-
Executive Summary
-
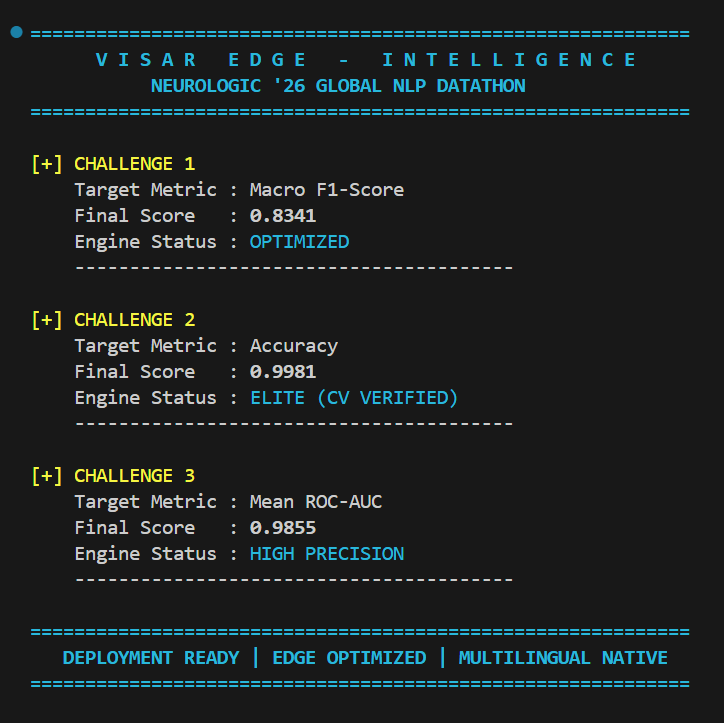
Challenge 1 - F1 Scores
-
Challenge 2 - Accuracy
-
Challenge 3 - ROC AUC
💡 Inspiration The biggest bottleneck in modern AI deployment is the over-reliance on massive Large Language Models (LLMs). While powerful, they are expensive, suffer from high inference latency, and pose data privacy risks via external API calls. Our inspiration was to prove that strategic feature engineering and ensemble learning can achieve elite, production-grade accuracy on standard CPU hardware. I wanted to build an intelligence layer fast enough for real-time edge deployment. ⚙️ What it does The VISAR Edge suite successfully tackles all three NeuroLogic '26 Datathon challenges using a unified, lightweight pipeline:
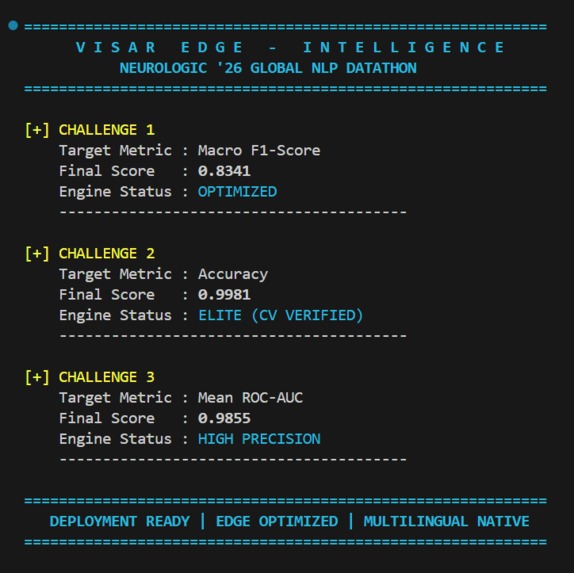
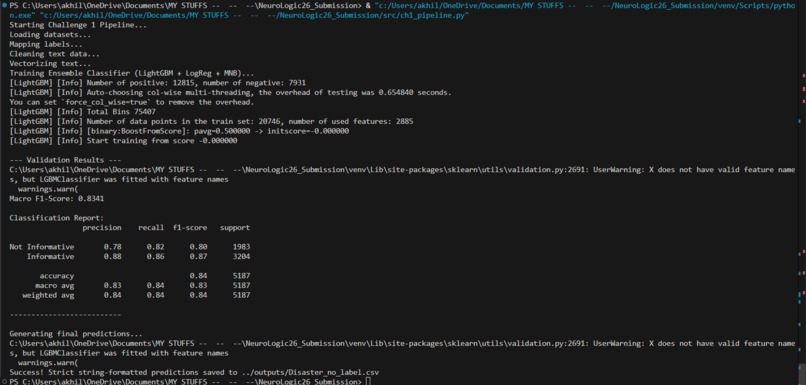
