-
-

Project Poster

Our final report can be found at: Youtube Teller Final Report
--------------------- Check off 1 ---------------------
Youtube Teller - a Video StoryTelling model to extract Youtube Videos
Team Member
Chen Wei (cwei24), Yuan Zang (yzang6), Yunhao Luo (yluo73)
Introduction
Video Description/Storytelling is a complicated task which involves automatically captioning a video by understanding the action and event in the video which can help with the retrieval of the video efficiently through text task. For this final project, we are trying to solve a video-caption problem which specifically focuses on video captioning tasks on Youtube video.
Our original plan was to focus on cooking activity - caption paring dataset and generate a cooking guide from that dataset. But after we realize that that dataset is really hard to be preprocessed along with the information related to it is very little, we switch to this Microsoft Research Video Description Corpus and Youtube Clips dataset.
Related Work
Updated Plan:
Original Plan:
- MMAC captions dataset introduction paper
- VideoBERT: A Joint Model for Video and Language Representation Learning
- UniVL: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Data
Microsoft Research Video Description Corpus and Youtube Clips dataset
The Video is named using its id: For example: -4wsuPCjDBc_5_15 where _5_15 means from the 5th second to the 10th second.
The Description txt is in the following form:
-4wsuPCjDBc_5_15 a squirrel is eating a peanut in it's shell
-4wsuPCjDBc_5_15 a chipmunk is eating
-4wsuPCjDBc_5_15 a chipmunk is eating a peanut
-4wsuPCjDBc_5_15 a chipmunk is eating a nut
-4wsuPCjDBc_5_15 a squirrel is eating a nut
-4wsuPCjDBc_5_15 a squirrel is eating a whole peanut
-4wsuPCjDBc_5_15 a squirrel is eating a peanut
...
With the -4wsuPCjDBc_5_15 being the video id and a squirrel is eating a peanut in its shell being the description. Since the captions all have similar meanings, this task is more like a video caption task instead of a storytelling one.
Methodology
We choose to treat this task as a sequence-to-sequence generation task.
To start, we used the cv2 package to help us turn video into a sequence of image frames. We set the frame rate to be 1s per image frame, as the videos in our dataset are generally 5 or 10 seconds in length. After several tests, the frame rate that 1s per image frame is adequate for this translation task, and also economical since it has the lower number of images generated to be fed into our model. Considering the large size of YoutuberClips dataset, we limited the number of images that can be extracted from each video. In this process, we keep a good balance of the trade off between the number of images we extracted and the quality of the model performance.Feel free to make a larger image frame set corresponding to the video if you have more time.
In the next step, we used 3 different strategies to process our image frames, so that it can be put into the model. Below are the 3 ways of input (and we will justify our choice in our report):
- Turn our video into
random single imageframes. - Turn our video into
mean imageframes. That means the mean of every image frame corresponding to that video. - Turn our video into
sequential imageframes. And we will use positional encoding afterwards in our transformer part to deal with it.
Afterwards, we use the same method described in ClipCap: CLIP Prefix for Image Captioning. Their model structure is like the below. We removed the pretrained COCO dataset’s weight and applied our own creativity (positional encoding) on the model.We make this choice, as we believe using prefix training to capture the video/image feature is a very lighted way of training and can achieve good results without the need of managing to "train too much". And instead of passing the image, we pass the preprocess video (image frames) into the CLIP model.
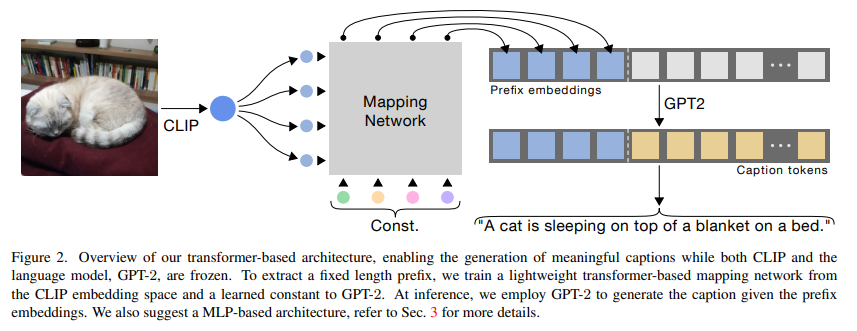
In our model we applied the Transformer-encoder Mapper model structure to encode image information into embedding space, so that the GPT-2 is suitable for this special task without training. The CLIP model is designed to impose a shared representation for both images and texts. After training over a vast number of images and textual descriptions using the cross entropy loss, the visual feature of CLIP and textual representations of GPT-2 are well correlated. Therefore, the fine-tuned Mapper structure allows prefix embeddings to capture the visual information, and effectively generate the suitable input for the GPT-2 model to correctly predict.
