-
-
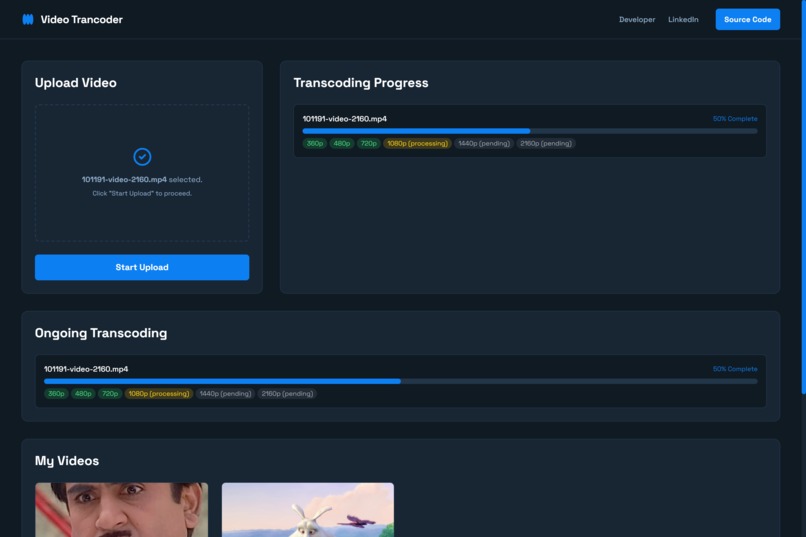
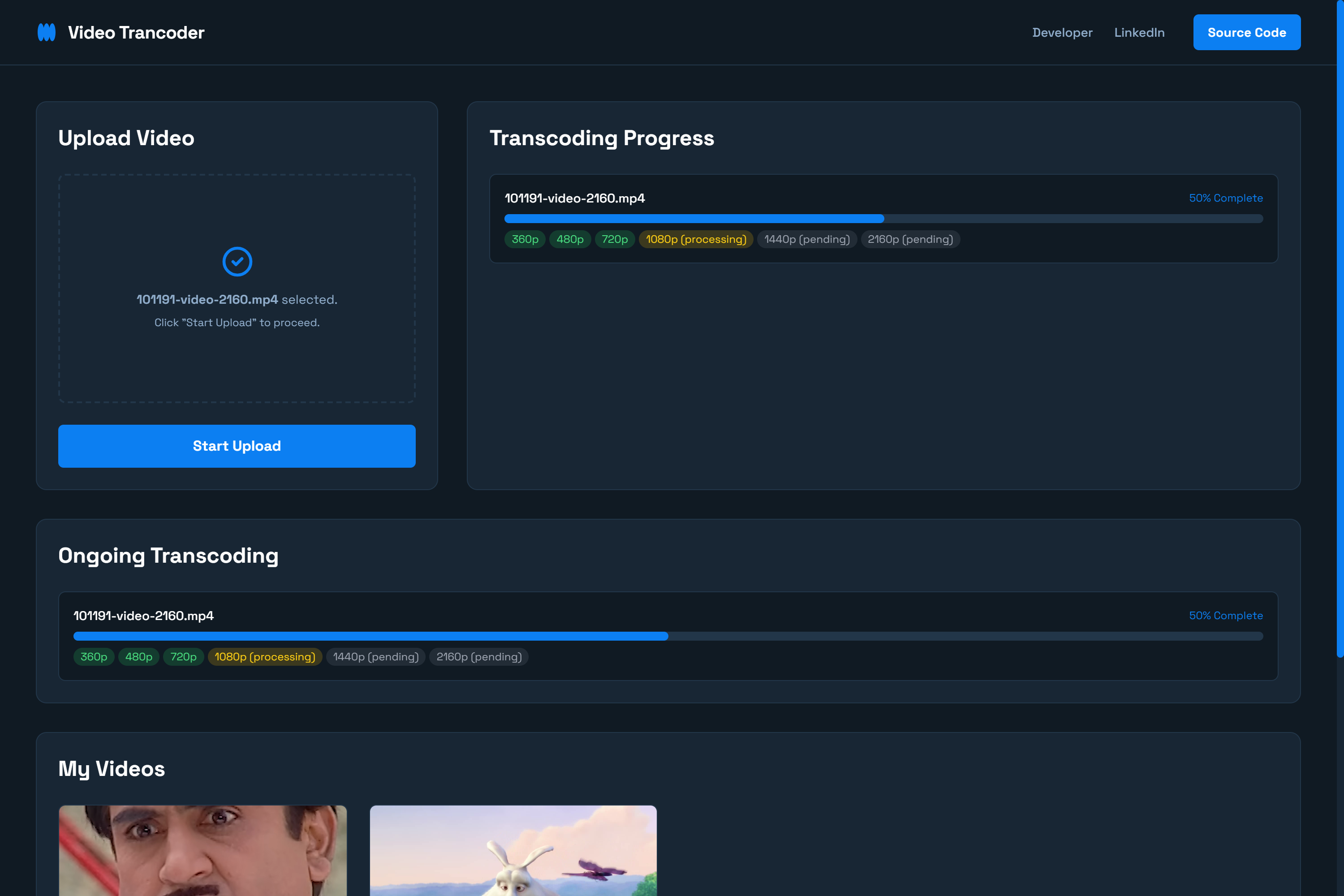
Web UI
Inspiration
Our inspiration came from the need for a simple, scalable, and cost-effective solution for video processing. We were fascinated by the power of serverless computing and wanted to explore how AWS Lambda could be used to handle complex workflows like video transcoding and transcription. We also wanted to build a practical tool that could be used for real-world applications, such as online learning platforms, media archives, or personal video blogs.
What it does
This project is a serverless AWS Lambda solution for on-the-fly video transcoding, transcription, and adaptive streaming (HLS & DASH). It features a simple Flask-based frontend for uploads, status tracking, and video management. When a video is uploaded to an S3 bucket, a Lambda function is triggered to:
- Transcode the video into multiple resolutions (e.g., 1080p, 720p, 480p) for adaptive bitrate streaming.
- Generate HLS and DASH playlists for compatibility with a wide range of devices.
- Create a dynamic sprite sheet of thumbnails for video scrubbing previews.
- Transcribe the audio to generate subtitles using Amazon Transcribe.
How we built it
We built this project using a serverless, event-driven architecture on AWS. The core of the project is a Python-based Lambda function that is triggered by S3 object creation events. We used the following technologies:
- AWS Lambda for serverless compute.
- Amazon S3 for video storage and as an event source.
- Amazon Transcribe for automated subtitle generation.
- FFmpeg for video transcoding and thumbnail generation.
- Flask to create a simple web frontend and REST API.
- Docker to package the application and its dependencies for deployment to Lambda.
- Lambda Function URL to provide direct HTTP access to the Flask application.
Challenges we ran into
- Packaging FFmpeg for Lambda: One of the biggest challenges was packaging the FFmpeg binary and its dependencies into a Lambda-compatible Docker container.
