-
-
github repository image 2 of vigilens
-
github repository of vigilens
-
VS code terminal of vigilens
Inspiration
Vigilens was born from a simple realization: for those living with dementia, the world doesn't just become forgetful—it becomes unrecognizable. Everyday objects like a glasses case or a smartphone become puzzles, and simple tasks become insurmountable barriers. I wanted to build more than just an AI; I wanted to build a "Multimodal Cognitive Anchor." My goal was to create a tireless, empathetic companion that sees through the patient's eyes and speaks with the heart of a caregiver, providing real-time clarity without the need for a screen or keyboard.
What it does
Vigilens is an ambient AI assistant designed for the future of wearable dementia care. By tapping into the Gemini Live API, it provides: Instant Visual Recognition: A patient can hold up an object and ask, "Vigilens, what is this?" to receive an immediate, comforting answer. Contextual Guidance: It identifies visual cues to help guide users through daily routines, acting as an external memory bank. Clinical Empathy: The persona is specifically tuned to be concise, calm, and supportive, reducing the anxiety often associated with memory loss.
How I built it
I engineered the core of Vigilens using Python 3.11 and the Google GenAI SDK, targeting the gemini-2.0-flash model for its low-latency multimodal capabilities. The technical backbone relies on a complex asynchronous architecture. To handle the high-bandwidth requirements of 16kHz audio and 1-FPS live video, I built a custom asyncio state machine. This allows the system to maintain a bidirectional WebSocket connection while simultaneously processing heavy computer vision data via OpenCV.
Challenges I ran into
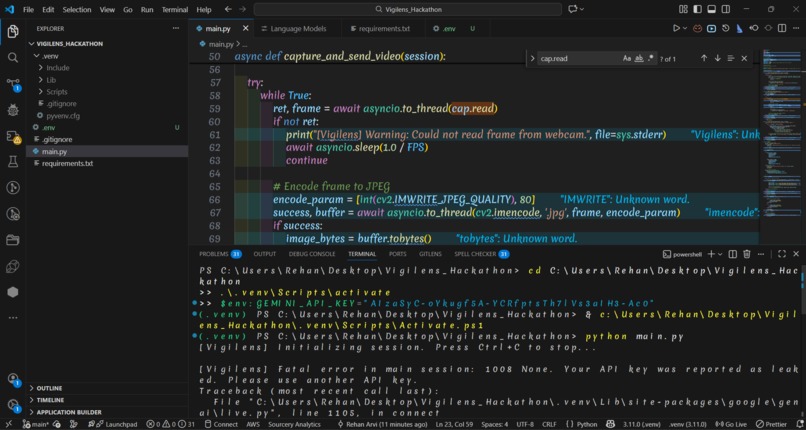
Building in a vacuum is easy; building for real-time interaction is a battle against "Event Loop Starvation." I faced a significant hurdle where blocking I/O operations—like waiting for camera frames—would starve the main loop and drop the AI’s connection. I solved this by implementing a threaded execution model using asyncio.to_thread. This ensured that the "heartbeat" of the AI stayed alive, even while the system was crunching base64-encoded video frames.
Accomplishments that I'm proud of
I am most proud of achieving a stable, live interaction where the AI can "see" and "speak" simultaneously with minimal delay. Tonight, I successfully bridged the gap between a high-level LLM and low-level hardware control, creating a prototype that actually works in the high-pressure environment of a live demo.
What I learned
This project taught me the true depth of Asynchronous Programming. Beyond the code, I learned the importance of "Persona Engineering" in medical AI. I discovered that when building for vulnerable populations, the speed of the answer matters just as much as the tone of the voice.
What's next for Vigilens
The roadmap is clear: moving from a laptop to AR Smart Glasses. I plan to transition to a WebRTC pipeline to handle background noise in real-world clinical settings and integrate a local Silero VAD model. This will optimize token usage and ensure that Vigilens is always ready to help, even in the busiest environments.

Log in or sign up for Devpost to join the conversation.