VisaAI: Making Global Mobility Accessible Through AI
What Inspired Us
The visa application process is broken. Millions of people worldwide face confusion, anxiety, and uncertainty when applying for visas. Official government websites are dense with legal jargon, requirements vary by nationality and purpose, and professional immigration consultants charge hundreds or thousands of dollars.
We experienced this pain firsthand—friends struggling to understand Canada's study permit requirements, family members confused about USA visitor visa documentation, and countless stories of applications rejected due to missing or incorrect documents.
What if AI could democratize access to visa guidance? What if we could combine the power of Retrieval-Augmented Generation (RAG) with Large Language Models to provide personalized, accurate, and free visa assistance?
This question became the foundation of VisaAI—an AI-powered copilot that transforms visa application complexity into clarity.
The Vision
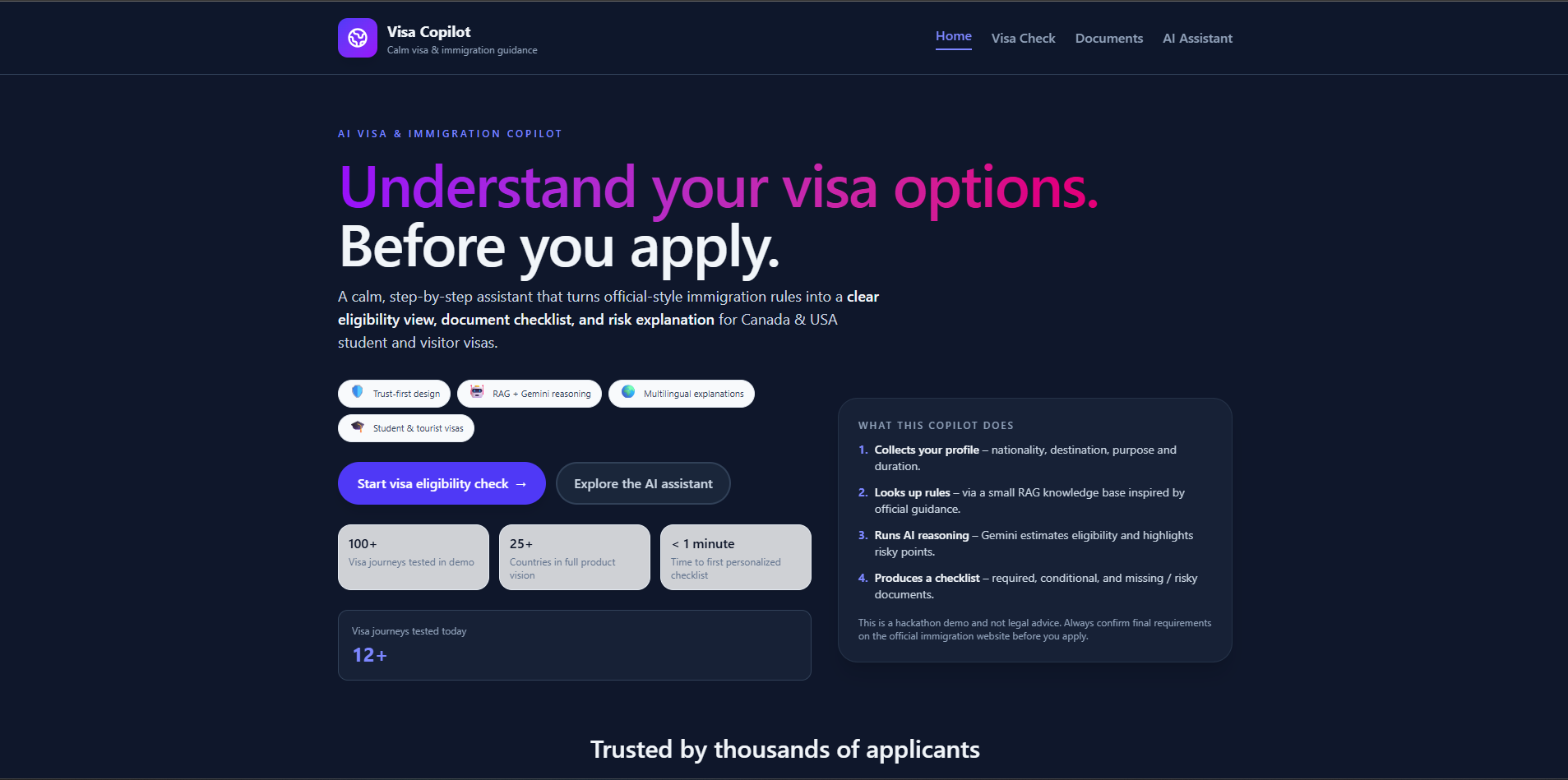
VisaAI aims to be the trusted AI companion for anyone navigating visa applications. We're not replacing lawyers or official sources—we're making professional-level guidance accessible to everyone, regardless of their location, language, or financial situation.