- Handling Large Files: We had to optimize our code to handle large video files efficiently and to avoid exceeding Lambda's execution time and memory limits. We implemented S3 multipart uploads to handle large file uploads from the frontend.
- Idempotency: To prevent reprocessing the same file multiple times, we used the MD5 hash of the video file as a unique identifier, making the pipeline idempotent.
- Security: We used S3 presigned URLs to provide secure, temporary access to the video content and implemented appropriate IAM roles and permissions to restrict access to AWS resources.
Accomplishments that we're proud of
We are proud to have built a fully serverless video processing pipeline that is scalable, cost-effective, and easy to deploy. We are particularly proud of:
- The successful integration of FFmpeg within the Lambda environment.
- The efficient handling of large video files.
- The implementation of a simple and functional web interface for video management.
- The use of content-addressable storage to ensure idempotency.
What we learned
This project was a great learning experience. We gained a deep understanding of:
- Serverless architecture and best practices.
- The intricacies of video processing, including transcoding, adaptive bitrate streaming, and thumbnail generation.
- How to build, package, and deploy Lambda functions using Docker.
- The importance of security and idempotency in distributed systems.
What's next for Video Transcoder
We have many ideas for the future of this project, including:
- Adding support for more video and audio codecs.
- Implementing a more sophisticated frontend with a modern JavaScript framework like React or Vue.
- Adding user authentication and authorization.
- Integrating with other AWS services, such as Amazon Rekognition for video analysis.
- Improving the performance and cost-effectiveness of the transcoding process.
- Adding a database to store video metadata for more complex querying.
- Compressing Video before processing.
- Separate lambda functions for each task.

Log in or sign up for Devpost to join the conversation.