Our modified model structure looks like:
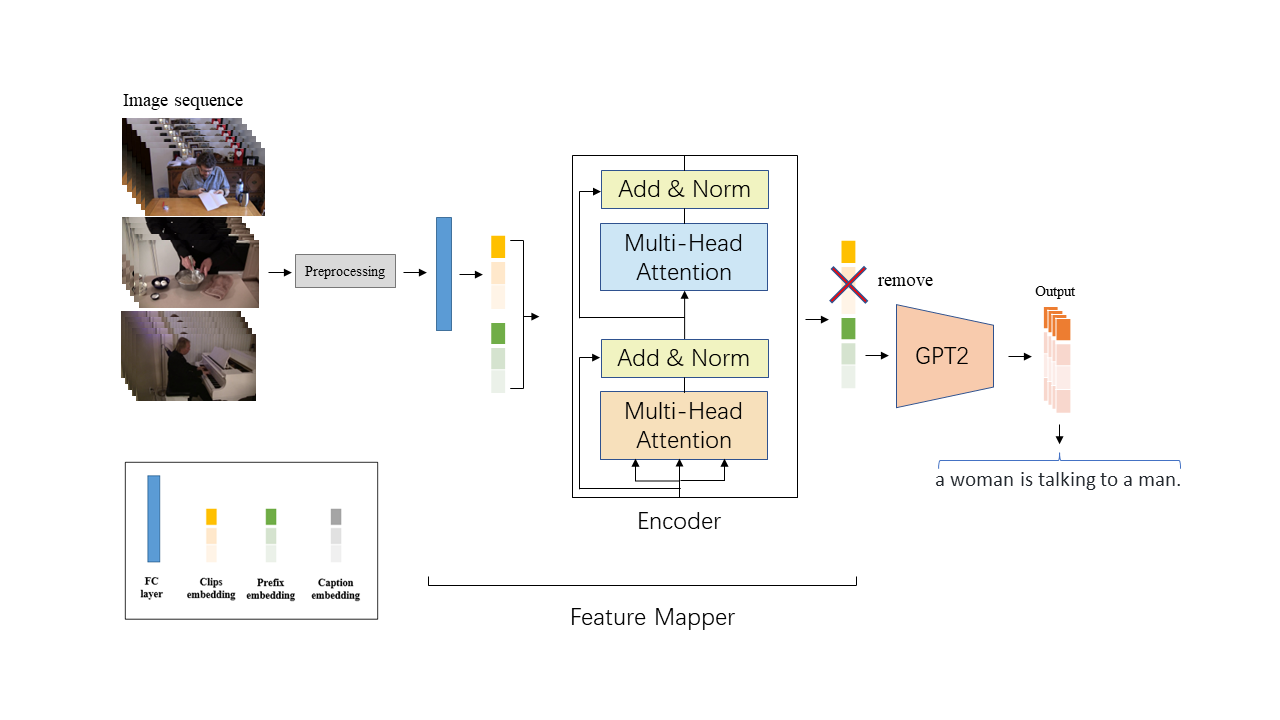
The whole process of this model is shown above. We preprocess videos into image embeddings. And then we concatenate image embedding with prefix embeddings. Then we feed such combinations into the Feature Mapper model to allow prefix embeddings gaining enough visual information. Then, we only maintain the prefix embedding parts and feed them into the GTP-2 model to generate the final predictions.
Metrics
We plan to test our video caption model on the test dataset of uncaptioned videos to generate their captions. We evaluate the performance of our model on the similarity of the generated sentences and standard answers. Specifically, we adopt 4 metrics to evaluate the accuracy of our captions, namely, BLEU, CIDEr, METEOR, and Rouge.
The baseline model (Vision Transformer) can achieve 68.4 1-gram BLEU score and 50.7 5-gram BLEU score. We hope to improve the performance in some specific subjects, to achieve higher BLEU scores than the baseline model.
Ethics
What broader societal issues are relevant to your chosen problem space?
In this project, we aim at generating high-quality, articulated text descriptions given videos as input. To this end, we can improve the accessibility of various videos in the wild, which hopefully can benefit users. By the generated descriptions/tags, we can also sort and categorize massive video sets.
Why is Deep Learning a good approach to this problem?
Deep learning is currently the most popular and accurate method for computer vision/natural language processing. As for video understanding, by using neural networks with convolutional/attention, the model can learn effective representation. In addition, deep learning methods can achieve end-to-end modeling and are more flexible than traditional methods that usually use handcrafted features (lacking generalizability to other datasets).
