-
-

Object Replacement inVideo Painting
-

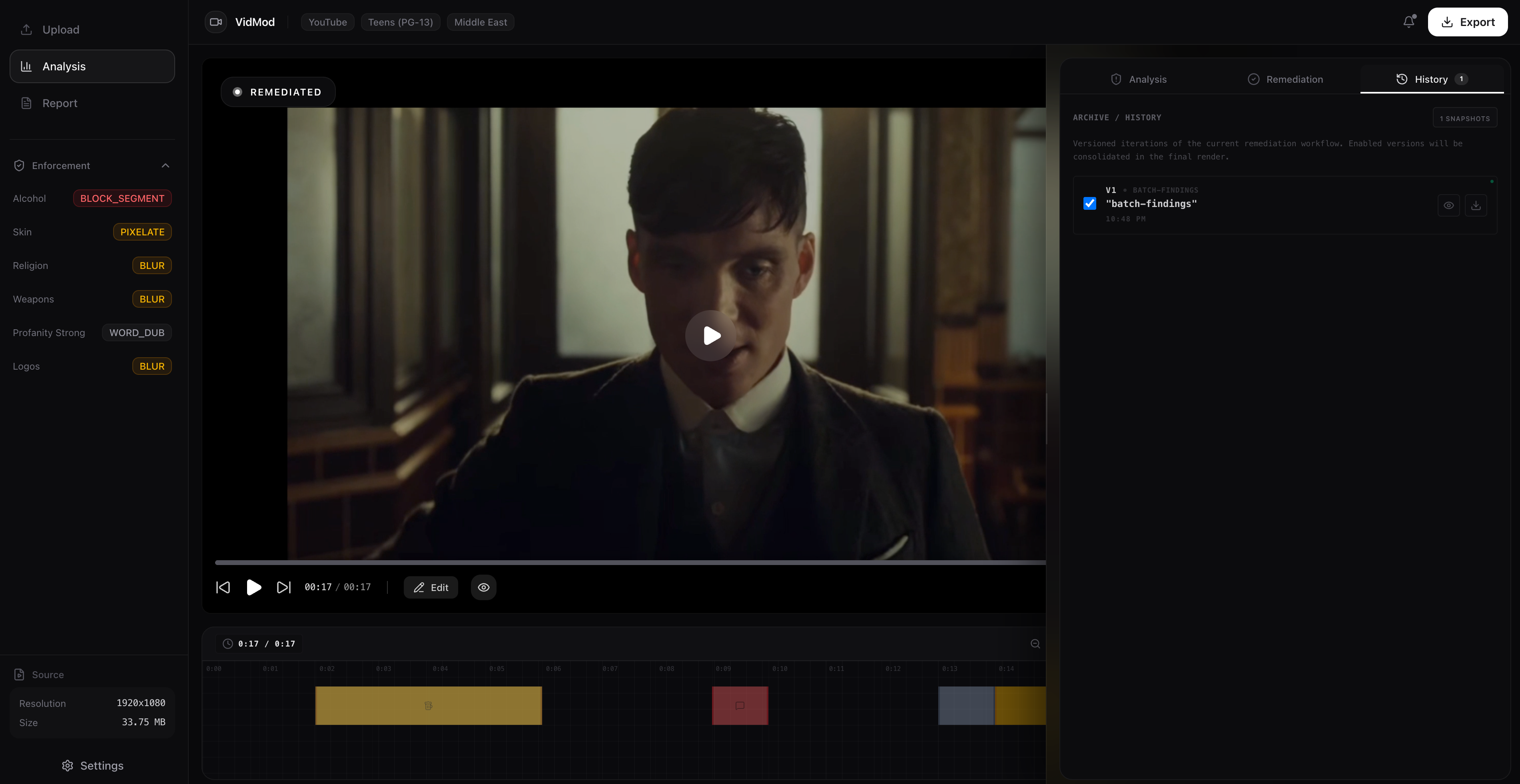
Objects Blurring (Glassware and Alcohol Bottle on table)
-
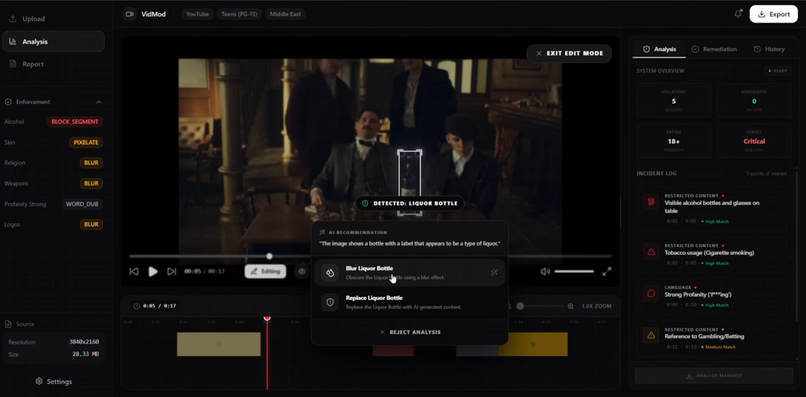
