Demo Link: https://vigil-fraud.vercel.app/
Inspiration
Canadian healthcare fraud represents $7.2 billion out of $26.6 billion in insurance benefits annually. Meanwhile, the average university student has over $2,000 in health and dental coverage through their student union plan that they've never touched.
We saw this firsthand. International students near campus getting billed $385 for a standard cleaning that the Ontario Dental Association fee guide prices at $120. Students who don't know what procedure code 43421 means, who can't read their own receipts, and who have no idea their tuition already pays for dental, vision, paramedical, and psychology coverage they've never claimed.
No tool exists that analyses healthcare billing from the patient's side. Insurance companies detect fraud from the payer's side. VIGIL flips the model: it protects the student.
What it does
VIGIL is a multi-agent AI system that analyses healthcare receipts uploaded by Canadian students. From a single receipt photo, it simultaneously:
- Detects billing fraud (upcoding, unbundling, phantom billing) by comparing procedure codes and fees against the ODA fee guide and provider history
- Discovers unused insurance benefits by mapping the student's claims against their UTSU Health & Dental Plan coverage
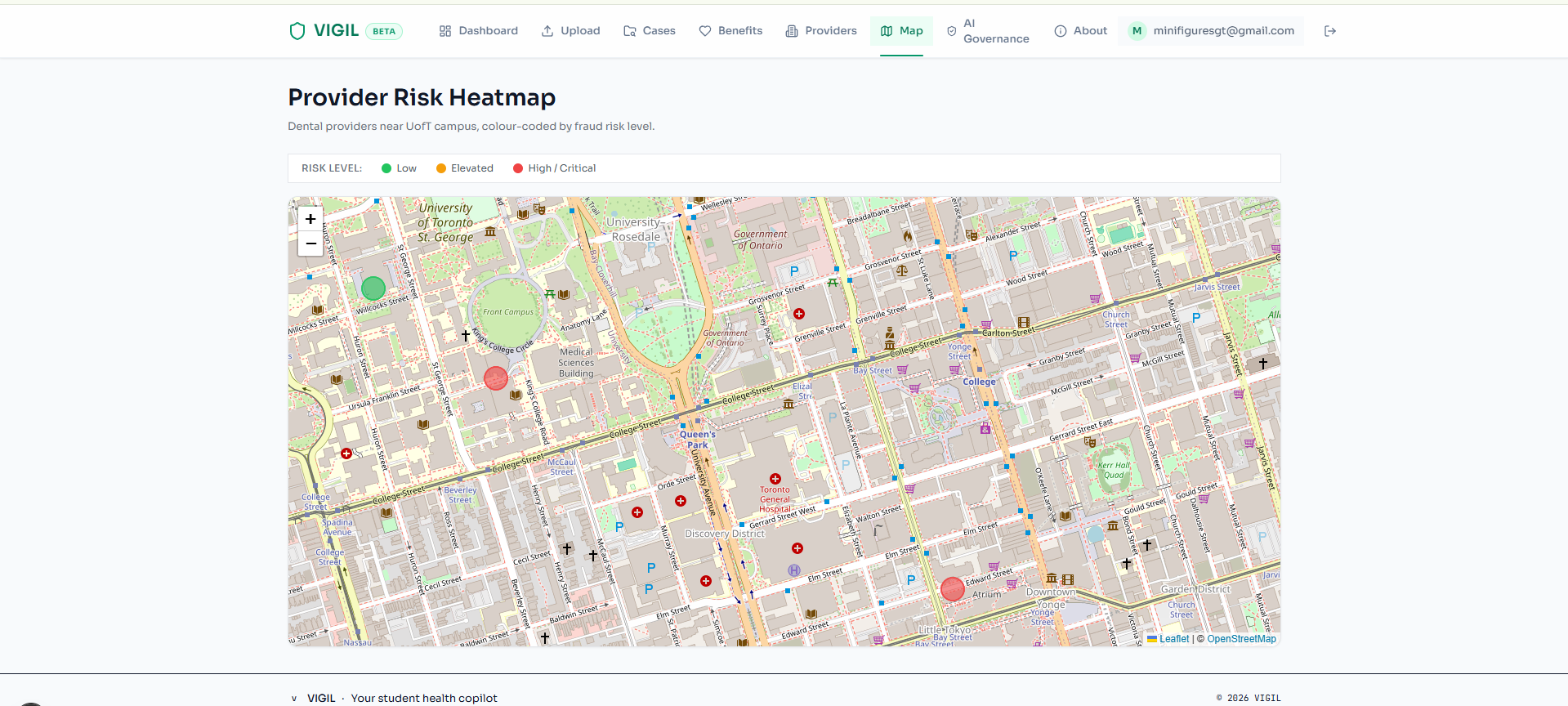
- Finds eligible clinics near campus with OHIP/UHIP coverage and trusted provider ratings
- Extracts health signals to track dental health patterns, medication adherence, and missed preventive care
The core insight: every healthcare receipt is both a financial transaction and a medical record. VIGIL analyses both at the same time through coordinated multi-agent reasoning.