Our core principles:
- Accuracy: Ground AI responses in official visa rules using RAG
- Clarity: Translate legal requirements into plain language
- Personalization: Provide tailored guidance based on individual profiles
- Accessibility: Support multiple languages and free access
- Privacy: No data storage, GDPR-compliant design
How We Built It
Architecture Overview
VisaAI is built on a modern, production-ready stack:
- Frontend: Next.js 16 with React 19, TypeScript, and Tailwind CSS
- AI Engine: Google Gemini 2.5 Flash with custom RAG implementation
- Embeddings: Google Generative AI Embeddings (text-embedding-004)
- Validation: Zod for type-safe API validation
- Caching: Multi-layer caching strategy (client, CDN, Redis-ready, semantic)
The RAG Pipeline
The heart of VisaAI is our Retrieval-Augmented Generation system:
- Knowledge Base: We curated a dataset of official visa rules for Canada and USA (student and visitor visas), structured as semantic chunks
- Embedding Generation: Each rule chunk is embedded using Google's text-embedding-004 model
- Query Processing: User profiles are converted into query embeddings
- Semantic Search: Cosine similarity search retrieves the most relevant visa rules (top-K retrieval)
- Context Injection: Retrieved rules are injected into the LLM prompt as context
- AI Reasoning: Gemini analyzes the user profile against retrieved rules to generate personalized assessments
This approach ensures our AI responses are grounded in official sources rather than hallucinating requirements.
Key Features
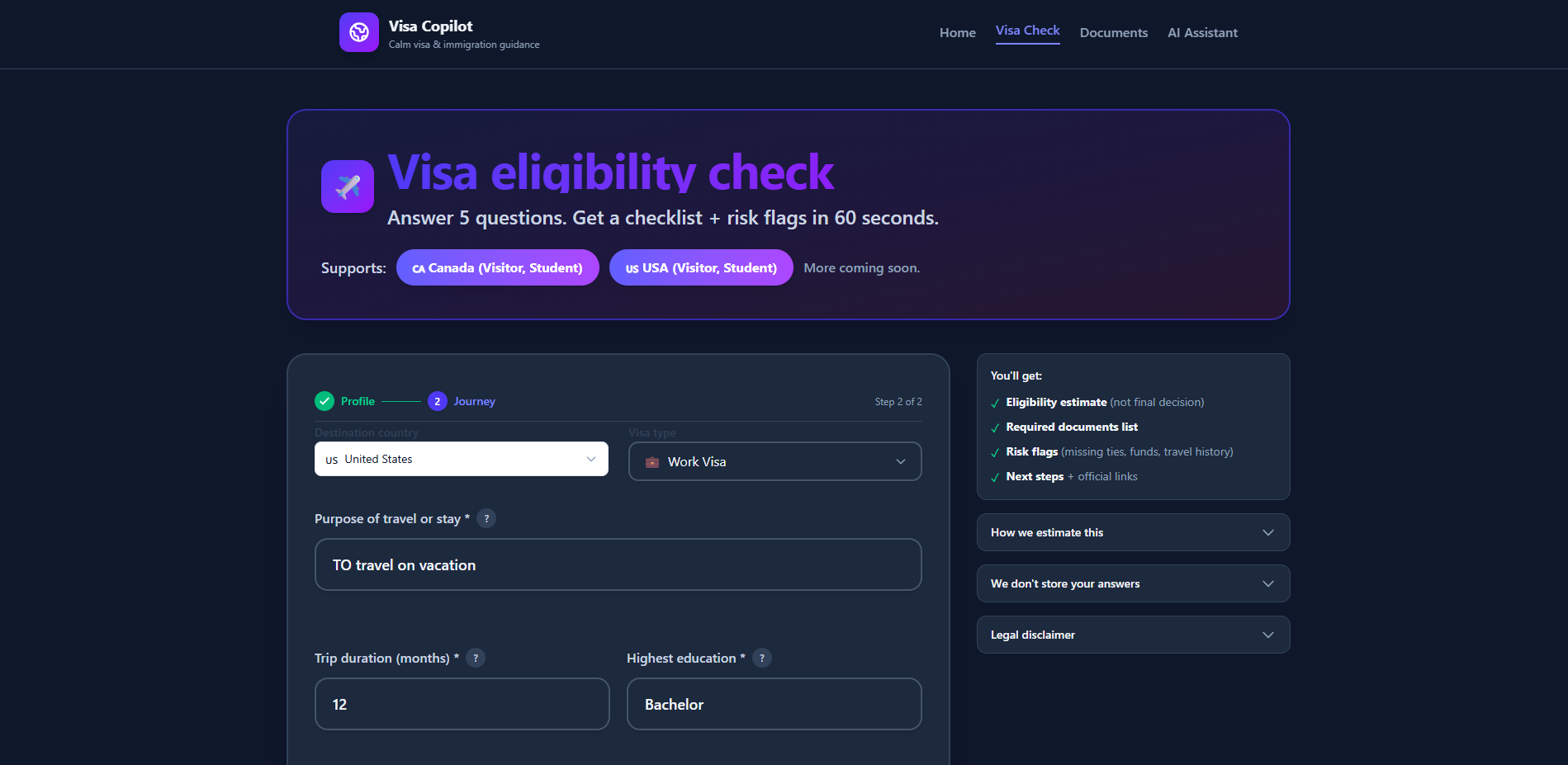
1. Visa Eligibility Assessment
- Multi-step form collecting nationality, destination, visa type, purpose, financial situation, and history
- Real-time validation and progress tracking
- RAG-powered rule retrieval based on user profile
- AI-generated eligibility assessment (Likely/Maybe/Risky)
- Personalized document checklist (required, conditional, risky/missing)
- Risk flags and actionable recommendations
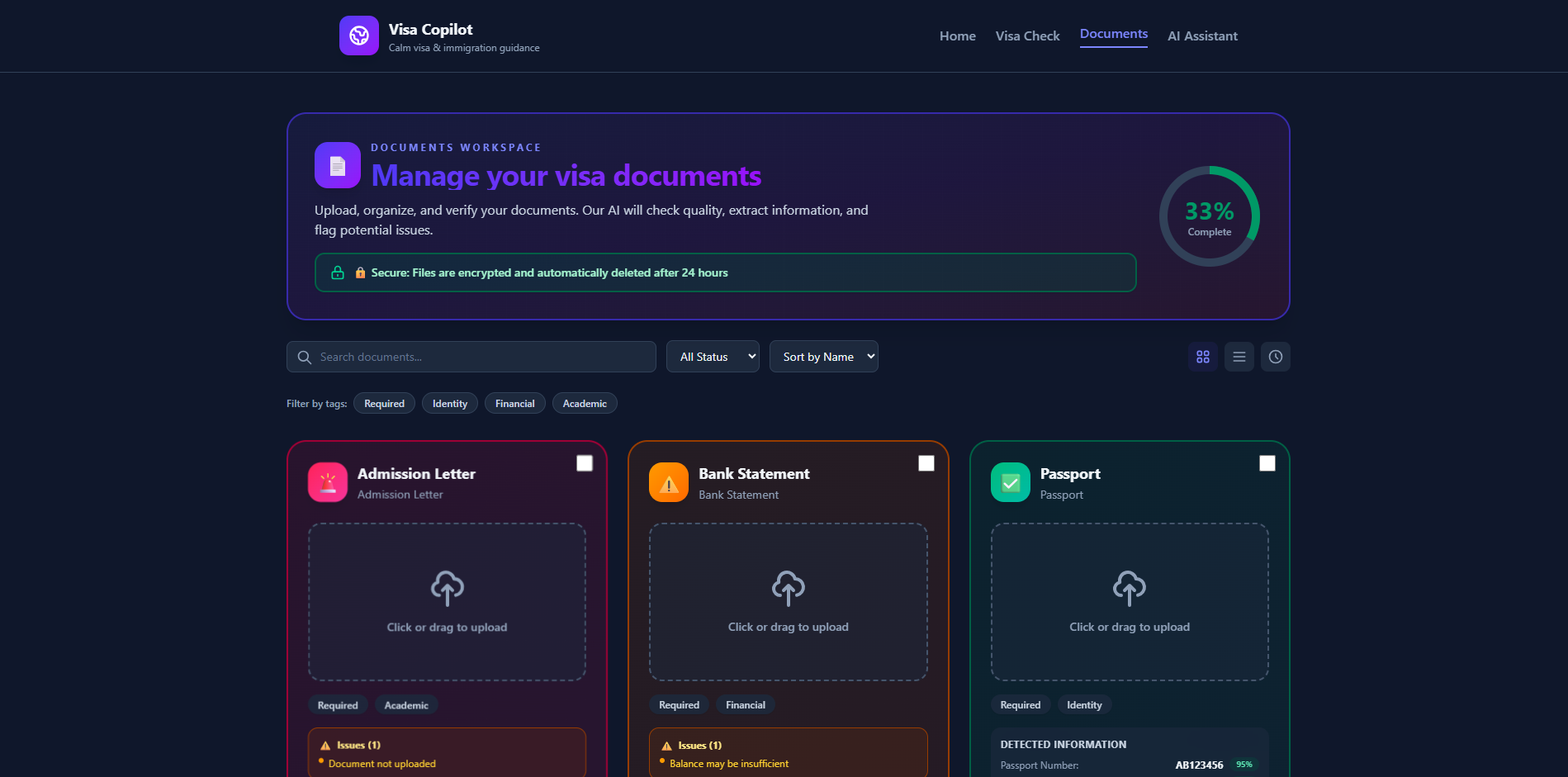
2. Document Intelligence
- Drag-and-drop document upload
- OCR-based text extraction (simulated with realistic mock data)
- Automatic document type detection
- Field extraction (passport numbers, expiry dates, balances, etc.)
- Quality scoring and confidence metrics
- AI-powered risk analysis identifying missing information and potential issues
- Actionable suggestions for document improvement
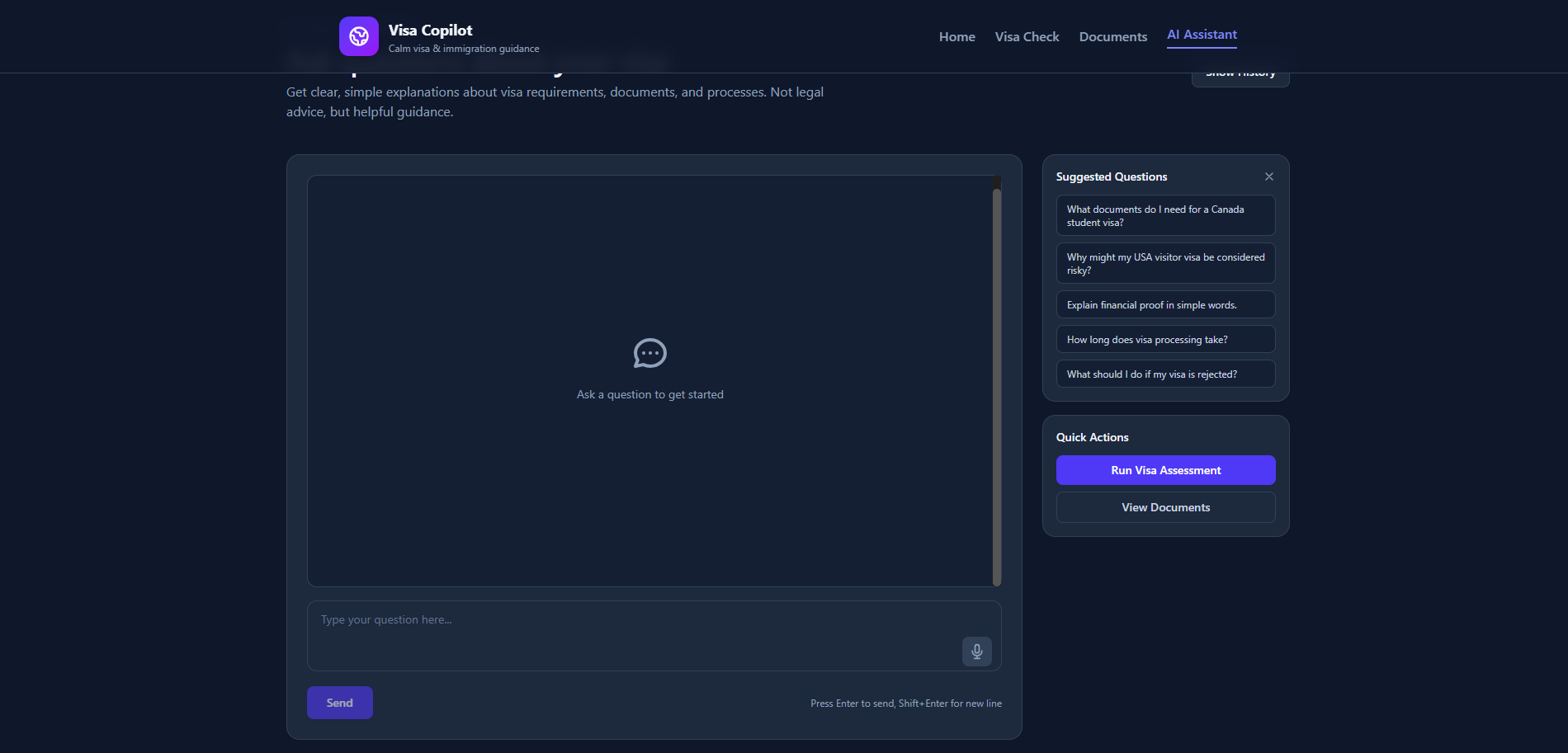
3. AI Assistant
- Natural language Q&A interface
- Context-aware responses using RAG
