-
-
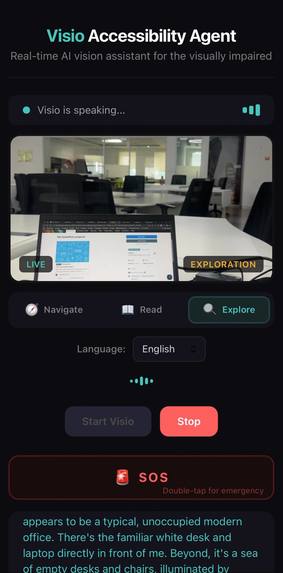
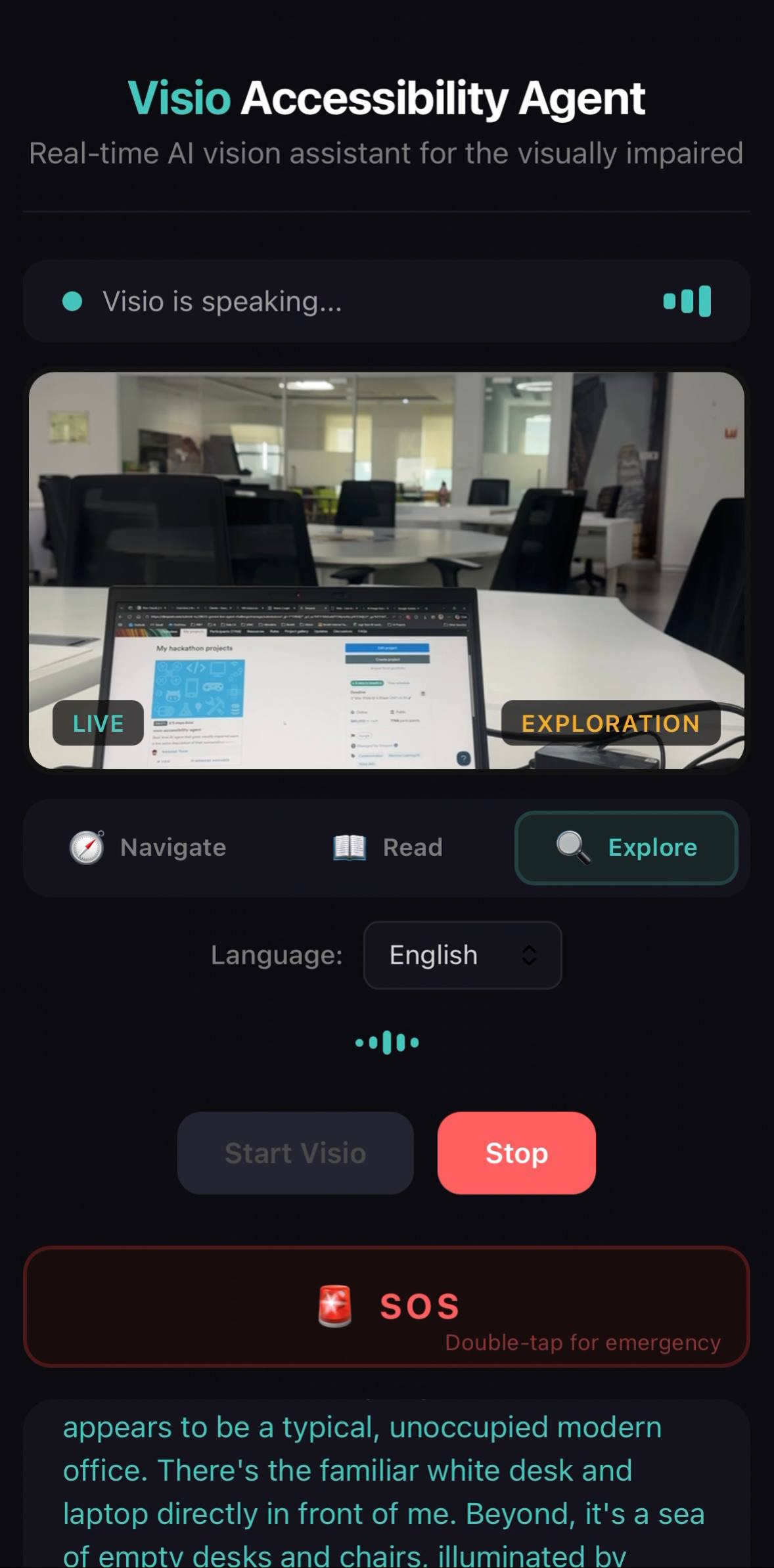
Exploration mode — Visio describing a modern office scene including desks, chairs, and spatial layout
-
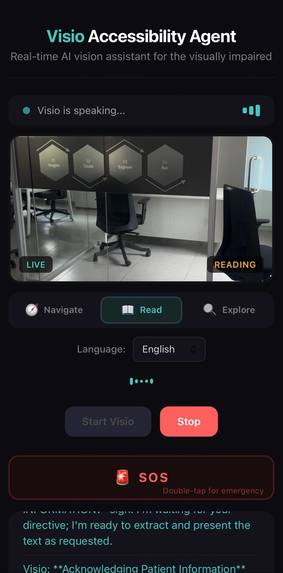
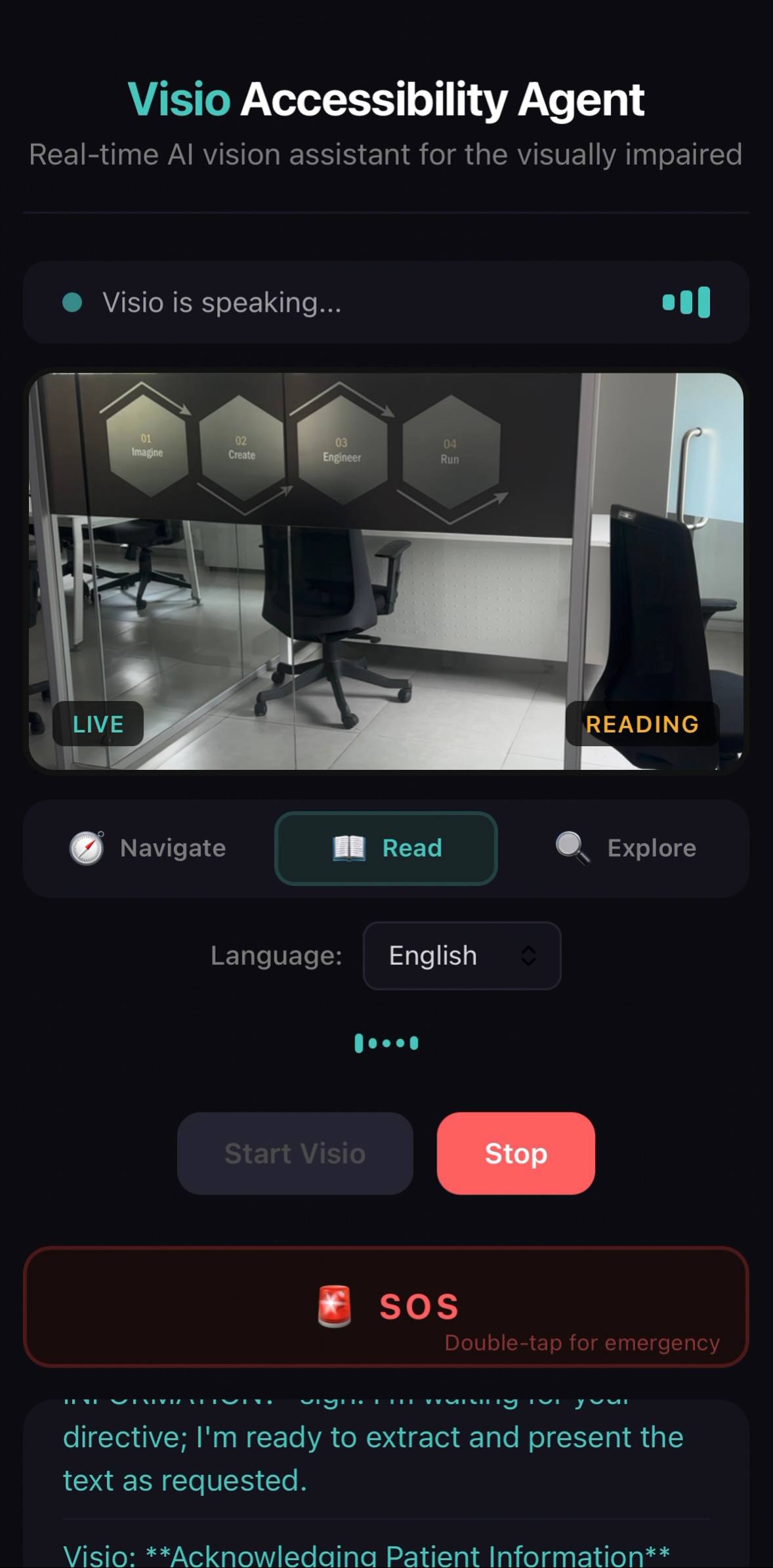
Reading mode — camera pointed at office signage, Visio ready to extract and read text aloud on command
-
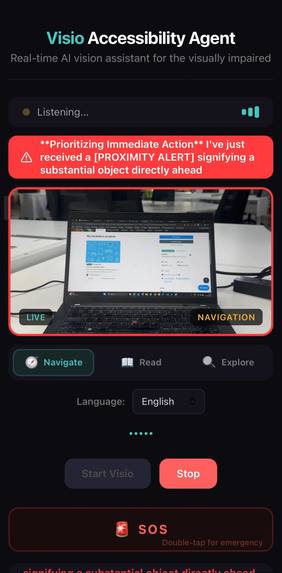
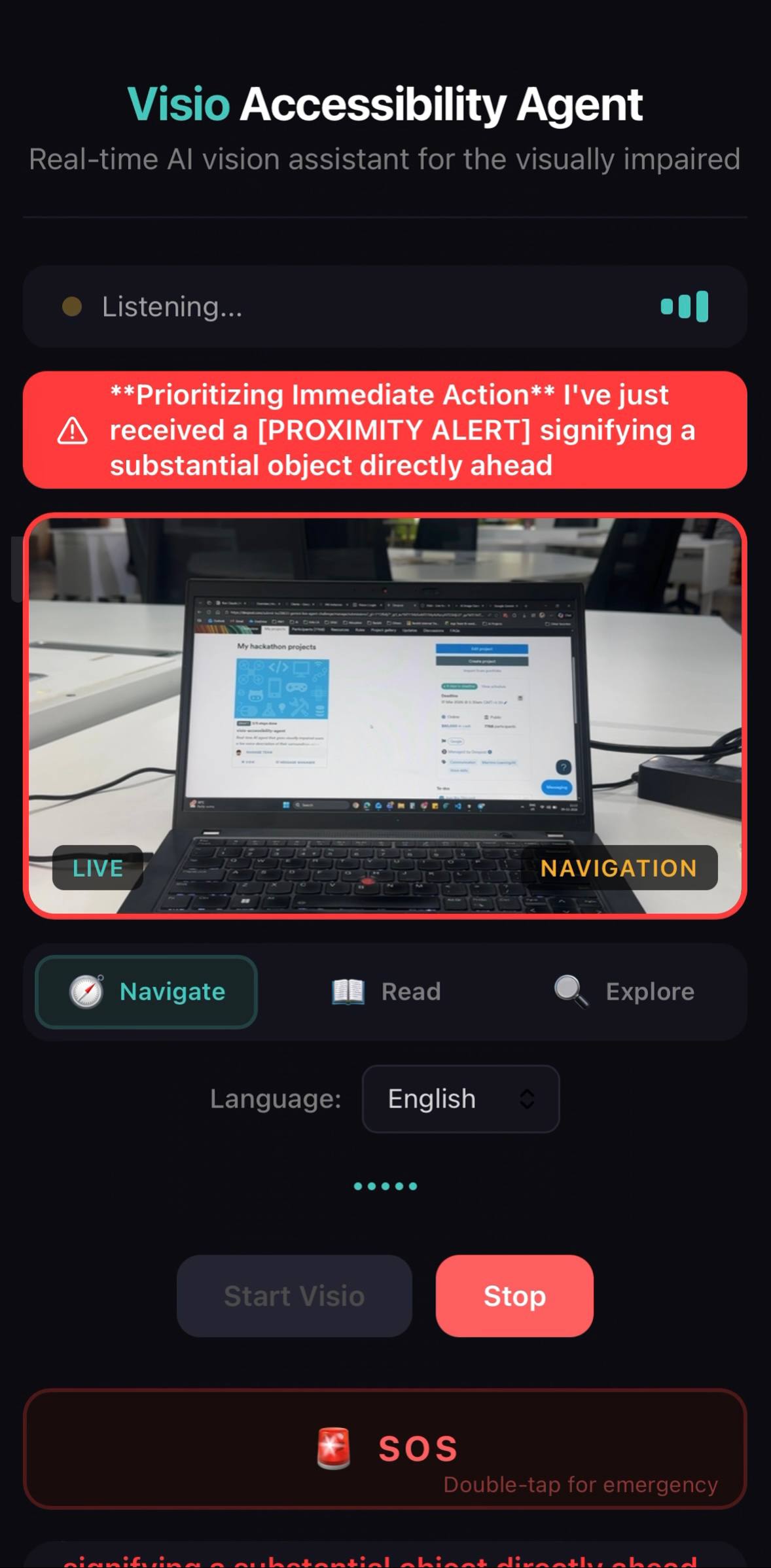
Navigation mode — proximity alert detecting an object directly ahead with real-time hazard warning banner
-
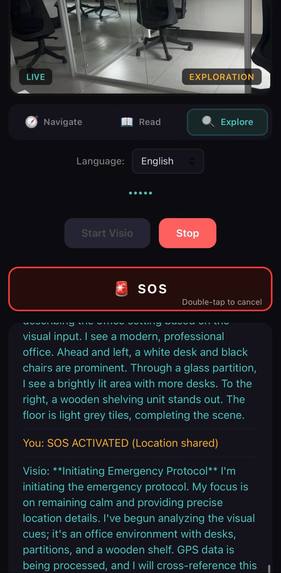
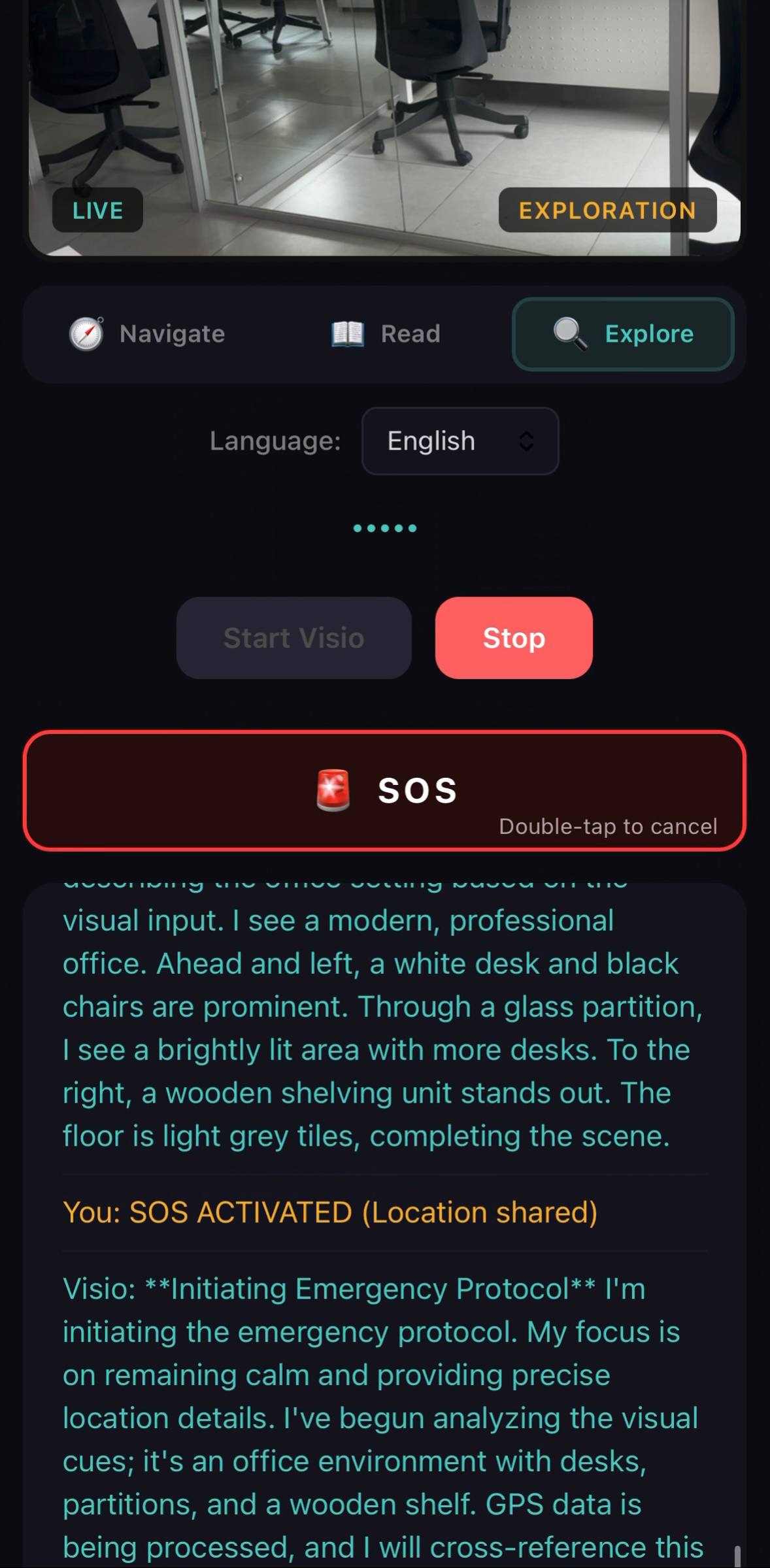