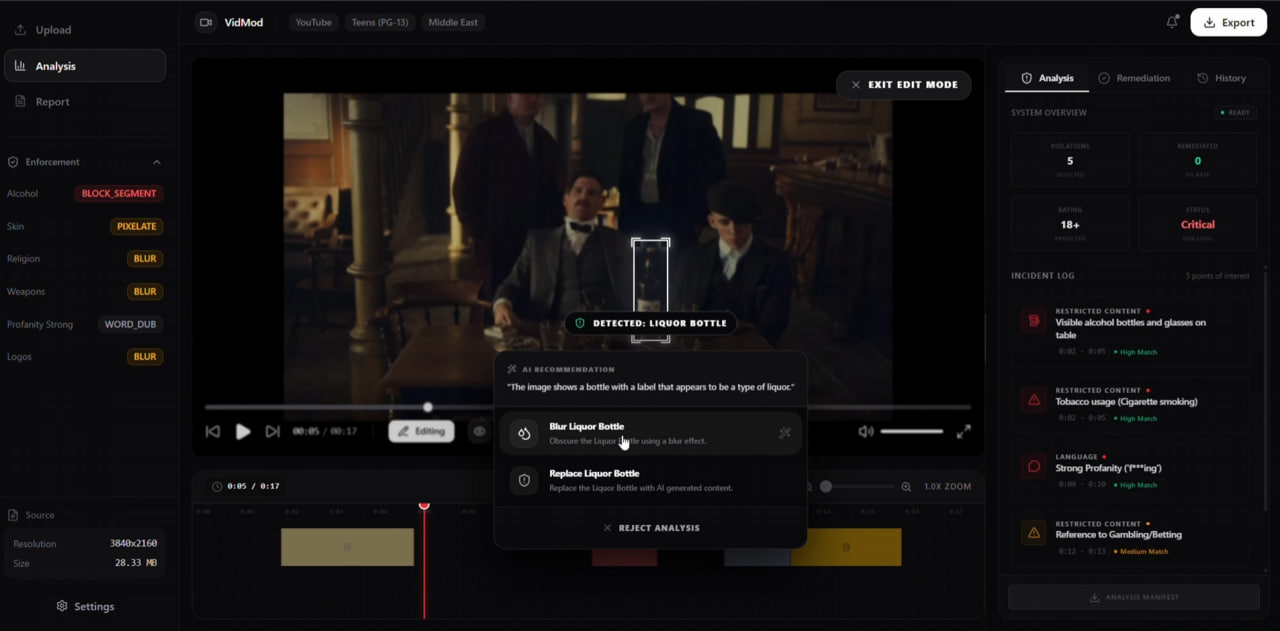
Human-in-the-Loop Editing: Manual bounding box used to guide Gemini 3.0’s object recognition and remediation logic.