- Multilingual support
- Related questions generation
- Conversation history and bookmarking
- Text-to-speech for accessibility
- Export conversations (text/JSON)
Technical Implementation
RAG Implementation (src/lib/rag.ts):pt
// Semantic search using cosine similarity
const queryEmbedding = await embed(userProfile);
const scoredRules = await Promise.all(
rules.map(async (rule) => {
const ruleEmbedding = await embed(rule.text);
const score = cosineSimilarity(queryEmbedding, ruleEmbedding);
return { rule, score };
})
);
return scoredRules.sort((a, b) => b.score - a.score).slice(0, topK);AI Integration (src/app/api/analyze-profile/route.ts):
- Validates user input with Zod schemas
- Retrieves relevant rules via RAG
- Constructs prompt with system instructions, retrieved context, and user profile
- Generates structured JSON response (eligibility, checklist, risks)
- Handles markdown code block stripping from Gemini responses
Document Processing Pipeline:
- File validation (type, size, malware scanning ready)
- Preview generation for images and PDFs
- OCR text extraction (mock implementation, ready for Tesseract.js/Cloud Vision)
- Document classification using filename patterns and content analysis
- Field extraction with regex patterns and confidence scoring
- AI analysis via
/api/analyze-documentsendpoint
Production-Ready Features
Even as a hackathon project, we built with production in mind:
- Rate Limiting: Per-endpoint rate limits (20/min for assessments, 50/min for chat)
- Caching: Multi-layer caching (semantic cache for AI responses, API response caching)
- Error Handling: Comprehensive error handling with user-friendly messages
- Security: CORS, security headers, input sanitization, GDPR compliance ready
- Monitoring: Metrics tracking infrastructure (latency, tokens, quality scores)
- Accessibility: ARIA labels, keyboard navigation, screen reader support
- Performance: Service worker for offline support, code splitting, optimized assets
Challenges We Faced
Challenge 1: Balancing Accuracy with Simplicity
Problem: How do we ensure AI responses are accurate while keeping explanations simple?
Solution: We implemented a two-stage approach:
- RAG ensures responses are grounded in official rules
- Explicit prompt engineering instructs Gemini to use "8th-grade reading level" language
- Structured output format (eligibility, summary, explanation, checklist) ensures consistency
Challenge 2: Handling Missing or Incomplete Information
Problem: Users often don't know all required information upfront.