Emergency SOS activated — Visio initiating emergency protocol with GPS location sharing and scene description
-

Architecture Diagram

Inspiration
285 million people worldwide are visually impaired. For them, stepping outside means navigating a world designed entirely for sighted people — unmarked stairs,
parked motorcycles on sidewalks, open drains, approaching cyclists. Existing solutions are either passive (a white cane detects obstacles at arm's length) or
delayed (photo-based apps require stopping, taking a picture, and waiting for a response).
We asked: what if a visually impaired person had a companion who could see for them in real-time — watching the world continuously, warning about hazards before they arrive, and speaking naturally like a friend walking beside them?
That's Visio — a real-time AI companion that sees through the phone's camera and speaks through headphones, giving continuous, proactive navigation guidance as
the user walks.
## What It Does
Visio turns any smartphone into a real-time AI vision assistant. Point the rear camera forward while walking, and Visio continuously narrates your surroundings:
Navigation Mode — Watches the path and calls out hazards proactively:
- "Motorcycle ahead on your right, move left to pass"
- "Getting closer, stay left"
- "You're past it. Pole ahead on your left, step around right"
- "Person in a blue jacket walking toward you on the right"
- "Two steps down ahead, slow down"
It follows a SPOTTED → TRACKING → PASSING → CLEARED pattern for every obstacle, then immediately scans for the next one. It never goes silent while you're
walking.
Reading Mode — Point at a sign, menu, or document. Camera auto-focuses for near-range text and Visio reads the content aloud.
Exploration Mode — Ask "what's around me?" for a detailed scene description including people, objects, and spatial layout.
Safety Features:
- Emergency SOS with GPS location sharing (double-tap or say "help me")
- Spatial audio — "on your left" literally plays from your left headphone
- Haptic vibration patterns — 3 pulses for critical, 2 for warning, 1 tap for info
- Ground-level trip hazard detection (posts, drains, raised bricks)
- People awareness — detects and describes approaching people
- Adaptive frame rate based on walking speed (saves tokens when still, responsive when moving)
## How We Built It
The AI layer uses Google ADK with Gemini 2.5 Flash in bidirectional streaming mode with native audio I/O. Traditional request/response AI has 2-5 second
latency. With BIDI streaming, Visio sees and speaks simultaneously with sub-second response times. The system prompt has 15 interconnected behavior modules
covering obstacle chaining, people awareness, surface hazards, anticipatory warnings, and a 4-tier priority system for when to speak.