-
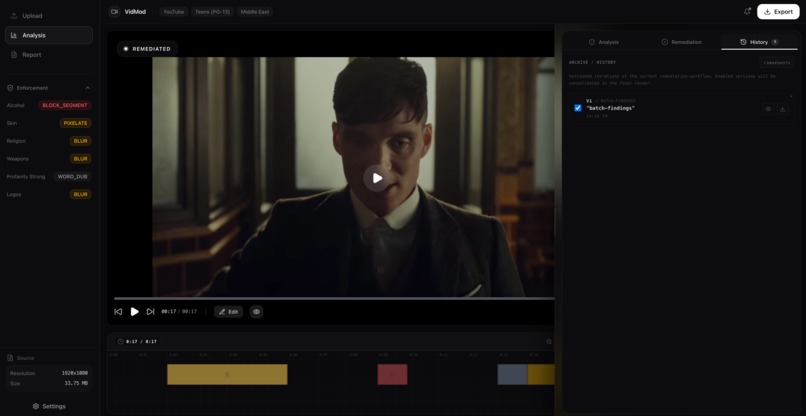
Edits History
-
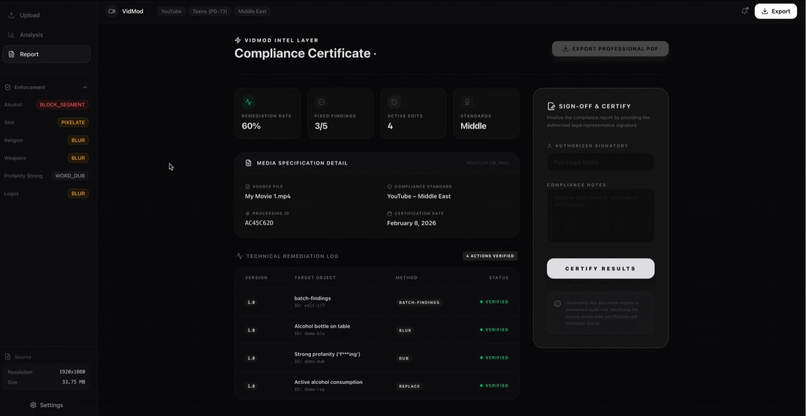
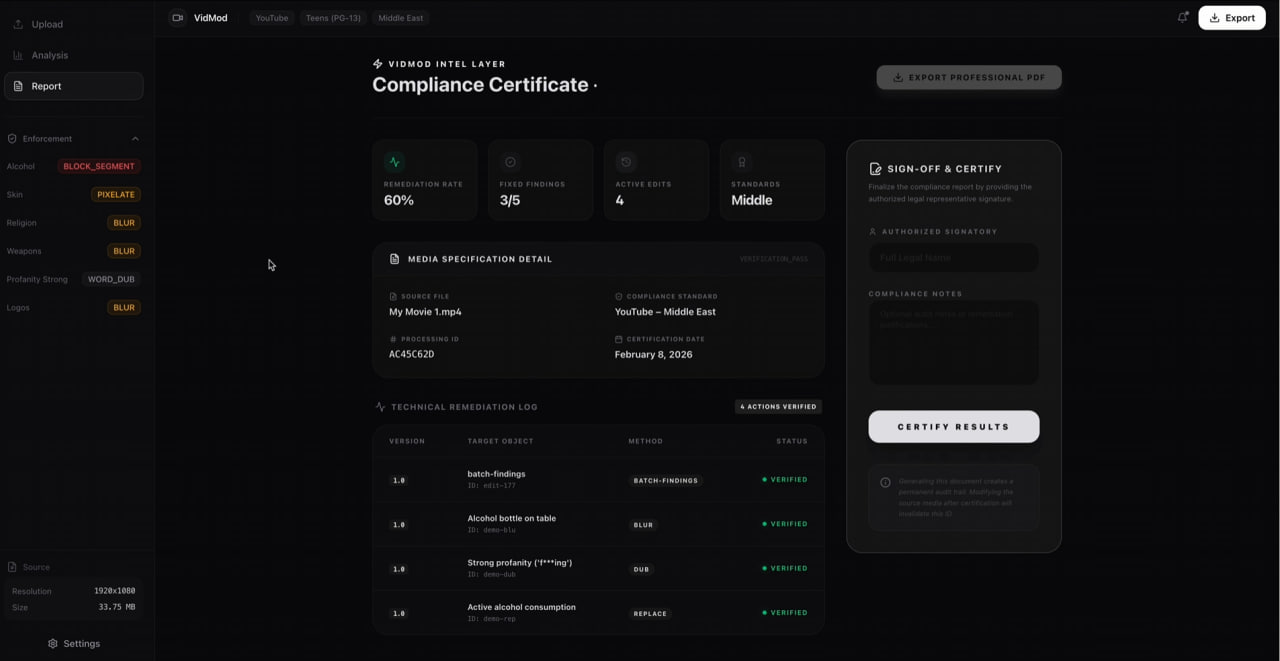
Policy Compliance Results
-

Policy Compliance Certification



VidMod: The Autonomous Video Compliance and Editing Agent Powered by Gemini 3.0
The Vision: Entering the Action Era
We built VidMod to answer a single question: What happens when you give an AI model the ability to not just watch a video, but to edit it?