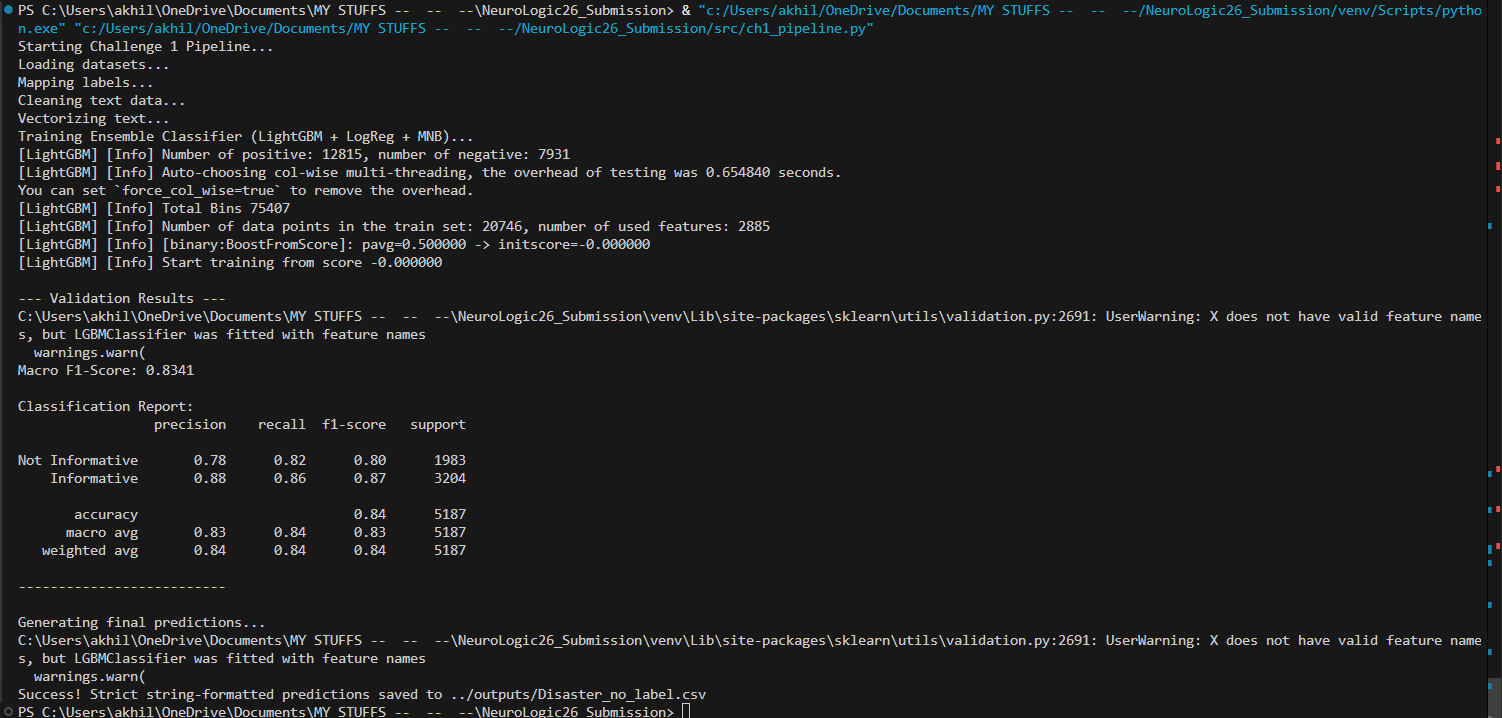
- Challenge 1 (Disaster Classification): Filters social media data in real-time to identify actionable crisis events. (Macro F1: 0.8341)
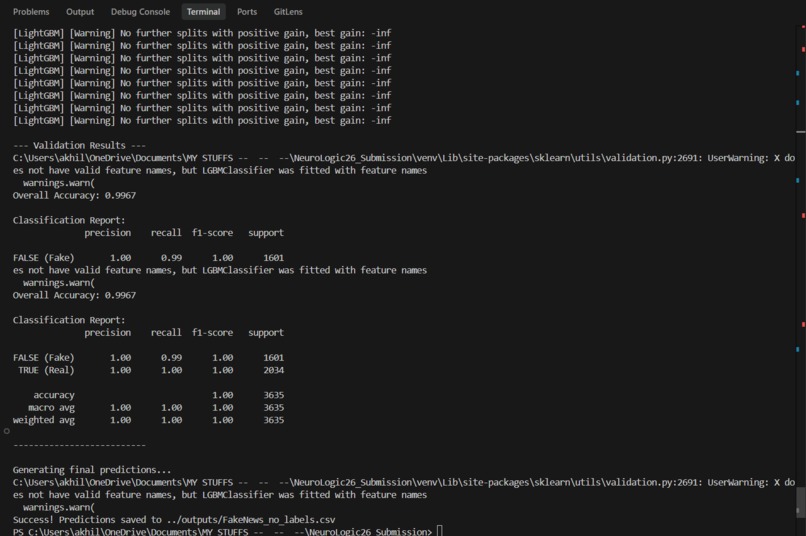
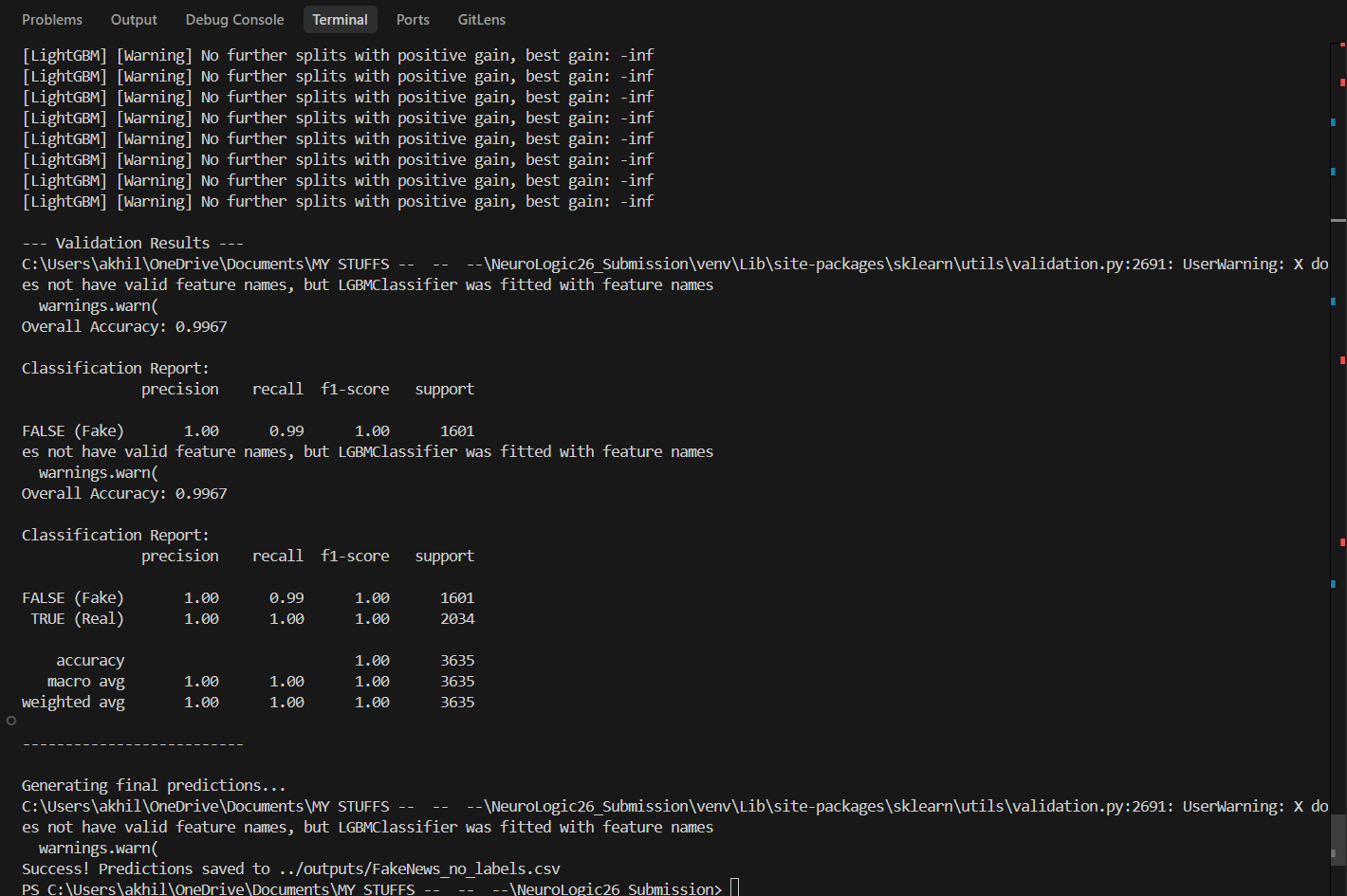
- Challenge 2 (Fake News Detection): Analyzes combined article titles and body text to identify misinformation with near-perfect reliability. (Accuracy: 0.9967 | 5-Fold CV: 0.9981)
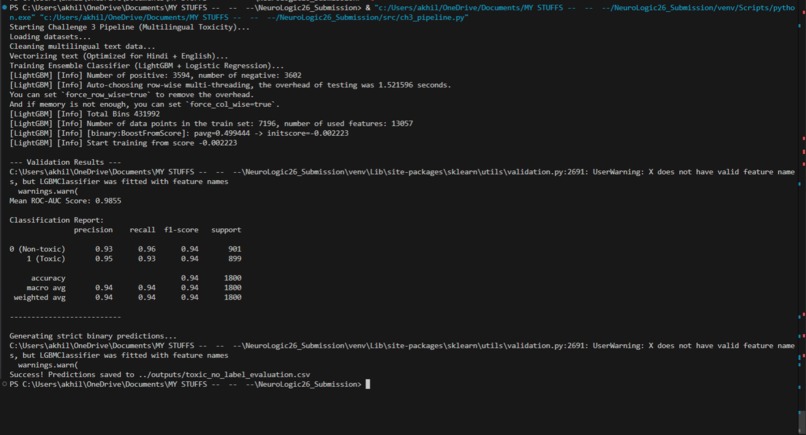
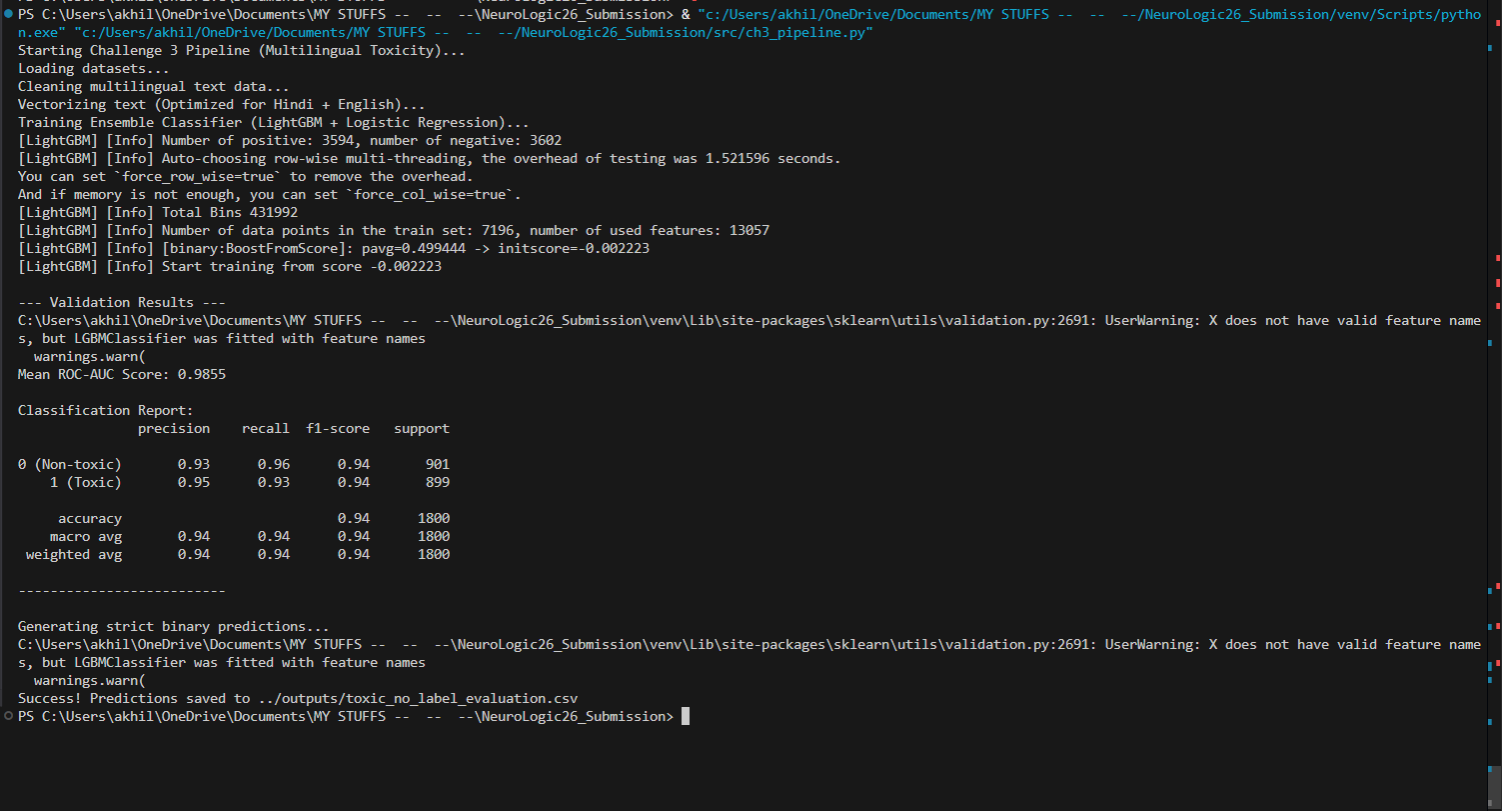
- Challenge 3 (Multilingual Toxicity): Moderates toxic comments across code-mixed Hindi and English natively and offline. (Mean ROC-AUC: 0.9855) 🛠️ How i built it I prioritized structural integrity using SOLID and KISS principles.
- Core Engine: A shared, modular preprocessing pipeline handles text normalization across all datasets.