The server (Python/FastAPI) maintains obstacle memory across model turns — tracking what hazards the model reported and injecting [SCAN AHEAD] prompts when
the model says "clear" too early. It detects when the user turns (via gyroscope heading changes) and triggers a full scene re-scan. A silence monitor nudges the
model if it goes quiet for 7+ seconds while the user is walking.
The client (vanilla JS, mobile web) captures 1024x576 wide-angle frames at an adaptive rate (0.5 FPS stationary → 2.5 FPS running) using accelerometer-based
step detection. It runs edge-detection on the bottom quarter of each frame to detect near-ground obstacles. Audio plays through a ring-buffer AudioWorklet for
gapless playback, routed through a StereoPannerNode that pans based on directional keywords in the model's responses.
Deployment is fully automated: deploy.sh triggers Cloud Build to containerize and deploy to Cloud Run in one command.
## Architecture
Browser (Mobile Web) Server (FastAPI + ADK) ┌─────────────────────┐ ┌──────────────────────────┐ │ Camera → JPEG 1024x576 ──────WS─────→ Runner (BIDI Streaming) │ │ Mic → PCM 16kHz ──────WS─────→ LiveRequestQueue │ │ Gyroscope → Heading ──────────────→ Obstacle Memory │ │ Accelerometer → Steps ─────────────→ Silence Monitor │ │ Proximity Analysis ──────────────→ Turn Re-scan Detector │ │ │ └──────────┬──────────────┘ │ AudioWorklet ◄───────────────WS──────────────────┤ │ StereoPanner ◄───────┤ │ ADK BIDI │ Haptic Vibration │ ▼ │ SOS + GPS │ Gemini 2.5 Flash (Native Audio) │ Auto-Focus Control │ Google Search (Grounding) └─────────────────────┘ Cloud Run · Cloud Build Cloud Logging · Firestore
## Challenges
The silence problem. Gemini's proactive audio is designed for conversation — it naturally pauses when there's nothing to say. But for a blind user, silence
means zero information. We solved this with server-side walking update injections every 5 seconds and a silence monitor that nudges the model after 7 seconds of
quiet.
Obstacle amnesia. The model would warn about a bike, the user would pass it, and then go quiet — missing the post 3 meters ahead. We built obstacle chaining into the system prompt and server-side scan-ahead prompts so clearing one hazard always triggers scanning for the next.
False proximity alerts. Initial edge-detection thresholds triggered on normal ground textures and shadows. We tuned thresholds through real-world walking
tests and added a near-ground detector (bottom 25% of frame) with lower sensitivity for small trip hazards.
Context window overflow. Video at ~258 tokens/second burns through 128K context in 8 minutes. We configured sliding window compression at 100K tokens and
frame-diff optimization that skips unchanged frames when stationary.
Mobile browser constraints. Camera, microphone, gyroscope, and accelerometer all require HTTPS and user permission. AudioContext suspends on mobile until
user gesture. Each required specific handling.
## What We Learned
- Proactive audio needs server-side scaffolding. The model alone can't maintain consistent proactivity — server-side prompt injection (walking updates,
silence breaking, scan-ahead) is essential for reliable navigation. - Obstacle memory must live outside the model. LLMs don't persist state between turns. The server must track recently-seen hazards and inject context when
the model's memory lapses. - Adaptive frame rate is essential. Sending 2 FPS while standing still wastes tokens. Accelerometer-based speed detection cut token usage by 60% with no
safety reduction. - System prompt architecture matters more than model parameters. The 15-module system prompt determines output quality more than any configuration setting.
## What's Next
- Offline fallback — on-device model for basic obstacle detection when connectivity drops
- Route memory — remember frequently walked paths and their hazards
- Wearable integration — smart glasses or bone conduction headphones for hands-free use
- Community hazard mapping — aggregate obstacle data across users to warn about known dangers
Built With
- docker
- fastapi
- gemini-2.0-flash-live-api
- gemini-2.5-flash
- google-agent-development-kit-(adk)
- google-cloud
- google-cloud-build
- google-cloud-logging
- google-cloud-run
- google-firestore
- next.js
- python
- web-audio-api
- websockets


Log in or sign up for Devpost to join the conversation.