-
-

UI prototype (designed with Figma)
-
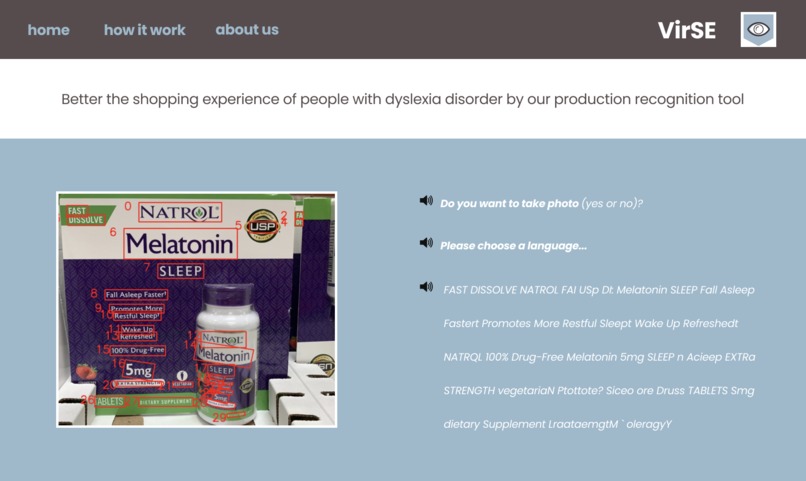
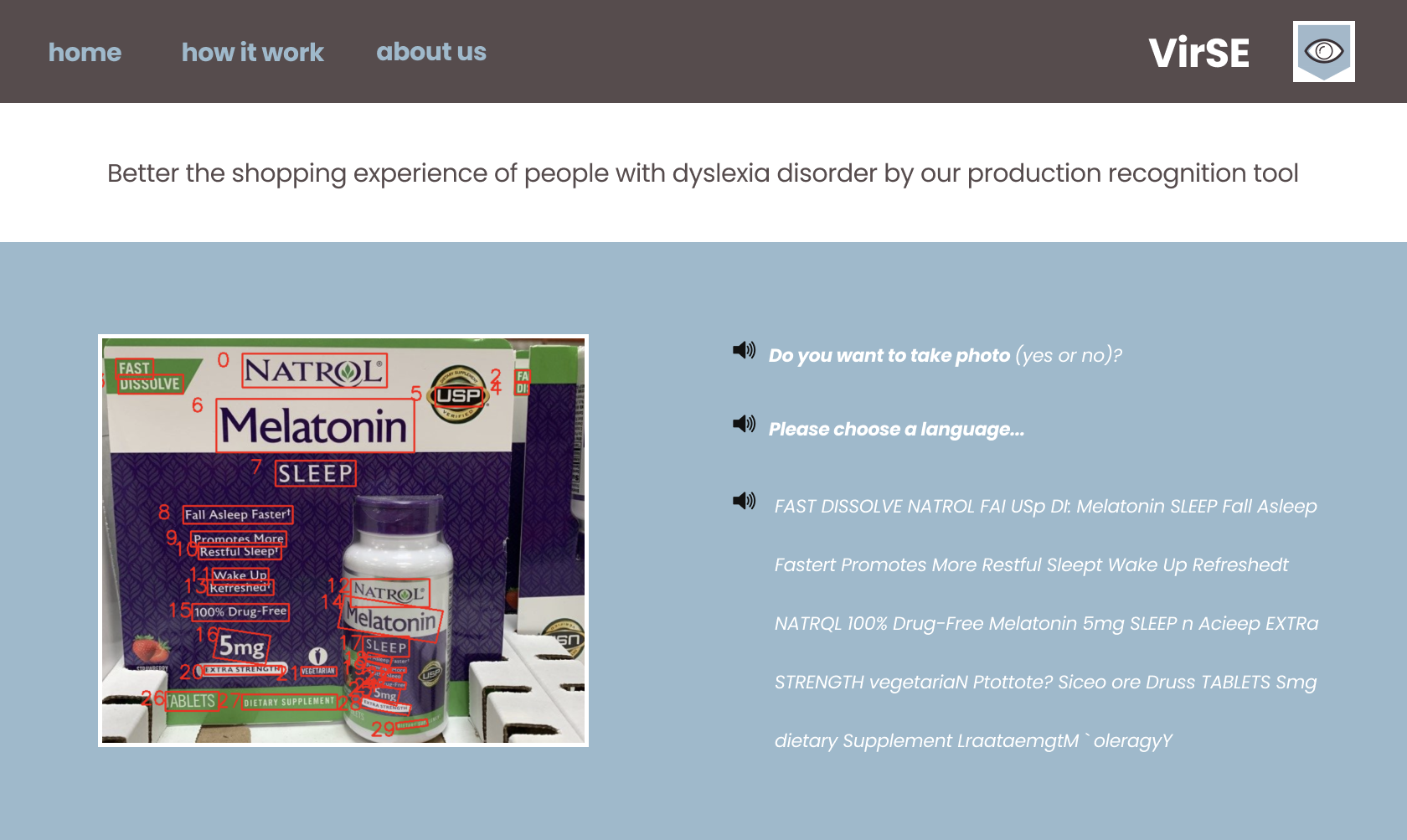
Homepage prototype (designed with Figma)
-
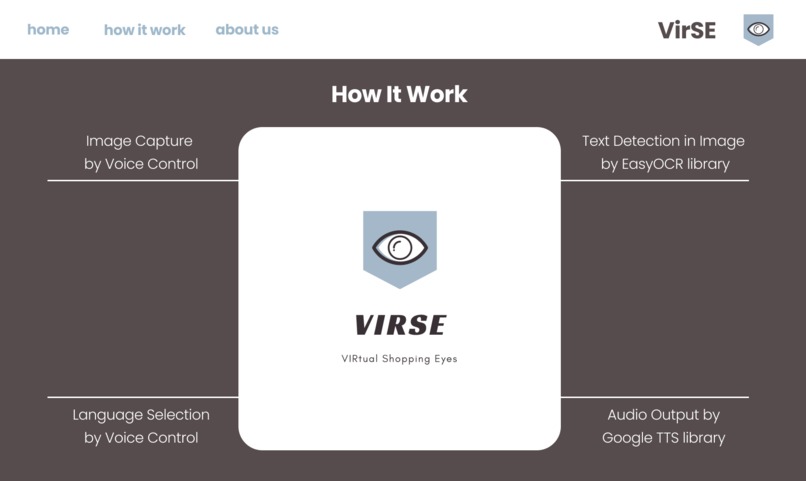
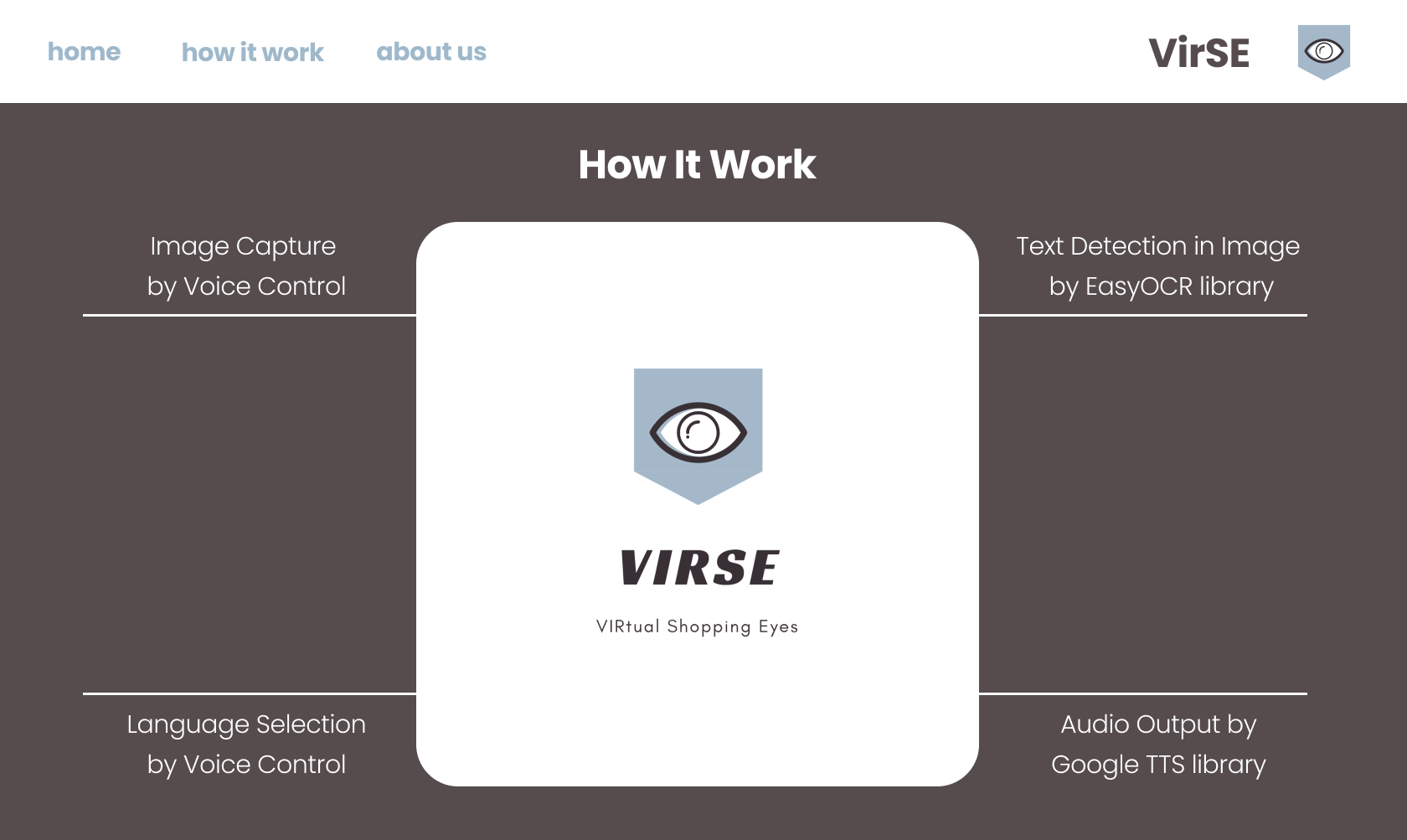
How it work page prototype (designed with Figma)
-

VirSE cover photo
-

VirSE logo



Inspiration
Learning disabilities, especially dyslexia, are one of the most pressing issues of developmental psychology that concern lifelong accessibility and special accommodations on a daily basis. Dyslexic people do not only struggle with reading and writing, but also suffer from disrupted memory, concentration, organization, communication, and other everyday routines. Specifically, Ferrer, Shaywitz, Holahan, Marchione, & Shaywitz (2010) remarked that poor reading and spelling hindered the most basic literacy-based activities such as reading product labels in a supermarket — thus, dyslexic people would experience constant high-stress levels in their daily lives, especially in normal grocery shopping activities. Nonetheless, intellectually disabled people often face challenges with lacking on-site assistance from supermarket staff and negative attitudes of other customers, particularly on super hectic days.
Some brief statistics regarding dyslexia:
- 15% of the U.S. population (50 million Americans) has dyslexia (U.S. Department of Health and Human Services)
- At least 5-10% of the global population (700 million people worldwide) experience dyslexia (Dyslexia International, 2017)
- Dyslexia will cost the U.S. $12 billion (2020) and $1 trillion dollars over the next 60 years (Boston Consulting Group & University of California - San Francisco Dyslexia Center)
- Only 14% of U.S. students received special education services and 80% of them identified as having dyslexia (National Center for Education Statistics, 2019).