How we built it
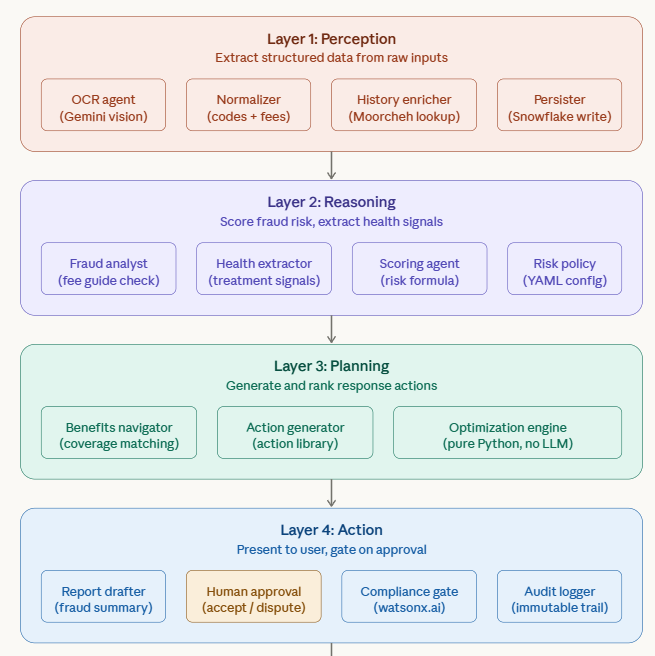
VIGIL uses a 5-layer, 14-agent pipeline inspired by cognitive architectures, orchestrated by LangGraph with parallel branching:
Layer 1 — Perception (4 agents)
A student uploads a receipt photo. The OCR Agent uses Gemini 2.0 Flash's multimodal vision to extract structured data: provider name, procedure codes, fees charged, and patient info. The Normalizer validates the extracted data, maps CDA procedure codes to their standard descriptions, and catches OCR errors. The History Enricher queries Moorcheh's episodic memory for past claims at this provider and the student's year-to-date coverage utilization. The Persister saves the validated claim to Supabase PostgreSQL for longitudinal analysis.