Solution:
- Made most fields optional with smart defaults
- Real-time validation guides users
- AI explicitly states when information is missing or uncertain
- Conservative assessments when data is incomplete
Challenge 3: Document Processing Complexity
Problem: Real OCR integration requires significant infrastructure (Tesseract.js server-side, Cloud Vision API costs).
Solution:
- Built a realistic mock OCR system that simulates real document extraction
- Designed the architecture to easily swap in real OCR services (Tesseract.js, Google Cloud Vision, AWS Textract)
- Focused on the AI analysis layer, which is the core innovation
Challenge 4: Token Limits and Cost Optimization
Problem: LLM API calls can be expensive, especially with long contexts.
Solution:
- Implemented semantic caching to avoid redundant API calls
- Limited RAG retrieval to top-4 most relevant rules
- Truncated document text to 2000 characters for analysis
- Used Gemini 2.5 Flash (faster, cheaper than Pro models)
- Cached common queries for 1 hour
Challenge 5: Multi-language Support
Problem: Users speak different languages, but our knowledge base is in English.
Solution:
- Added
preferredLanguageparameter to API - Prompt engineering instructs Gemini to translate responses
- UI supports language selection
- Ready for multilingual knowledge base expansion
What We Learned
Technical Learnings
RAG is Powerful but Requires Careful Design
- Chunking strategy matters—too small loses context, too large dilutes relevance
- Embedding quality directly impacts retrieval accuracy
- Cosine similarity works well for semantic search
- Top-K retrieval (K=4) provides good balance between context and token usage
Prompt Engineering is Critical
- Explicit instructions ("8th-grade reading level") significantly improve output quality
- Structured output formats (JSON schemas) reduce parsing errors
- Context ordering (system → rules → user profile) affects reasoning quality
- Handling markdown code blocks in responses requires defensive parsing
Production-Ready AI Systems Need More Than Models
- Caching is essential for cost and latency
- Rate limiting prevents abuse
- Error handling must gracefully degrade
- Monitoring helps identify issues early
Domain Learnings
Visa Requirements are Complex
- Requirements vary significantly by nationality, destination, and visa type
- Many rules are conditional ("may be required if...")
- Official sources are often ambiguous or hard to find
- There's a real need for personalized guidance
User Experience Matters
- People are anxious about visa applications—the UI must be calming and trustworthy
- Progress indicators reduce abandonment
- Clear explanations build confidence
- Actionable checklists are more valuable than generic lists
Impact and Future Vision
Current Impact
VisaAI demonstrates how AI can make complex bureaucratic processes accessible:
- Democratizes Access: Free, AI-powered guidance available to anyone
- Reduces Errors: Automated document analysis catches issues before submission
- Saves Time: Instant eligibility assessment vs. hours of research
- Improves Outcomes: Risk flags help users address problems proactively
Future Enhancements
Expanded Coverage
- More countries (UK, Australia, Germany, etc.)
- More visa types (work, business, permanent residence)
- Real-time rule updates from official sources
Enhanced AI Capabilities
- Fine-tuned models for visa domain
- Multi-modal support (image analysis, PDF parsing)
- Advanced hallucination detection
- Automated prompt optimization
Production Infrastructure
- Real OCR integration (Tesseract.js or Cloud Vision)
- Vector database (Pinecone/Weaviate) for scalable RAG
- Redis for caching and rate limiting
- Database for user profiles and document storage
- Monitoring dashboard (Sentry, Datadog)
User Features
- User accounts and saved profiles
- Application tracking and reminders
- Integration with official government portals
- Community features (success stories, tips)
Technical Stack Summary
- Frontend: Next.js 16, React 19, TypeScript, Tailwind CSS 4
- Backend: Next.js API Routes, Node.js
- AI/ML: Google Gemini 2.5 Flash, Google Generative AI Embeddings
- Validation: Zod
- Deployment Ready: Vercel, Docker-compatible
- Architecture: RAG, semantic caching, multi-layer caching
Conclusion
VisaAI represents our vision of using AI to break down barriers to global mobility. By combining RAG technology with user-centered design, we've created a tool that makes visa applications less intimidating and more accessible.
This hackathon project is just the beginning. We're excited to continue building, expanding coverage, and helping more people navigate their visa journeys with confidence.
Built With
- gemini
- next.js
- node.js
- rag
- tailwand
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.