The solution:
With the prevalence and lifelong implications of dyslexia, we built VirSE to help dyslexic people with less stressful and more effective grocery shopping – their bare necessities in daily life.
What it does
VirSE is a product recognition tool that betters the shopping experience for people with dyslexia by reading out loud the information featured on each product.
Through the combination of cutting-edge technology including Optical Character Recognition (a machine vision capability), Text-To-Speech (a read-aloud-text technology), and Speech-To-Text (a voice recognition extension that helps convert speech to digital text), VirSE allows users to capture the image of different products via voice control or via a clickable button on the GUI. Afterward, the tool will process to spot readable text and transmogrify it into speech. Our product also supports multiple languages, and users can choose the prospective languages to be recognized via voice control.
How we built it
We developed an image reader GUI using Tkinter, a standard GUI package for Python. Our first approach was to control the camera using a static button. Then, we decided to integrate Cloud Speech-to-Text API with our GUI so that users can tell the application to read an image via voice control. We believe this upgraded technique will make the interaction between people with reading difficulty and VirSE as intuitive and fluid as possible.
For text detection in image functionality, we utilized an open-source Python library called EasyOCR which allows image conversion to text in 80+ supported languages. Afterward, we implemented a piece of code to clean the text output by the OCR reader. Then, we used Cloud Text-to-Speech (gTTS) to turn the digital text into spoken words.
We also designed and created a UI prototype for our web application using Figma, and the beta version of our website is in the development process. We are testing out two different solutions for the front-end, which are React and Bubble.
Challenges we ran into
We spent a considerable amount of time dealing with open-source APIs. Since our team members are using different operating systems (i.e., macOS, Windows, and Ubuntu), and each of us is working on particular functionalities of the app, we needed to collaborate to help each other install required libraries and combine our codes.
Another challenge for our team was regarding the camera resolution. Since low-quality images (e.g., crinkled packages or words shadowed by poor lighting) cause the text detection library to produce inaccurate outputs, we needed to add the code to preprocess the taken image before calling the OCR reader. Additionally, because none of the team members had a powerful enough GPU on personal devices, we needed to run the OCR API on our CPU. Therefore, the tool was running a bit slower than our expectations.
Accomplishments that we're proud of/What we learned
After choosing this topic for the final product, we learned more about dyslexia and other neuropsychological disorders that are so common in our daily lives, but barely anyone knew their prevalence and provided support for those in need. We also learned to be more cognizant of neurodiversity, inclusion, and equity, and most of all, to be aware of our privileges and capacities to access various resources. This ability should not be normalized and taken for granted, especially for dyslexic people who have to face problems with accessibility every moment of their life. We also learned that many hackathon projects and startups often focused on more visible disabilities such as visual or hearing impairments but rarely neurological learning disabilities.
Additionally, as a team of amateur developers, we are proud to learn new Python APIs (e.g., EasyOCR, gTTS, SpeechRecognition) that we have never experienced before! We also learned more about developing GUI by Tkinter and found many future potentials with these tools in developing more user-friendly and socially innovative products to solve current challenges in our modern world.
What's next for VirSE
Ideally, we hope to continue improving the accuracy and speed of VirSE in the next few weeks, particularly with image processing. Our future benchmark would be 10 seconds after reading product images to enhance the experience of dyslexic shoppers, making shopping the least time-consuming, disoriented, and stressful activity on a daily routine.
Since we noticed that EasyOCR supports 80+ languages and Cloud Speech-to-Text API supports 40+ languages, we can see the potential of multi-language implementation with enormous datasets. We already tested our application in Vietnamese, but due to the short time span of this project, we are unable to finish the multi-language feature for our beta version. We will enhance this feature with large-scale surveys and data collection to generate as accurate spelling and pronunciation as possible.
Finally, we will try to complete the front-end solution for the web application and start working on the mobile version. The Figma prototype would be a great start for us to think of UI/UX design. We will try to make the web and mobile app free and easy to use for most users.







Log in or sign up for Devpost to join the conversation.