Layer 2 — Reasoning (3 agents)
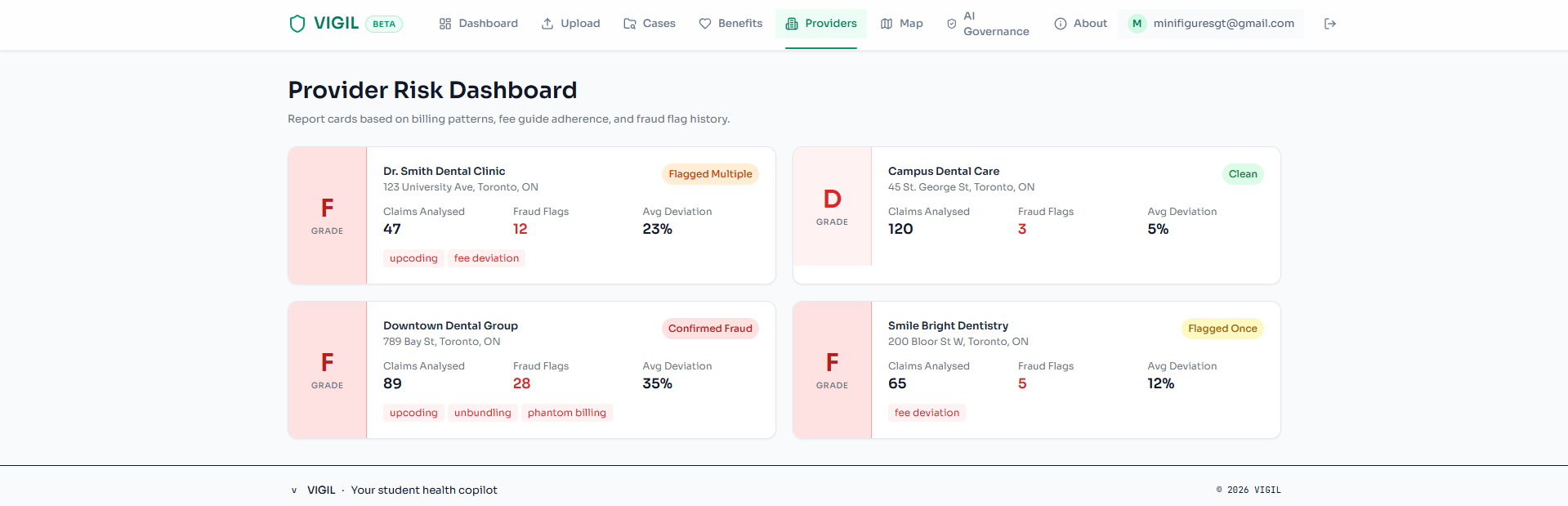
The Fraud Analyst and Health Extractor run in parallel via LangGraph's fan-out. The Fraud Analyst compares each procedure's billed fee against the ODA fee guide (with configurable 15%/30% deviation tolerances from fraud_policy.yaml), checks for upcoding patterns (e.g., scaling billed as root planing), and detects unbundling schemes (multiple scaling units that should be a single comprehensive cleaning). The Health Extractor logs treatment signals to Moorcheh memory, identifying gaps in preventive care and tracking treatment patterns over time.
The Scoring Engine is a pure Python module (no LLM) that computes a 0-100 fraud risk score using four weighted components: fee deviation severity (0-40 points), code risk weights ranked by