
Inspiration
During a recent Morgan Stanley event, Homer gained insight into the tendency of average investors to often overlook risks. This discovery inspired him to delve into the realm of Language Learning Models (LLMs) for risk assessment. Despite acknowledging certain limitations, he was intrigued by the capabilities of AutoGPT. Homer's goal is to harness these technologies to empower investors in making informed, risk-aware decisions.
What it does
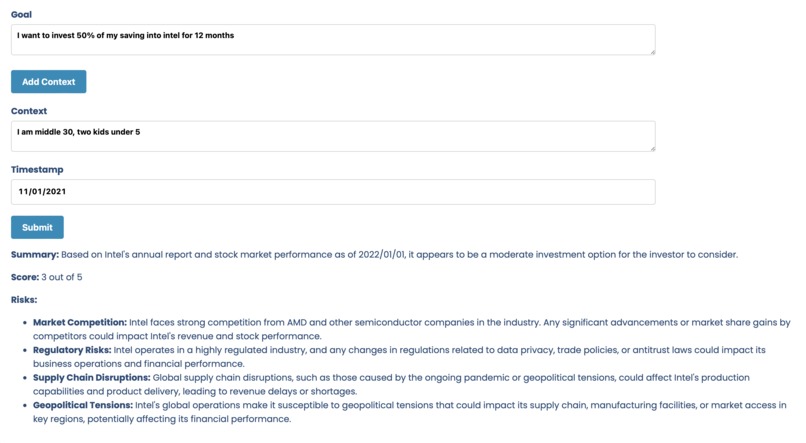
This innovative platform performs crucial tasks, including analyzing annual reports and stock prices, and utilizes the gathered data to offer insightful risk assessments.
How we built it
Our platform utilizes OpenAI's LLM technology, similar to the RAG framework, to conduct risk analysis. It dynamically generates tasks tailored to each investment decision type. In our demonstration, we utilize public financial APIs to access stock price history and annual financial reports, ensuring a thorough and data-driven analysis process.
Challenges we ran into
During our endeavors, a notable obstacle we faced was OpenAI's inclination towards "hallucination," generating coherent yet inaccurate risk analyses. Recognizing the impracticality of fully resolving this well-known issue within the timeframe of the hackathon, our approach emphasizes showcasing the model's capability to learn and progress gradually. Through the analysis of both successful and unsuccessful runs, we iteratively refine the prompts utilized to guide the model's thought process. This iterative learning strategy holds potential for augmenting the accuracy and dependability of the analyses.
Accomplishments that we're proud of
Our team's collaborative efforts culminated in the creation of functional code, representing a noteworthy milestone. This achievement was showcased in a demonstration (Demo: https://youtu.be/90Qnw0MnvX0). To establish a dependable foundation, we conducted evaluations utilizing both simulated data and human moderation. In addition to highlighting our current progress, we are proud to have developed a forward-thinking plan and strategy aimed at ongoing enhancement.
What we learned
GPT-4 Limitations in Financial Comprehension:
- GPT-4's limitations in comprehending financial facts became apparent.
- Particularly with terminology not fully supported.
- Incorporating a dedicated financial knowledge base or employing a fine-tuned approach may be necessary.
Benefits of Evaluating Investment Products:
- We discovered that evaluating a combination of investment products, rather than focusing on a single stock as demonstrated, could offer more utility.
Significance of Knowledge Graph for Financial Analysis:
- The significance of employing a knowledge graph (or Neuro-symbolic AI) for financial analysis was underscored.
- While GPT-4 showcased its capabilities, it highlighted the need for further advancements in this area.
Priority on Training Process for AI Improvement:
- The process of training—acquiring new knowledge and improving AI—emerged as a critical, long-term priority over the current system's capacity at its inception.
What's next for Second Insight
Broaden Data Sources for Analysis:
- Expand the range of data sources to encompass a wider array of information, such as competitors' performance, profiles of the management team, and analyses of industry sectors. This expansion aims to enhance the depth of our analysis.
Develop Internal Knowledge Base with Vector Database:
- Create an internal knowledge base utilizing a vector database, with the goal of deepening our comprehension and refining the accuracy of the model.
Improve Explainability of Risk Analysis:
- Enhance the clarity and comprehensibility of our risk analysis feature, with a focus on providing users with transparent insights into the rationale behind risk assessments.
Implement Training Procedure Inspired by Robotic Task Planning:
- Introduce a training procedure inspired by robotic task planning, which combines the fine-tuning of LLM (Language Learning Model) with Reinforcement Learning (RL) techniques. This approach aims to continuously enhance the model's performance and decision-making capabilities.

Log in or sign up for Devpost to join the conversation.