


Inspiration
Today, misinformation spreads quicker than you can say “retweet.” Staying informed has never been more crucial—or more challenging. Social media platforms can be powerful tools for connection, but they’ve also become battlegrounds for accuracy, where misleading claims and manipulated information thrive. We built Vigilante to change that.
In addition to being driven towards working on projects that solve real-world problems, each of our teammates are incredibly passionate about human-computer interaction—how technology and innovation overlaps with the human experience. We came across a paper published in the journal Science where researchers leveraged AI chatbots to combat belief perseverance (DOI: 10.1126/science.adq1814). As solution-centric engineers, we saw endeavors like these as validation that AI can be a powerful tool to fight entrenched misinformation and cognitive biases. We wanted to bring that power to the masses, leveraging AI to combat misinformation and improve media literacy in doing so. We chose to focus on misinformation on social media because it’s one of the defining challenges of our lives. Social media has the power to shape public discourse and individual belief systems. When placed in the wrong hands, it can be used as a tool for propaganda, sowing division and manipulating public opinion. For a demographic like ours, these points feel especially poignant and relevant. We were motivated by the idea of building a tool that could not only combat misinformation but also help foster media literacy—empowering users to think critically about what they read and engage with online.
What it does
Vigilante provides users with a real-time fact-checking workflow that allows them to effortlessly identify potential misinformation. The user’s entire Twitter feed is anonymously ingested and, using agentic AI workflows, verifies in real-time every single post. Posts are stripped of evocative or emotional language and are broken down into their individual claims; these claims are then verified using Perplexity's Sonar API to ground our analysis in up-to-date sources.
We do not flag every tweet you see as misinformation—rather, we carefully filter out opinions from statements, satire from misinformation. We also highlight when posts (and even specific claims) are, in fact, accurate and supported by evidence.
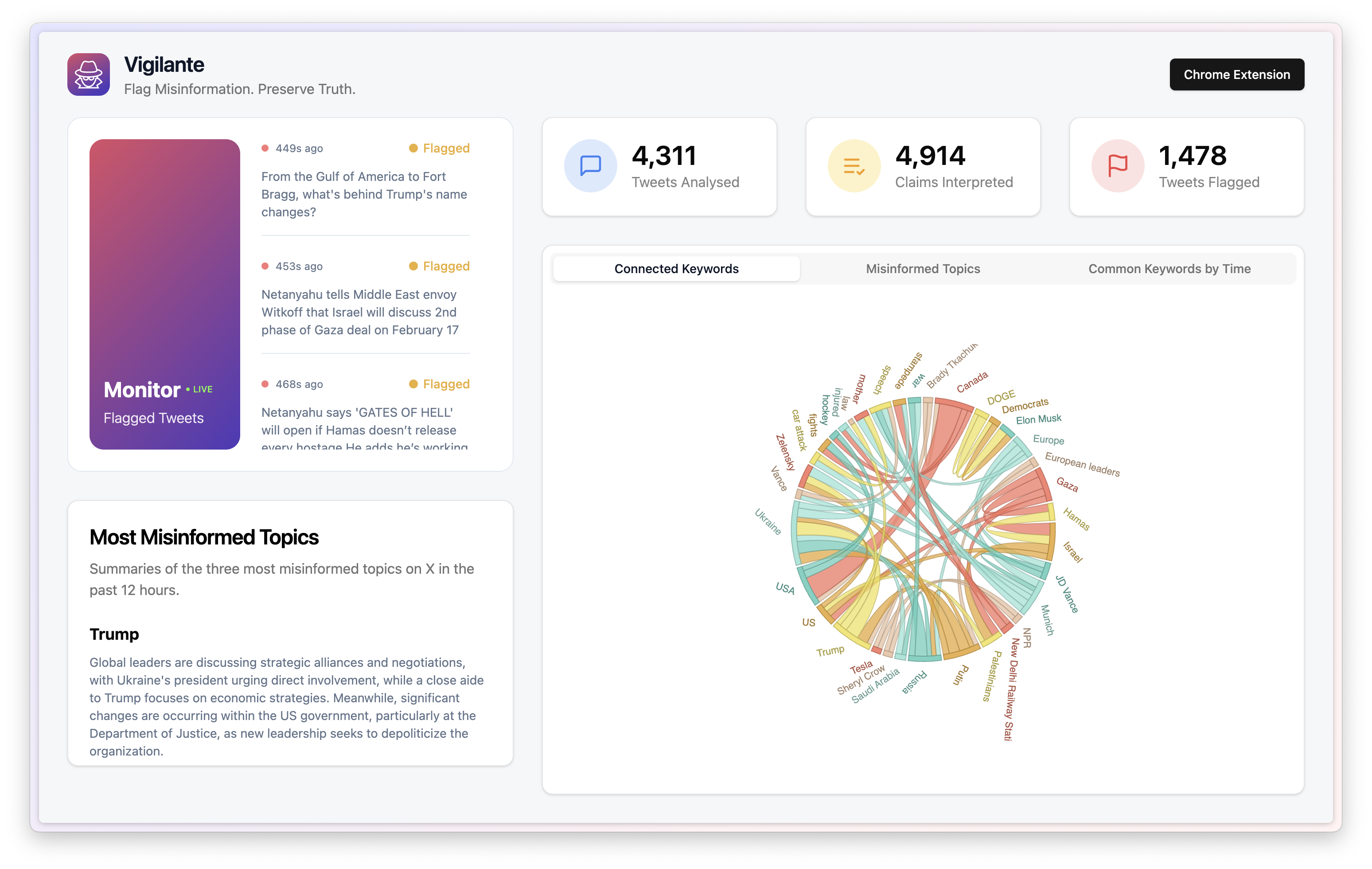
Using Vigilante, in addition to staying informed through your feed, you also help contribute to a crowdsourced database of tweets, their metadata, and analyses. This data lives on a dashboard that visualizes ongoing trends in misinformation on social media using data science and NLP techniques. This publicly available dashboard provides its audience with insights into what topics to be wary of online, all the while helping to tune your media literacy and stay on top of misinformation.
How we built it
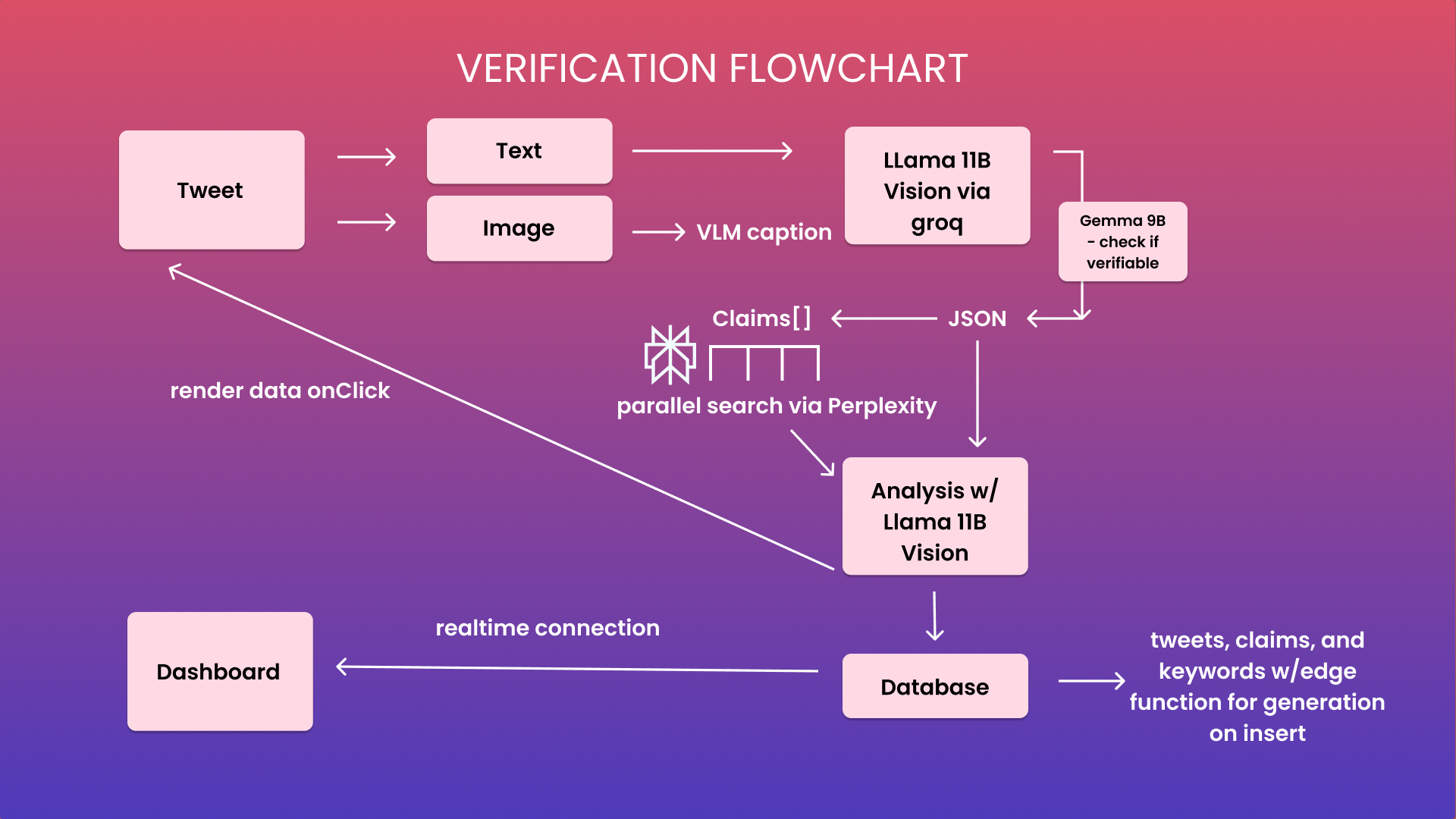
Vigilante exists in 3 parts: a Chrome extension, the fact-checking engine, and a data visualization dashboard. The fact-checking engine, as well as routes for interfacing with our database stored in Supabase, is exposed via a FastAPI backend. The FastAPI backend supports data queries and analysis for the dashboard, and the model routing and plumbing for our verifier. We deploy and expose our backend for production on Koyeb.