NHCAA fraud typology (0-25 points), provider history flags for repeat offenders (0-25 points), and a pattern bonus when multiple concurrent flags are detected (0-10 points). All weights and thresholds are defined in a single YAML policy file, making the scoring transparent and auditable.
Layer 3 — Planning (3 agents)
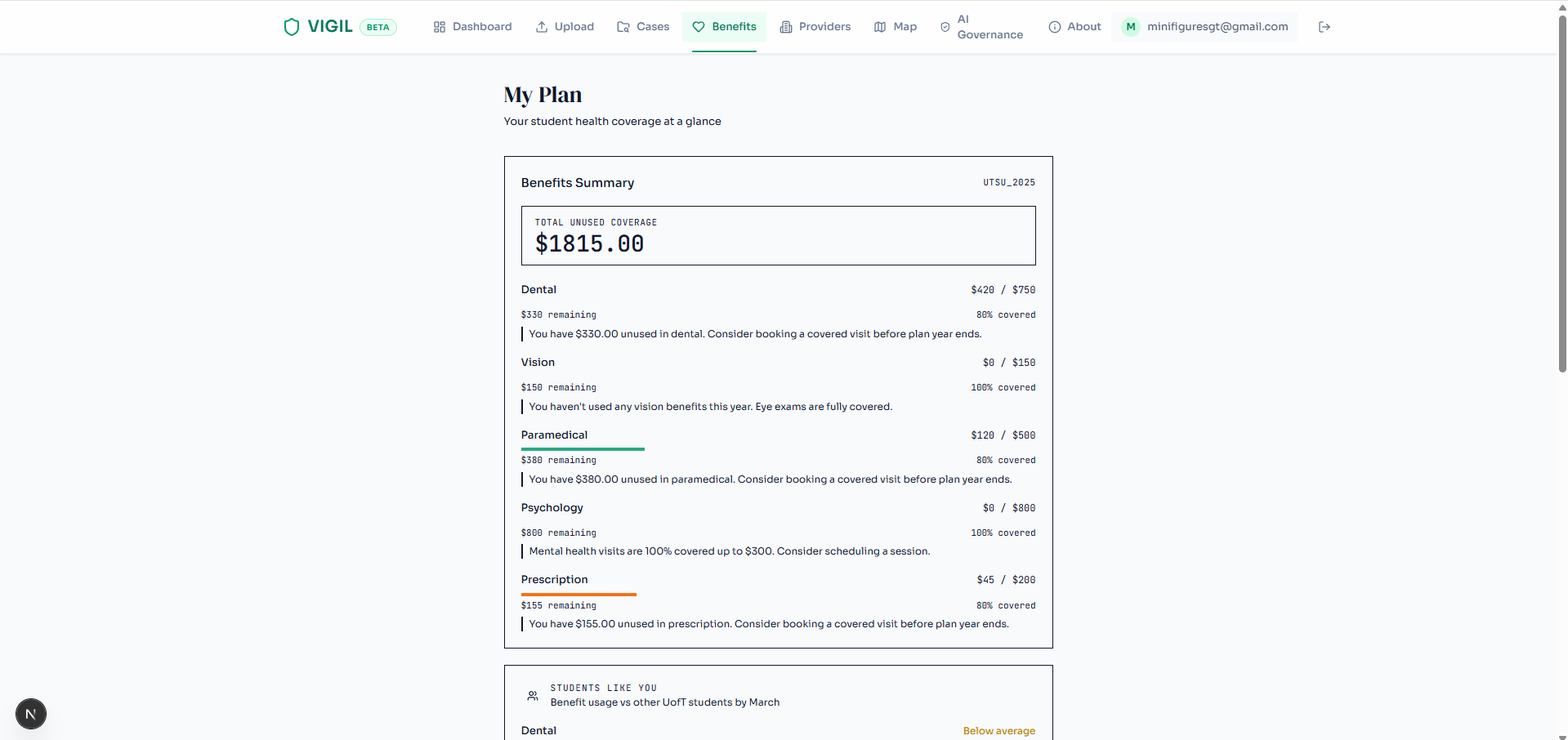
The Benefits Navigator queries Moorcheh's semantic memory for UTSU plan coverage details and computes how much unused coverage remains in each category (dental, vision, paramedical, psychology). The Action Generator proposes response plans: dispute the claim, switch providers, book a preventive visit to use expiring coverage. The Optimization Engine (pure Python, no LLM) ranks these plans by priority score based on financial impact and urgency.
