-
Initial Welcome Page
-

ScrollView of different plans offered by the company.
-
User input Form
-
User's View when one is entering data.
-
Loading Screen(waiting for result)
-

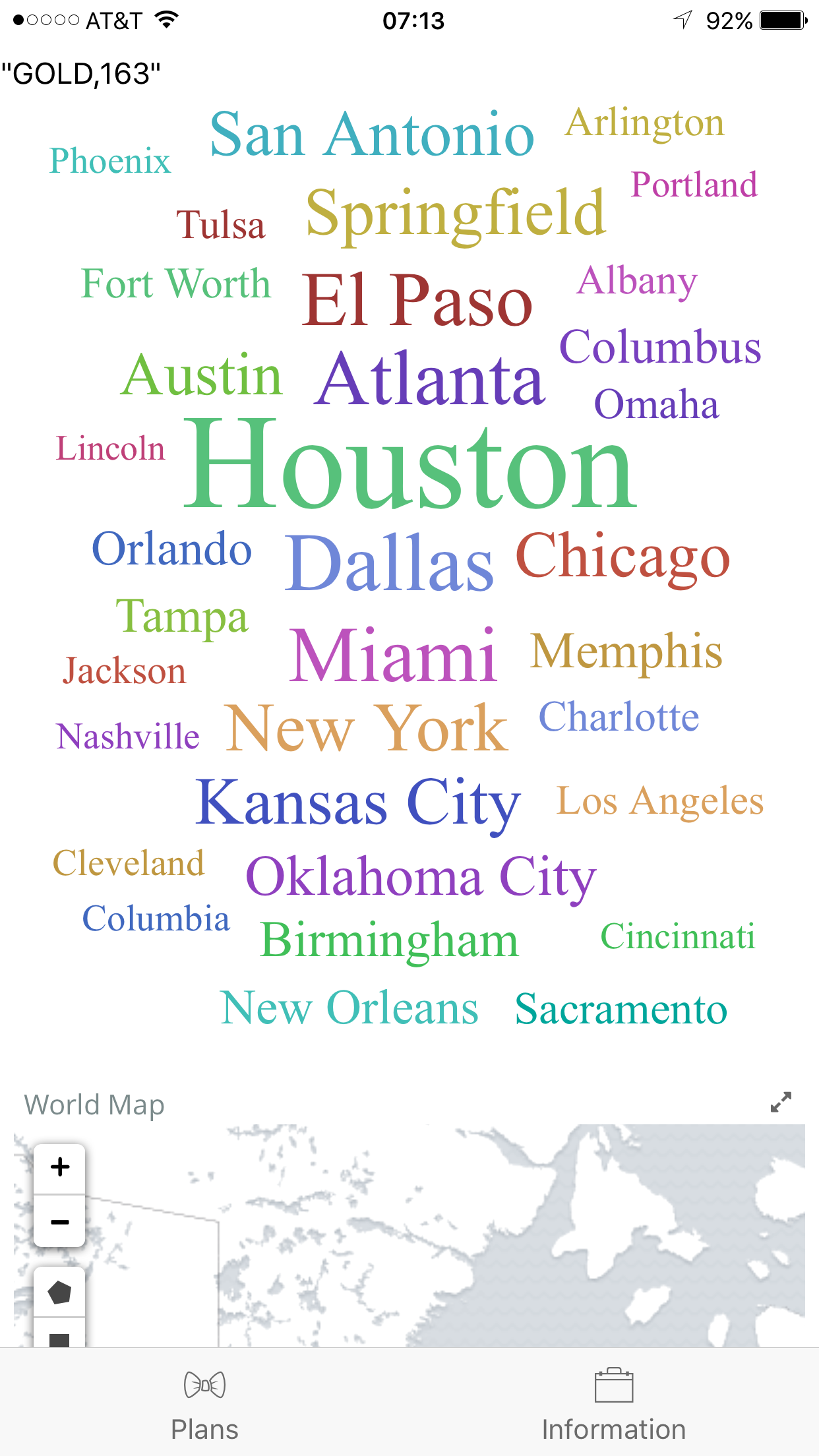
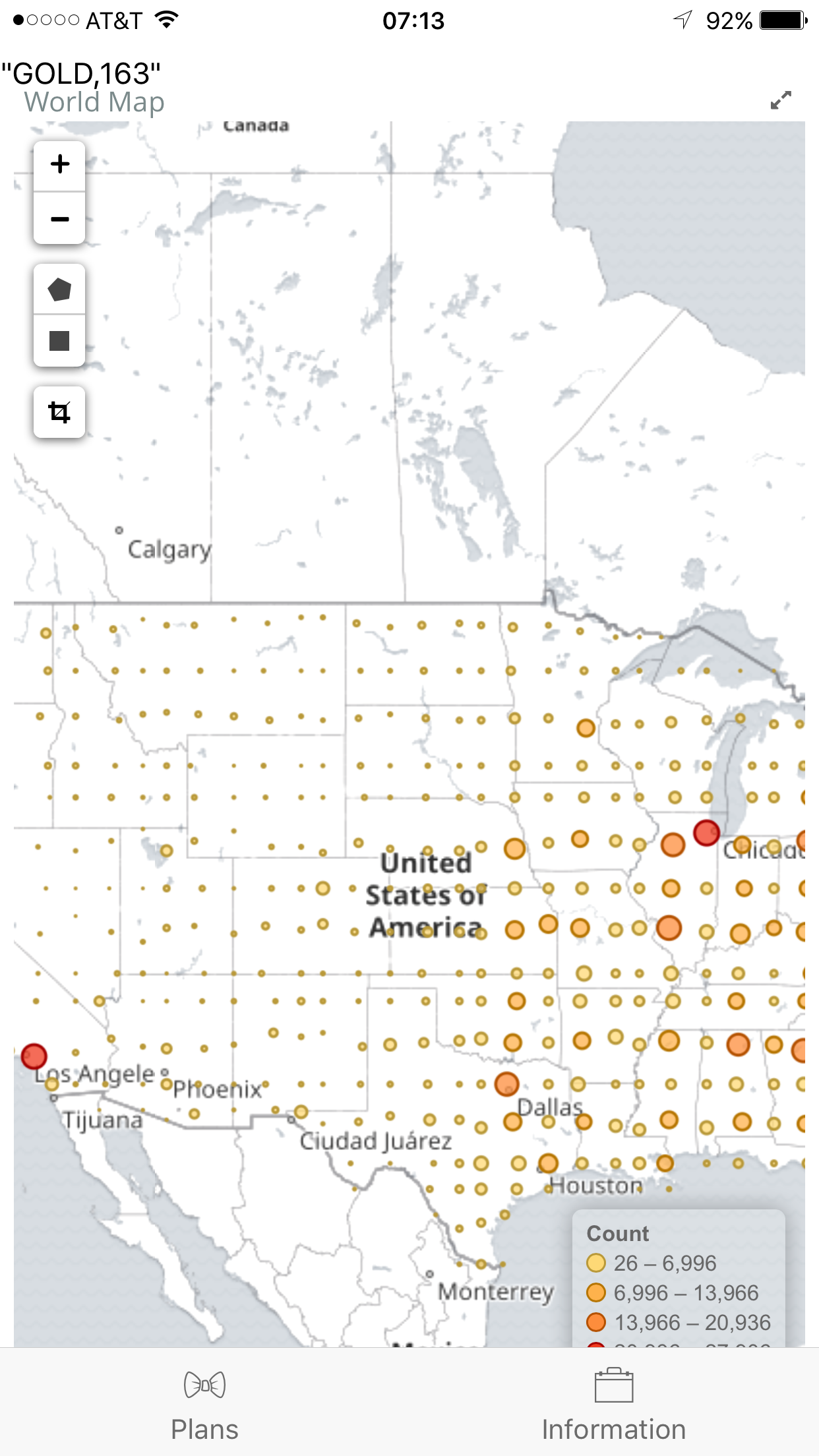
Participants from? (Size according to the population of participants in the certain region!)
