-

3-D image model
-
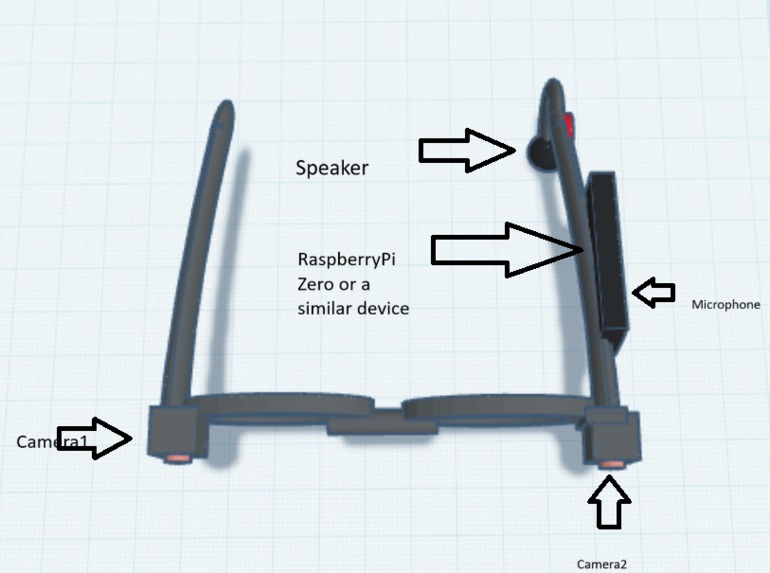
3-D image model with labels

Inspiration
In today's world, machine learning algorithms and computer vision have reached a place where robots can navigate themselves using these tools. But what about visually impaired people? Wouldn't it be possible to use these tools to help these people navigate similar to robots? With these thoughts, I decided to design a pair of glasses that would help the user navigate and look for specific objects to assist them.
What it does
This project is more of an idea that is supported with code and a simple design. Simply put, it is a pair of glasses that contain two cameras on them, and when the user speaks to the microphone on these glasses, the code detects the voice and uses the YOLOv8 model to search for the commanded object. Then the glasses can tell if the person should turn to the left or right to approach the object. Right now the model can only tell 80 classes, and the voice recognition isn't trained yet. It can only detect and tell if the object is to the right, left, or in front out loud. We modeled the 3-D design of the project with two cameras for future improvement and distance calculation.
How we built it
- We used the YOLOv8 image detection to be both precise and do fast recognition.
- For the models, we used the Ultralytics library, which has 80 classes that are pretty helpful with navigating things that people see and use every day.
- We used the SpeechRecognition Python library for the speech recognition, which could use TensorFlow models to turn speech into text, but because of the limited time we weren't able to train a TensorFlow model. But when the model is trained, the code already contains the needed functions to run this module.
- We used pyttsx3 to turn text into speech, which we use to inform the user about whether the target is to the right or left.
Challenges we ran into
- It took me a while to learn and understand how speech-to-text works and how I can train a model to do this project. It ended up not being done on time for this hackathon.
- Since this is the first time I am working in a big
Accomplishments that we're proud of
Being able to detect the target object and using the position of the object on the camera to help with navigation was a huge success for us.
What we learned
This is the first time that I used advanced libraries to do computer vision, and I learned the basics of these models and how to use them. Also, while trying to train a speech recognition model, which I didn't have enough time to complete, I understood how the tones and the general patterns in a word could be matched with the person's voice and turned into text.
What's next for Vision-eyes
- Training a speech recognition model to be able to use the microphone future for each of the classes
- Adding more recognition of everyday objects to the YOLO model
- Adding a second camera or using a more advanced camera to be able to calculate the distance, how many objects there are for more advanced navigation assistance.
- Another thing that could be added might be to use a generative AI like ChatGPT to combine with our code to do a better analysis of the environment and navigate.
Built With
- python
- ultralytics
- yolov8



Log in or sign up for Devpost to join the conversation.