Division of labor
We plan on working equally across X aspects of the project:
- Preprocess the data: Chen Wei, Yuan Zang
- Model Architecture
- Caption Generater (Use GPT2 pretrained model): Chen Wei, Yuan Zang
- Video/image CLIP encoder: Yuan Zang
- Multi-head attention Transformer: Yuan Zang, Chen Wei
- Transformer with Positional Encoding to encode position information: Yuan Zang
- Evaluation (BLEU, METEOR, CIDEr, ROUGE) and and Visualization: Yunhao Luo
- Model Training: Yuan Zang
- Ablation study: Chen Wei
- Write the report and make the poster: Chen Wei
--------------------- Check off 2 ---------------------
Introduction
Our plan has changed and the later session would illustrate that.
We are trying to solve a video-caption problem which specifically focuses on a youtube activity description paring dataset.
Challenges
1. Preprocess the dataset
Our original plan is to make a cooking guide model - a video storytelling model built on the MMAC dataset. However, it is too hard to preprocess. To be specific, in the doc of MMAC, it says we need to download the CMU-MMAC dataset in advance. And since we choose pizza categories, there are 35*3 pizza files to be downloaded, which make it hard to download without scripts and is too big to process. And the vid attribute in caption_train/val/test dataset is hard to find the corresponding elements. So preprocessing this dataset just requires a lot of effort.
So to make our lives easier, we choose to switch our dataset. At first, we wanted to switch our dataset to Visual Storytelling Dataset VIST. But it seems to require access and is very big. And then we find many other dataset which are not accessible.
In the end, we found this dataset which seems ok for us to preprocess. It contains Microsoft Research Video Description Corpus and Youtube Clips.
Original Plan:
MMAC captions dataset
MMAC dataset is a dataset for sensor-augmented egocentric-video captioning. This dataset contains 5,002 activity descriptions.
Samples:
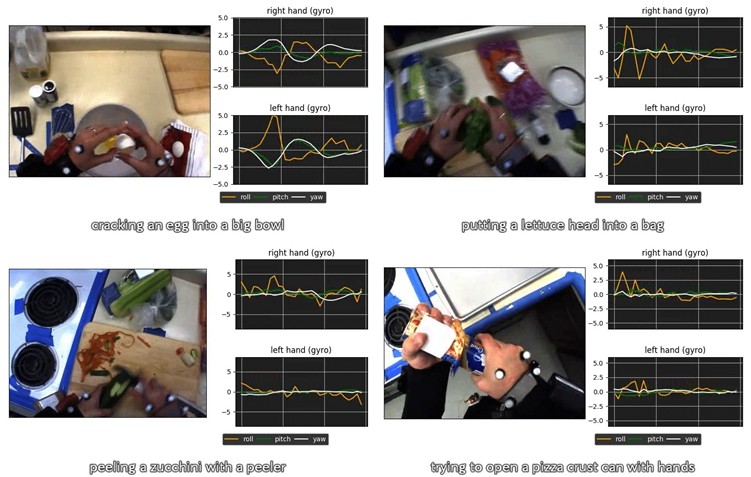
- Spreading tomato sauce on pizza crust with a spoon.
- Taking a fork, knife, and peeler from a drawer.
- Cutting a zucchini in half with a kitchen knife.
- Moving a paper plate slightly to the left.
- Stirring brownie batter with a fork.
The given dataset is in tsv form:
| record_no | video_id | vid | start_time | end_time | start_frame | end_frame | caption |
|---|---|---|---|---|---|---|---|
| 0 | S50_Brownie_7150991-203 | f141_i023_a00 | 151.0 | 152.0 | 4530 | 4590 | taking a kitchen knife from a drawer . |
| 1 | S47_Salad_7150991-196 | f130_i028_a00 | 214.0 | 246.0 | 6420 | 7410 | peeling a zucchini with a peeler . |
| 2 | S22_Salad_7150991-952 | f60_i000_a00 | 6.0 | 9.0 | 180 | 300 | taking a bowl from a cabinet . |
We will only train on one category for simplicity and time concern. We chose subcategory Pizza.
2. Model structure
There are so many choices for our model structure (although none of them is easy). It is really hard to make decisions and implement them all from scratch in such a short time. So we choose to modify existing model structure and try to twist it if we have time.