In the world of media, compliance is a bottleneck. Every minute of content uploaded to platforms like YouTube, TikTok, or Netflix requires rigorous checking for brand safety, profanity, and regulatory compliance. Today, this is done by armies of human moderators or fragile, single-purpose computer vision models.
VidMod is different. It is an autonomous agent built on the Gemini 3.0 family. It doesn't just flag violations; it orchestrates a complex, multi-step remediation process to fix them. It acts as a Director, Editor, and Compliance Officer all in one, powered by the reasoning capabilities of Gemini 3 Pro and the speed of Gemini 3 Flash.
Why Gemini 3? The Brain Behind the Operation
VidMod is not a wrapper. It is a system architected around Gemini 3's unique capabilities. This project would have been impossible with previous generation models.
Gemini in Every Feature
Unlike traditional tools where AI is a post-processing step, Gemini is the active director of every single feature in VidMod.
- Blur & Pixelate: Gemini identifies the exact object to obfuscate in space and time, determining whether a face needs privacy protection or a brand logo needs masking, before handing off coordinates to our vision pipeline.
- Replace: Gemini analyzes the scene's lighting, physics, and context to hallucinate a perfect replacement object—swapping a beer bottle for a soda can—and guides the generation model to blend it seamlessly.
- Dubbing: Gemini listens to the audio, detects the profanity, understands the sentiment, and selects a contextually appropriate replacement word (e.g., changing "shit" to "shot") that matches the speaker's tone, ensuring the edit is invisible to the audience.
1. Native Video Understanding (Gemini 3 Pro)
Traditional video AI relies on "sampling"—extracting 1 frame every second and sending it to an image model. This loses time, context, and cause-and-effect.
VidMod leverages Gemini 3 Pro's native video understanding. We upload the entire video file to the model's 1M+ token context window. This allows Gemini to:
- Understand Action: Distinguish between "holding a bottle" vs. "drinking from a bottle."
- Track Context: Know that a scene is a "historical reenactment" (allowed) vs. "glamorization of violence" (violation).
- Temporal Consistency: Recognize that an object appearing at 0:05 is the same one at 0:15, even if the angle changes.
2. Audio-Visual Reasoning
Gemini 3 doesn't just see; it hears. By processing video and audio together, Gemini 3 Flash can detect profanity with millisecond precision and, crucially, understand the intent behind the words. A friendly "shut up" is ignored; an aggressive slur is flagged for replacement.
3. Policy Injection & Reasoning
We don't hard-code rules. We inject complex, real-world policy documents (e.g., "broadcast standards for daytime TV" or "platform usage guidelines") directly into Gemini's context. The model acts as a reasoning engine, citing specific policy clauses for every decision it makes.
4. Function Calling as the Bridge to Reality
The true power of VidMod lies in how Gemini interacts with the world. We utilize Gemini's advanced Function Calling capabilities to turn reasoning into action.
- When Gemini decides a scene violates a policy, it doesn't just output text; it executes a structured function call (e.g.,
blur_object(timestamp_start, timestamp_end, object_name)). - This structured output is deterministic and machine-readable, allowing our backend to instantly trigger the precise engineering pipeline needed for the fix.
- Gemini effectively "programs" the editing software in real-time, deciding which tool to use and how to use it based on the visual and audio context it perceives.
Extensive Engineering: The "Gemini Loop"
We built a robust, event-driven architecture to turn Gemini's reasoning into reality. The system supports five distinct remediation actions, each powered by a specialized engineering pipeline.
Feature 1: Blur
For privacy protection (faces, license plates), precision is paramount. A bounding box is not enough for moving video.
- Implementation: When Gemini flags an object, we trigger SAM3 (Segment Anything Model 3).
- Mechanism: We feed the frame and the object prompt to SAM3, which generates a high-fidelity segmentation mask. This mask is tracked across frames to ensure the blur stays locked to the subject, even as they move or turn.
Feature 2: Pixelate
Similar to blur, but used for explicit content or stylistic censorship.