The Chrome Extension is built using Plasmo as a framework, with React/Tailwind for frontend. We implemented details like caching tweets client-side and using Plasmo messaging to bypass standard Chrome popup styling. The dashboard uses Next/React/Tailwing as scaffolding, and D3 for data visualizations. We also support real-time updates on the dashboard using a combination of technologies. For regular updates to overall statistics (i.e. number of tweets and claims analyzed), we leverage the Stale-While-Refresh technique through the useSWR hook in React. For live updates on new tweets flagged by our system, we loop in Supabase real-time messaging and listen for table insertions in the database.
The fact-checking engine is built on top of multiple AI technologies. To ensure the best UX as possible, it was imperative the system exhibited the lowest amount of latency as possible. To accomplish this goal, we leveraged Groq’s blazing fast inference API. We use 3 different language models across the system, each of which excelled in different tasks: gemma2-9b-it, llama-3.1-8b-instant, and llama-3.2-11b-vision-preview. We specifically use the vision model to endow the system with multimodal capabilities, allowing it to handle posts with text, images, and/or video, since each of these modalities are critical to a post’s core meaning. To evaluate a post’s claims, we leverage the new Perplexity Sonar Pro model to both search the web for evidence and provide an explanation for whether a claim is accurate or misleading. This process is also completely parallelized for each claim embedded within the text of a post, allowing for as fast of a system as possible.