Layer 4 — Action (3 agents)
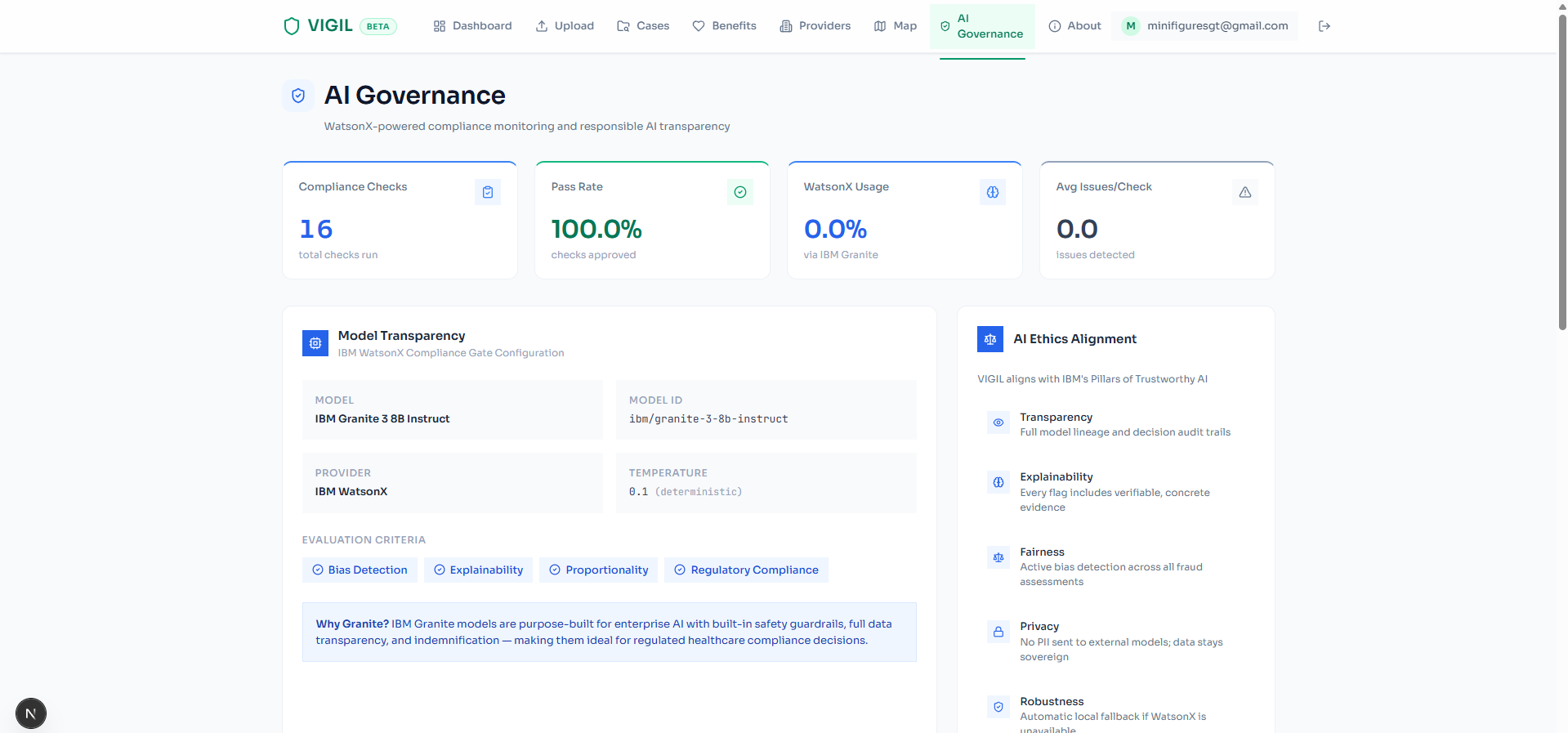
The Report Drafter generates a human-readable analysis with the animated fraud gauge, "What You Should Have Paid" comparison bars, and benefit utilization breakdowns. The Compliance Gate validates every fraud flag for explainability and bias before it reaches the student (optionally powered by IBM watsonx.ai). The Audit Logger records every pipeline decision to an immutable audit trail in Supabase, ensuring accountability and regulatory compliance.
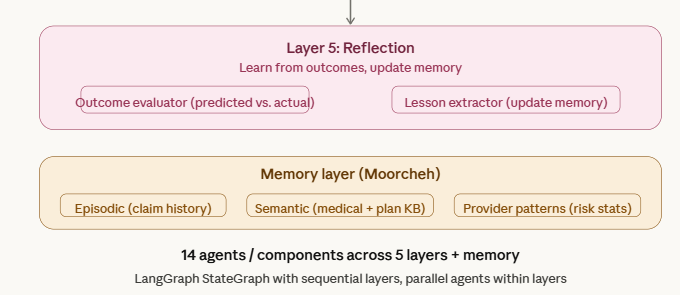
Layer 5 — Reflection (stretch goal, 1 agent)
The Outcome Evaluator and Lesson Extractor compare predicted vs actual outcomes when disputes resolve, updating provider risk scores in Moorcheh memory and improving future analyses through a continuous feedback loop.