- Implementation: We utilize the same SAM3-driven masking pipeline but apply a mosaic filter filter via FFmpeg.
- Mechanism: The block size of the pixelation is dynamically calculated based on the resolution of the video to ensure illegibility without destroying the surrounding visual context.
Feature 3: Replace (Generative Inpainting)
This is where VidMod acts as a Creative Autopilot. Instead of masking an object, we replace it entirely.
- Implementation: We use Generative Video-to-Video technology. Unlike blur, we do not strictly enforce a mask here.
- Mechanism:
- Prompt Engineering: Gemini 3 Pro analyzes the scene's lighting, depth, and style, then writes a detailed prompt.
- Reference Generation: To ensure the replacement object (e.g., a specific brand-safe soda can) looks perfect, we use Gemini 3 Pro's native image generation to create a photorealistic reference image. This image is passed to the video model to guide the generation, ensuring consistent branding and style.
- Synthesis: We dispatch the prompt, the generated reference image, and the video segment to the generation engine, which synthesizes a replacement that respects the original object's motion and physics.
Feature 4: Dubbing (Audio Replacement)
Replacing a spoken word without re-recording the actor is one of the hardest problems in AV engineering.
- Implementation: We built a custom Audio Separator pipeline using Demucs.
- Mechanism:
- Separation: We split the audio into four stems: Vocals, Drums, Bass, and Other.
- Voice Cloning: We clone the speaker's voice using a clean sample found elsewhere in the video.
- Synthesis: We generate the "safe" word (chosen by Gemini) in the actor's voice.
- Muting: We mute only the specific timestamp in the Vocal stem.
- Recombination: We mix the new word with the persistent background stems. This ensures that background music or ambient noise doesn't "dip" or disappear when the word is changed.
Feature 5: Beep
The classic censor.
- Implementation: Precision FFmpeg audio filtering.
- Mechanism: We generate a 1000Hz sine wave matching the exact duration of the profanity. We then apply a volume filter to zero out the original audio exactly for that duration and overlay the beep, ensuring zero leakage of the original word.
Intelligent Orchestration (The Marathon Agent)
VidMod is designed for long-running, complex tasks. A single video compliance job involves uploading gigabytes of data, processing millions of tokens, and coordinating multiple asynchronous APIs.
Autonomous Editing & Version History
VidMod is not a "black box" that overwrites your files. It functions as a transparent, autonomous editor that respects your workflow.
- Autonomous Editing: Once policies are set, VidMod autonomously scans the timeline, identifies violations, selects the best remediation tool (blur, replace, dub), and applies the fix—all without human intervention. It serves as an tireless junior editor that pre-clears content before a human ever sees it.
Granular Version Control: Every single action taken by Gemini is versioned. The system maintains a complete history of the video state. If a user disagrees with Gemini's decision to "blur the background," they can simply revert that specific action in the UI. We built a non-destructive editing pipeline where the original media is never lost, and every AI decision is a layer that can be toggled on or off.
State Persistence: The VideoPipeline maintains a job state machine that survives server restarts.
Self-Healing: If an external generation API times out, the agent waits and retries with exponential backoff.
Result Verification: Gemini maintains "Thought Signatures"—structured logs explaining why it chose a specific action (e.g., "Replacing 'beer' with 'soda' because policy 4.2 prohibits alcohol in kid-rated content").
The Future: Autonomous Media with Gemini Veo
VidMod proves that Gemini 3 is more than a chatbot—it's an infrastructure layer for the next generation of media tools. We are moving from a world where humans edit content to a world where humans direct agents to edit content for them.
Looking Ahead: Gemini Veo While we currently orchestrate external video models, the future of VidMod lies with Gemini Veo. As Veo's native vide-o-to-video inpainting capabilities mature, we will replace our entire external generation stack with native Gemini video generation. This will unify the entire pipeline—Analysis (Pro), Audio (Flash), and Generation (Veo)—under a single, multimodal model family, drastically reducing latency and improving semantic consistency.
With VidMod, a single creator can now do the work of an entire compliance department. That is the promise of the Action Era.
Built With
- demucs
- fastapi
- ffmpeg
- firebase
- gcp
- gcs
- gemini
- gemini3
- gen-ai
- google-antigravity
- google-cloud
- python
- restapi
- sam3
- typescript



Log in or sign up for Devpost to join the conversation.