-
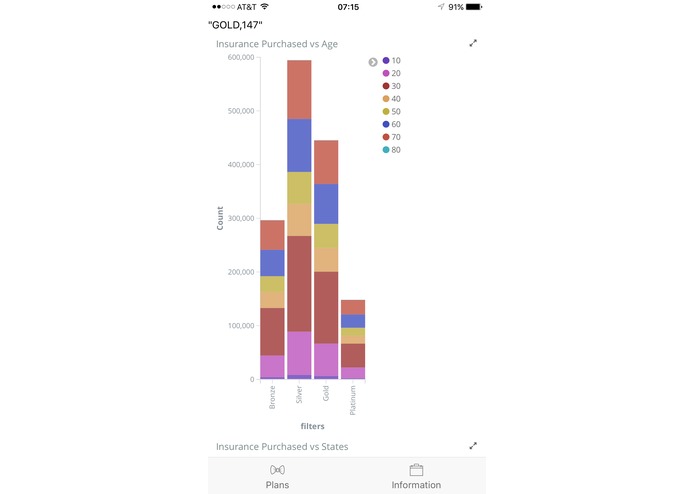
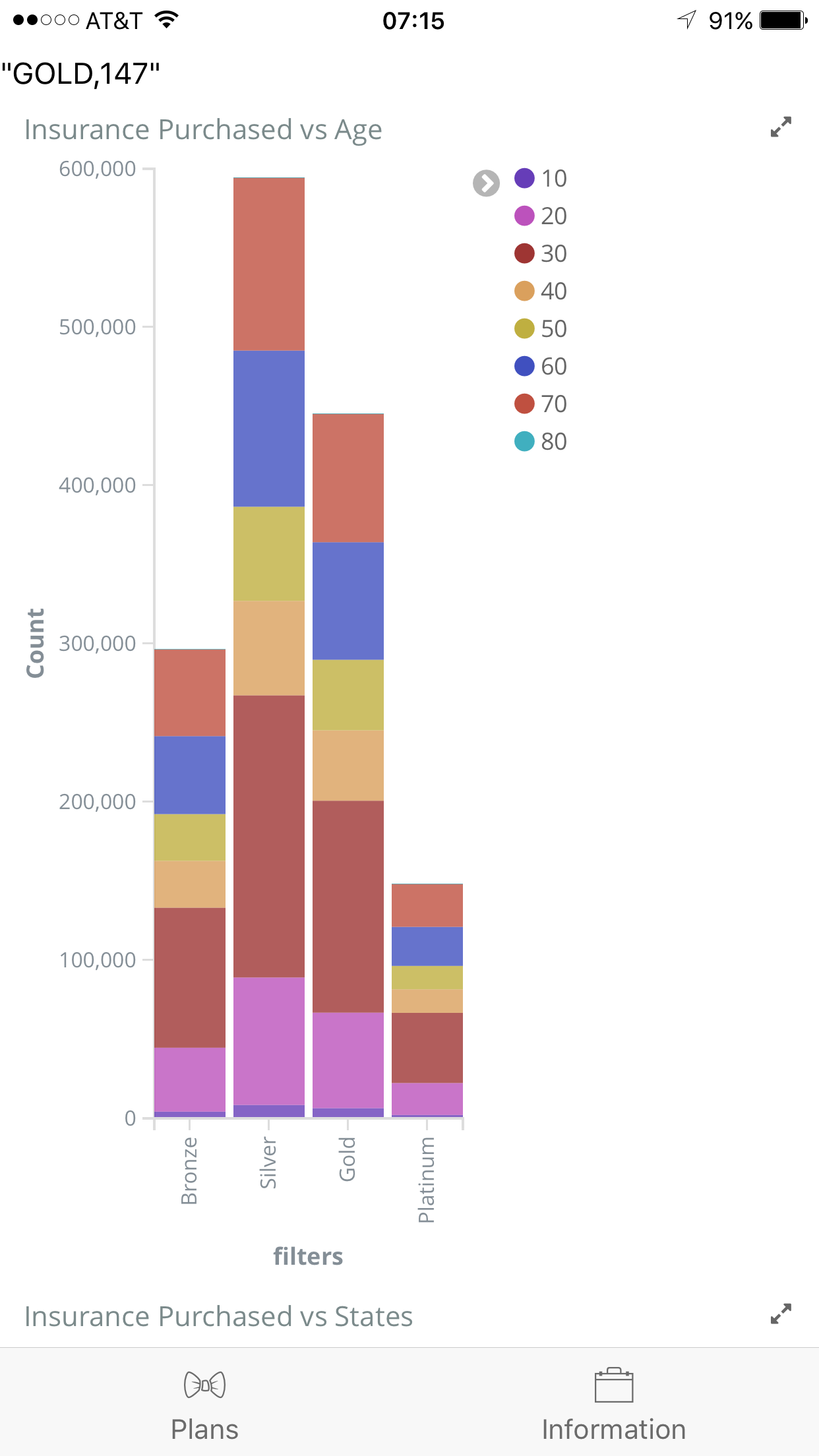
Data
-
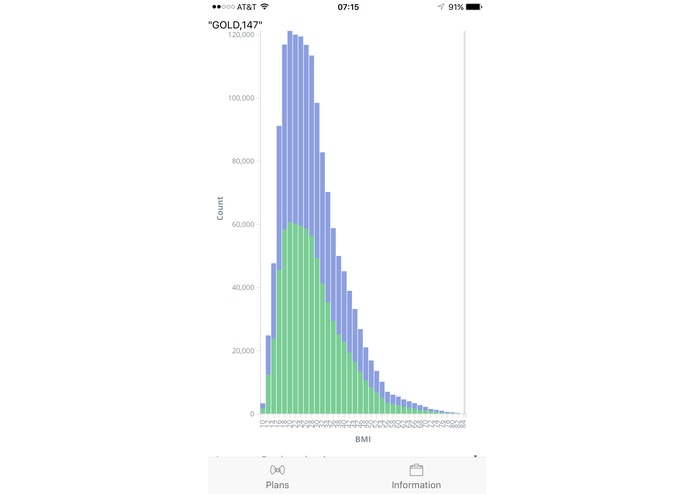
Data
-
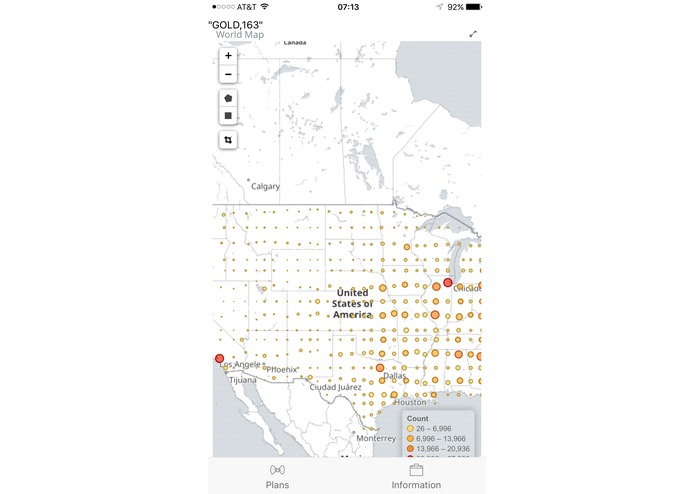
Data
-
Side bar







Inspiration
We are inspired by how Machine Learning can streamline a lot of our lives and minimize possible errors which occurs. In the healthcare and financial field, one of the issues which happens the most in the Insurance field is how to best evaluate a quote for the consumer. Therefore, upon seeing the challenge online during the team-formation period, we decided to work on it and devise an algorithm and data model for each consumers, along with a simple app for consumers to use on the front end.
What it does
Upon starting the app, the user can check to see different plans offered by the company. It is listed in a ScrollView Table and customers can hence have a simple idea of what kind of deals/packages there are. Then, the user can proceed to the "Information" page, and fill out their personal information to request a quotation from the system, where the user data is transmitted to our server and the predictions are being made there. Then, the app is returned with a suitable plan for the user, along with other data graphs to illustrate the general demographics of the participants of the program.
How we built it
The app is built using React-Native, which is cross-platform compatible for iOS, Android and WebDev. While for the model, we used r and python to train it. We also used Kibana to perform data visualization and elasticsearch as the server.
Challenges we ran into
It is hard to come up with more filters in further perfecting our model with the sample data set from observing the patterns within the data set.
Accomplishments that we're proud of
Improving the accuracy of the model by two times the original that we started off with by applying different filters and devising different algorithms.
What we learned
We are now more proficient in terms of training models, developing React Native applications, and using Machine Learning in solving daily life problems by spotting out data patterns and utilizing them to come up with algorithms for the data set.
What's next for ViHack
Further fine-tuning of the recognition model to improve upon the percentage of correct predictions of our currently-trained model .
Built With
- amazon-web-services
- aws-lambda
- brew
- csv
- elasticsearch
- expo.io
- google-cloud
- google-drive
- javascript
- json
- kibana
- machine-learning
- npm
- pip
- python
- r
- react-native
- yarn









Log in or sign up for Devpost to join the conversation.