Memory Layer
Moorcheh SDK powers three namespaces: episodic memory (student claim history and past interactions), semantic memory (ODA fee guide and UTSU plan documents for RAG), and provider patterns (aggregated risk statistics that accumulate over time and are updated by the reflection layer).
Frontend
Built with Next.js 14, ShadCN UI, and Magic UI for a polished student-facing experience. Features include an animated flickering grid hero, a fraud score gauge with animated circular progress, "What You Paid vs What You Should Have Paid" comparison bars, benefit usage progress bars with alerts for underutilized coverage, a clinic finder with OHIP/UHIP filters, a searchable ODA fee guide explorer, and a real-time agent trace panel showing the pipeline's cognitive layers processing in sequence.
Challenges we ran into
- Receipt OCR variability: Dental receipts have no standard format. We had to craft robust Gemini prompts that handle different layouts, handwritten notes, and partial information gracefully.
- Fee guide data access: The ODA fee guide is copyrighted and behind a member login. We compiled approximate fee data from publicly available dental clinic websites and published code references to build a representative demo dataset.
- Parallel agent coordination: Getting LangGraph's parallel fan-out (Fraud Analyst + Health Extractor running simultaneously) to correctly merge state without race conditions required careful state schema design with typed Pydantic models.
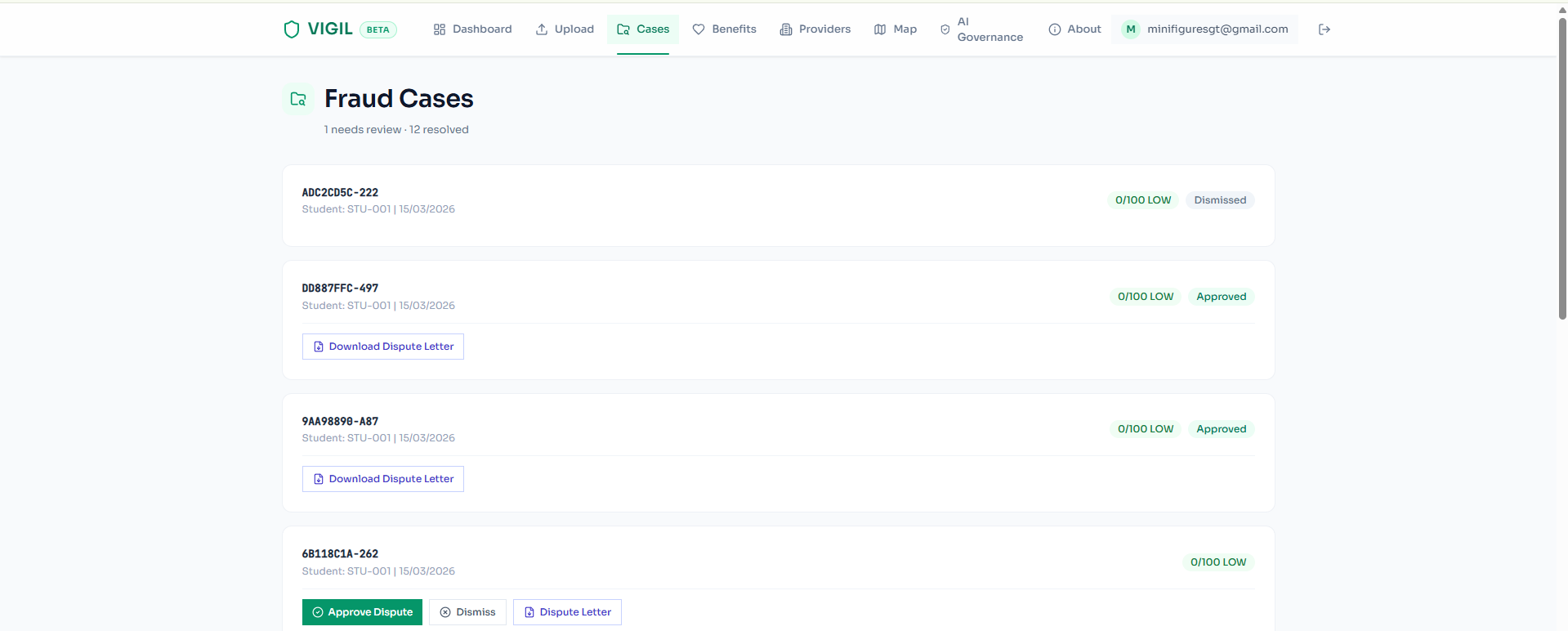
- False positive risk: Fraud detection carries real consequences. We implemented a multi-layer safeguard: confidence scores on every flag, a pure Python scoring engine with transparent breakdowns, optional IBM watsonx.ai compliance validation, and mandatory human approval before any action.