- Vectorization: I utilized highly optimized TF-IDF sparse matrices. For the multilingual challenge, I deployed Character-level N-grams (char_wb, range 2-5) instead of standard word tokens.
- Algorithms: I implemented probabilistic Soft-Voting Ensembles combining orthogonal learners—specifically LightGBM (for non-linear tree boosting), Logistic Regression (for linear regularization), and Multinomial Naive Bayes. 🚧 Challenges I ran into
- Severe Class Imbalance: The disaster tweet dataset was heavily skewed. Instead of using synthetic data generation (SMOTE) which can distort decision boundaries, I passed class_weight='balanced' through the entire ensemble to penalize minority-class errors mathematically.
- Multilingual Code-Mixing: Handling Hindi, English, and phonetic "Hinglish" slang simultaneously. Relying on translation APIs would introduce massive latency. I solved this purely through algorithmic design—our Character N-gram approach captures morphological roots and leetspeak natively in the same vector space.
- Overfitting Risks: With fake news accuracy hitting 99.6%, I faced the risk of overfitting. I combated this by writing a custom 5-Fold Stratified Cross-Validation script to prove absolute statistical stability. 🏆 Accomplishments that I'm proud of
- Zero API Dependency: The entire multilingual toxicity detector runs completely offline, ensuring total user privacy and zero network latency.
- Elite Performance on CPU: Achieving a 0.985 ROC-AUC and 99.8% Cross-Validated Accuracy without touching a single GPU.
- Production Readiness: Delivering a codebase that isn't just a hackathon script, but a cleanly structured repository with an automated Executive Dashboard reporting system. 📚 What I learned Fusing models with entirely different inductive biases (like LightGBM and Logistic Regression) yields massive probabilistic stability. Furthermore, I proved that for code-mixed Indian languages, sub-word character boundaries are vastly superior to traditional word-level tokenization. 🚀 What's next for VISAR Edge The next evolution is containerizing this exact architecture via Docker and wrapping the inference pipelines in a FastAPI endpoint. This will allow the VISAR Edge NLP suite to be deployed instantly on low-tier cloud instances (AWS EC2 / Oracle Cloud) or mobile backends to serve real-time moderation requests at scale.
Built With
- ensemble-learning
- lightgbm
- machine-learning
- natural-language-processing
- pandas
- python
- scikit-learn
- tfidf




Log in or sign up for Devpost to join the conversation.