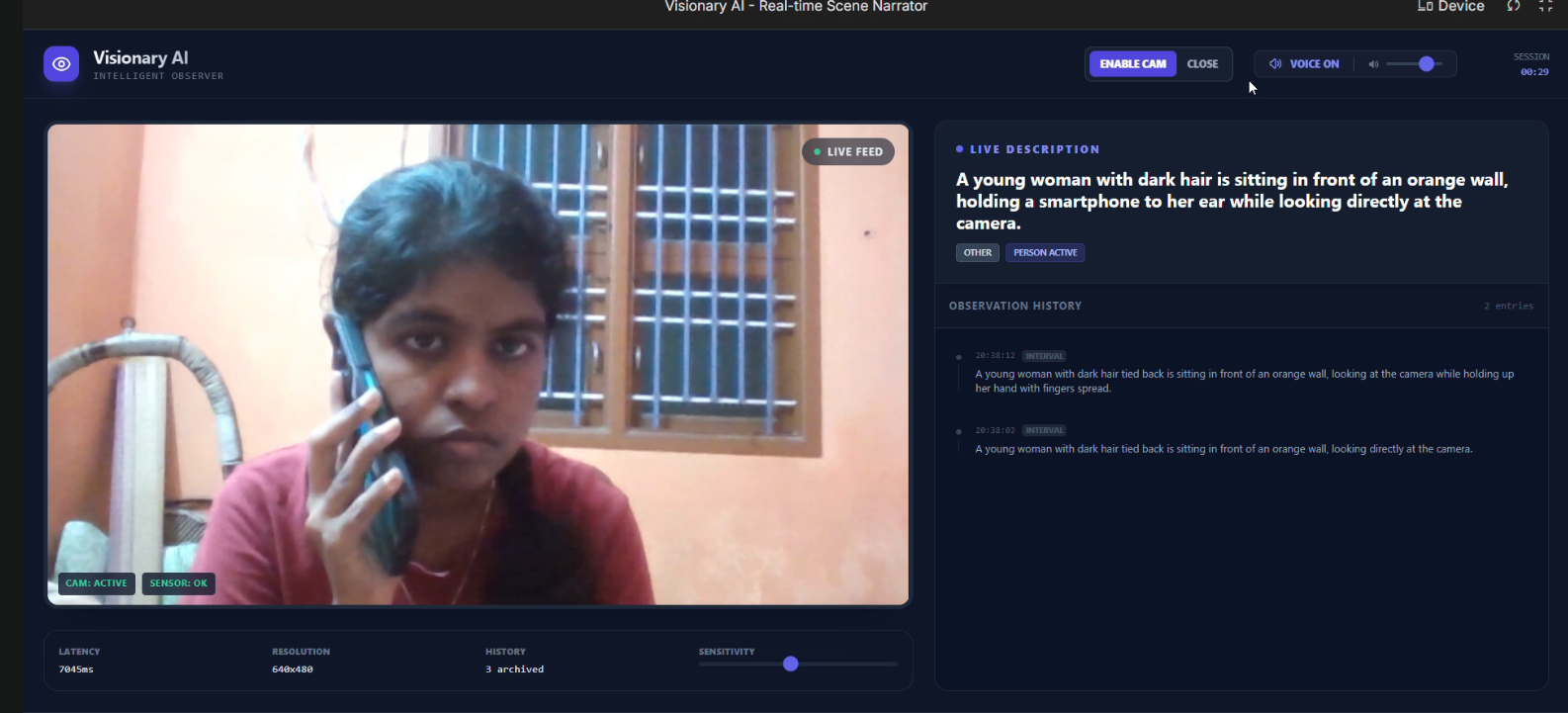
(Full UI with live feed, descriptVisionary AI in action:Real-time webcam feed, live spoken narration, change detection, observation history"
-
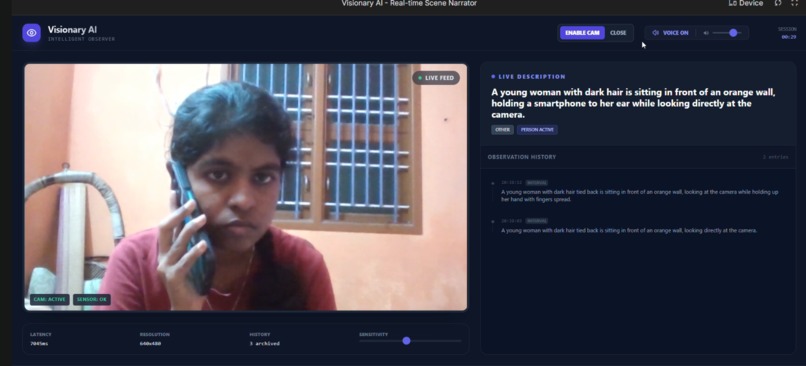
Visionary AI accurately narrates 'A young woman with dark hair looking at the camera' -delivering clear, contextual awareness in real time."
Inspiration
The struggle of over 2.2 billion visually impaired people to perceive their surroundings in real time inspired us to build a proactive, hands-free AI narrator that restores independence and safety.
What it does
Visionary AI turns any webcam into a real-time intelligent observer, continuously analyzing the scene and speaking concise descriptions of: Objects People Actions Positions Hazards Meaningful changes All narration is delivered in a natural voice, completely hands-free.
How we built it
We used React, Vite, and TypeScript for a fast, responsive UI with Tailwind CSS. Google’s Gemini multimodal AI powers vision analysis and narration, supported by custom change-detection algorithms and a fallback mode for reliability.
Challenges we ran into
Balancing low-latency real-time processing on consumer hardware, handling API quotas, and ensuring privacy-first local processing were major hurdles. TypeScript strictness and permission issues also tested our debugging skills.
Accomplishments that we're proud of
A fully local, privacy-first app that delivers accurate, change-aware narration in the browser — no cloud video uploads, seamless fallback, and an intuitive interface accessible to all.
What we learned
Deep insights into multimodal AI integration, real-time vision constraints, accessibility design, and the power of resilient, privacy-focused engineering.
What's next for Vision Narrator
Offline mode, multi-language support, and partnerships for real-world deployment to reach millions.

Log in or sign up for Devpost to join the conversation.