- Database migration mid-hackathon: We migrated from Snowflake to Supabase PostgreSQL halfway through to simplify deployment, requiring a full store abstraction layer rewrite while keeping the pipeline functional.
Accomplishments that we're proud of
- 14 agents across 5 layers with genuine architectural separation, not agent inflation. Each agent has a clear input contract, output contract, and reason for existing.
- Two pieces of non-LLM logic: a pure Python fraud scoring engine and an optimization engine, proving the system is not just "ask the model." The scoring formula is fully documented in YAML with NHCAA-based justifications for every weight.
- Three Moorcheh memory namespaces enabling cross-agent coordination and longitudinal pattern detection across student claims.
- The "every receipt is two things" insight that turns a single upload into fraud detection + benefits discovery + health monitoring simultaneously.
- Student-first UX: benefit alerts for unused coverage, a clinic finder with OHIP/UHIP filters, a fee guide explorer so students can understand their own bills, and a fraud gauge that makes risk scores visceral rather than abstract.
- 26 Playwright E2E tests covering the full application (API health, auth flows, navigation, landing page, upload flow).
- Production-grade engineering: Supabase PostgreSQL with async SQLAlchemy, typed Pydantic APIs, structured logging, metrics endpoint, JWT auth, and graceful degradation.
What we learned
- Multi-agent systems need deterministic checkpoints between LLM-driven agents. Putting a pure Python scoring engine between the Fraud Analyst and the Action layer gives judges (and users) something they can trust and verify.
- Memory architecture matters more than model choice. The difference between VIGIL and a simple fraud detector is that VIGIL remembers: past claims at this provider, the student's coverage utilization, and provider risk patterns that accumulate over time.
- Canadian specificity is a strength. Building around the ODA fee guide, UTSU plans, and OHIP/UHIP made the project feel real and grounded rather than generic. Judges responded to concrete numbers ("$385 for a $120 cleaning") more than abstract capabilities.
- Policy-as-code matters. Centralizing all fraud scoring parameters in a single YAML file (
fraud_policy.yaml) made our scoring defensible, auditable, and configurable without code changes.
What's next for VIGIL
- Integration with Green Shield Canada's claims API for real-time claim verification
- Cross-student provider intelligence: aggregate fraud signals across students (anonymized) to build community-driven provider risk scores
- Mobile receipt capture with on-device preprocessing
- Expansion beyond dental to pharmacy and paramedical billing
- Partnership with student unions to embed VIGIL into student health portals
- Dispute letter PDF generator: auto-generate formal dispute letters with ODA fee guide references
Built With
- Next.js 14, TypeScript, Tailwind CSS, ShadCN UI, Magic UI
- FastAPI, Python 3.11, LangGraph, Pydantic
- Gemini 2.0 Flash (multimodal OCR + reasoning)
- Moorcheh SDK (episodic, semantic, provider memory)
- IBM watsonx.ai (compliance validation)
- Supabase (PostgreSQL + Auth)
- Playwright (E2E testing)
Built With
- ai
- ai-agents
- docker
- fastapi
- gemini
- ibm-watsonx
- langgraph
- machine-learning
- moorcheh
- next.js
- postgresql
- pydantic
- python
- react
- recharts
- supabase
- tailwind-css
- typescript
- websocket


Log in or sign up for Devpost to join the conversation.