Some of the choices are:
- Like GLACNet
Preprocessing Video to image sequence and use ResNet 152 image feature extractor, then then pass it to Bi-LSTM Encoder, and finally use LSTM decoder to generate sentences
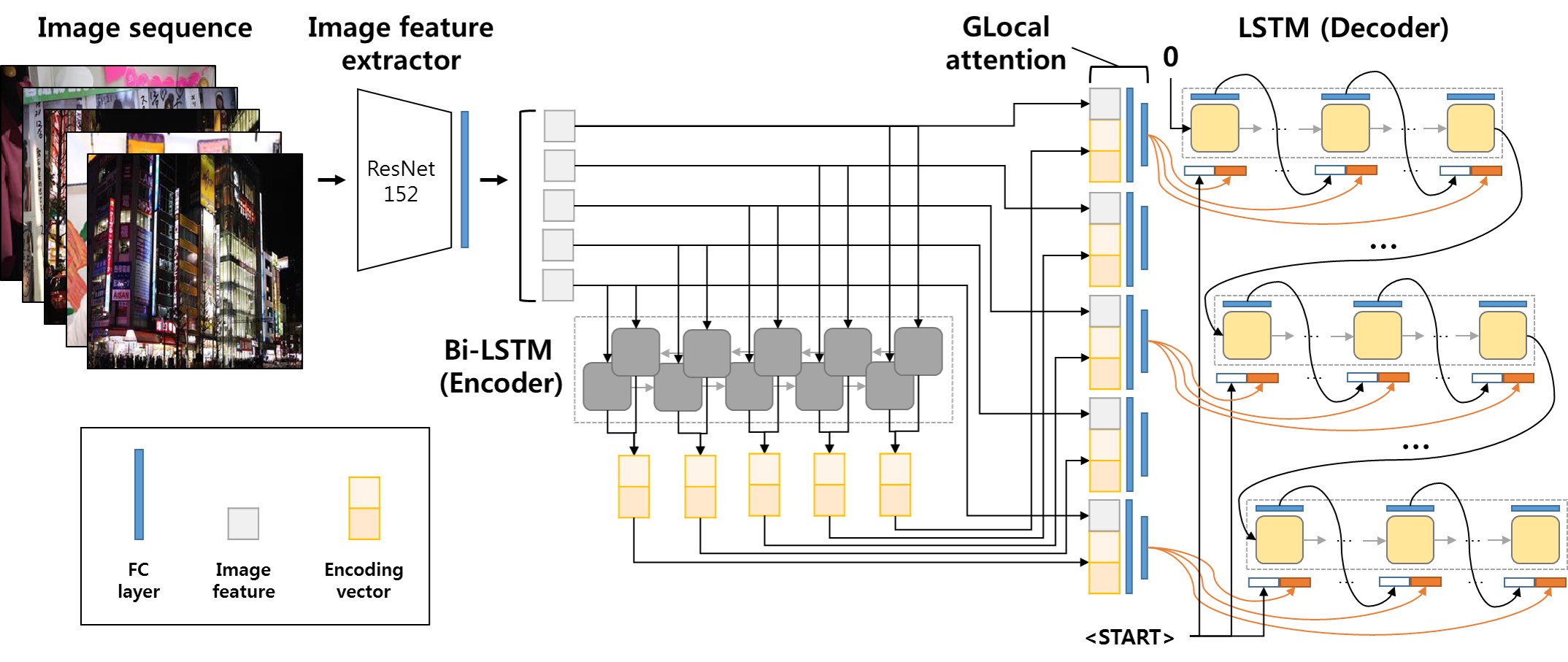
Or maybe we could change Bi-LSTM to transformer or Bi-Transformer.
Like our original plan
Pass the video directly to a 3d-CNN based video encoder to get C3D features and implement a Transformer-based encoder as well. We combine the information from 2 encoders and pass it to LSTM or Transformer-decoder.A new one
Turn the video into image frames, and then use a visual feature extractor to encode images. Then we use a Transformer Encoder to encode the sequential information of images and map the image embedding into the text representation space. In the end, we use a language model to decode the encoding into captions.
Insights
- Our preprocess results:



Caption: “a woman is carrying a huge plastic bag of cans over her back“, “a young woman is carrying a huge bag full of empty cans”
Currently we are choosing way 1 and we are preprocessing video to sequential image frames. We choose the frame rate to be 1 (that means 1 second = 1 frame) to keep our training data size controllable.
- We haven’t run through our models yet. But we have found the backbone and hopefully we can run through it very soon.
Plan
We need to dedicate more time to get our model working.
We are thinking about twisting the model structure and generating some results based on that.
--------------------- Checkoff 3 ---------------------
It contains everything that you need to know about our project! Check it out!


Log in or sign up for Devpost to join the conversation.