Challenges we ran into
Our team is all super passionate about this problem space, but the initial hours of our work on this project was somewhat fragmented as we weren’t aligned on specific details. We went on a variety of fruitless goose chases, and didn’t settle on a specific vision for our project until we were deep in the weeds of it half-way through. (For instance, we toyed around with the idea of incorporating datasets of tweets from past election seasons and had even built out some visualizations, but ultimately chose not to pursue that path.) Ultimately though, we were able to rally and refocus on our vision—moving away from disorganized prototyping to a specific actionable gameplan.
One specific issue we ran into was brainstorming visualizations for the dashboard. We all had different ideas for how we envisioned the dashboard, and we initially found ourselves working independently on designing visualizations and developing data processing pipelines. However, when we synced up, we realized our visions had all largely diverged from each others’. Though it isn’t inherently bad to have competing ideas, it was difficult for us to reconcile a common vision once we had all individually put so much thought into our own. Once we put our heads together, however, we developed a cohesive plan for not only this dashboard, but our project altogether. This taught us the importance of early alignment and continuous collaboration—syncing frequently and creating a shared vision early on can save time and reduce duplicated or divergent efforts.
A more technical issue we encountered was not being overly skeptical of (what we thought were) good results from our system. The fact-checking system went through numerous rounds of iterations (archived as a Python notebook in our repo) and we had a working prototype that we implemented into our FastAPI backend. However, after performing a refactoring for additional features, we accidentally removed the call to the Perplexity API, a critical functionality, without us noticing. We took for granted that the system was still flagging tweets as “misleading” without actually checking to see whether its explanations were up to our standards. Thankfully we were able to catch this issue and resolve it in time before it got buried even further. We learned to not take surface level results for granted and to look deeper behind the scenes—which is quite fitting for this project altogether.
Accomplishments that we're proud of
One of our biggest accomplishments was our ability to iterate rapidly and improve upon multiple aspects of our system within a short timeframe. We took on significant technical challenges and addressed performance bottlenecks in our backend with creative, scalable solutions. Each iteration brought meaningful improvements, and we’re proud of how we managed to adapt and refine the system as we encountered new challenges.
Another accomplishment were particularly proud of is that we were able to incorporate multimodal fact-checking capabilities. “An image is worth a thousand words” is particularly true in the context of social media, so it was important that our system wasn’t restricted to only text input. However, this was not a simple challenge to solve. We chose to integrate llama-3.2-11b-vision-preview into our system to analyze claims that extend beyond simple textual information. This is a feat we consider a major leap forward in combating misinformation in multimedia-driven social platforms.
On another note of personal fulfillment, we’re proud of how we built a project that aims to address an incredibly pressing issue in today’s world. Navigating misinformation is shaping up to be one of the defining challenges of our lives; as social media platforms explore stripping away existing safeguards to prevent the spread of this sort of content, individuals have to be extremely vigilant with what they engage with online. Vigilante was built with this in mind, and we’re proud of how effective of an initial solution we’ve come up with to this problem.
What's next for Vigilante
After we recover from our sleep-deprived past 36 hours, we plan to publish the Vigilante Chrome extension to the Chrome Webstore. We also aim to continue to maintain the crowdsourced dashboard to effectively present the anonymous data we collect to the general public.
Beyond what we currently have built out, we plan to extend Vigilante’s functionality to mobile platforms. Apps for iOS and Android would provide fact-checking on-the-go and bring our technology to another form factor. Moreover, many users solely engage with social media on their phones, so it is important we can reach this audience as well.
We are also very interested in how we can better leverage the data our users provide for personal and community benefit. Meta and others have begun to cancel their fact-checking programs, and users often report negative experiences with features like “community notes” on X/Twitter. We suspect that we can leverage the data we’re collecting to reveal larger trends in misinformation and hopefully begin to prevent it before it spreads.
Altogether, we envision Vigilante as a tool that not only combats misinformation but also fosters a culture of critical thinking and informed engagement online. We’re excited to continue building after Treehacks, refining and scaling this platform to make a meaningful impact in the fight against misinformation.
Built With
- d3.js
- fastapi
- groq
- next
- perplexity
- plasmo
- postgresql
- python
- react
- supabase

Log in or sign up for Devpost to join the conversation.