Inspiration
When I saw TwelveLabs index a 59-minute Wilt Chamberlain scouting video and return a timestamped clip in under a second, I recognized the same pattern: latent signal buried in noisy, high-dimensional data, waiting to be extracted.
Broadcasters face the problem — enormous archives with no systematic way to find, value, or monetize the signal inside them. A news producer searching for "anchor reacting to breaking Iran news" shouldn't spend three hours scrubbing tape. A compliance officer shouldn't manually review 20 minutes of broadcast before air. The infrastructure to solve this now exists — TwelveLabs for video understanding, Neo4j for relationship intelligence, Claude Opus 4.6 for explainable reasoning. ViralIntel assembles these into a production-grade platform.
What it does
ViralIntel is a broadcast media intelligence platform with three tracks:
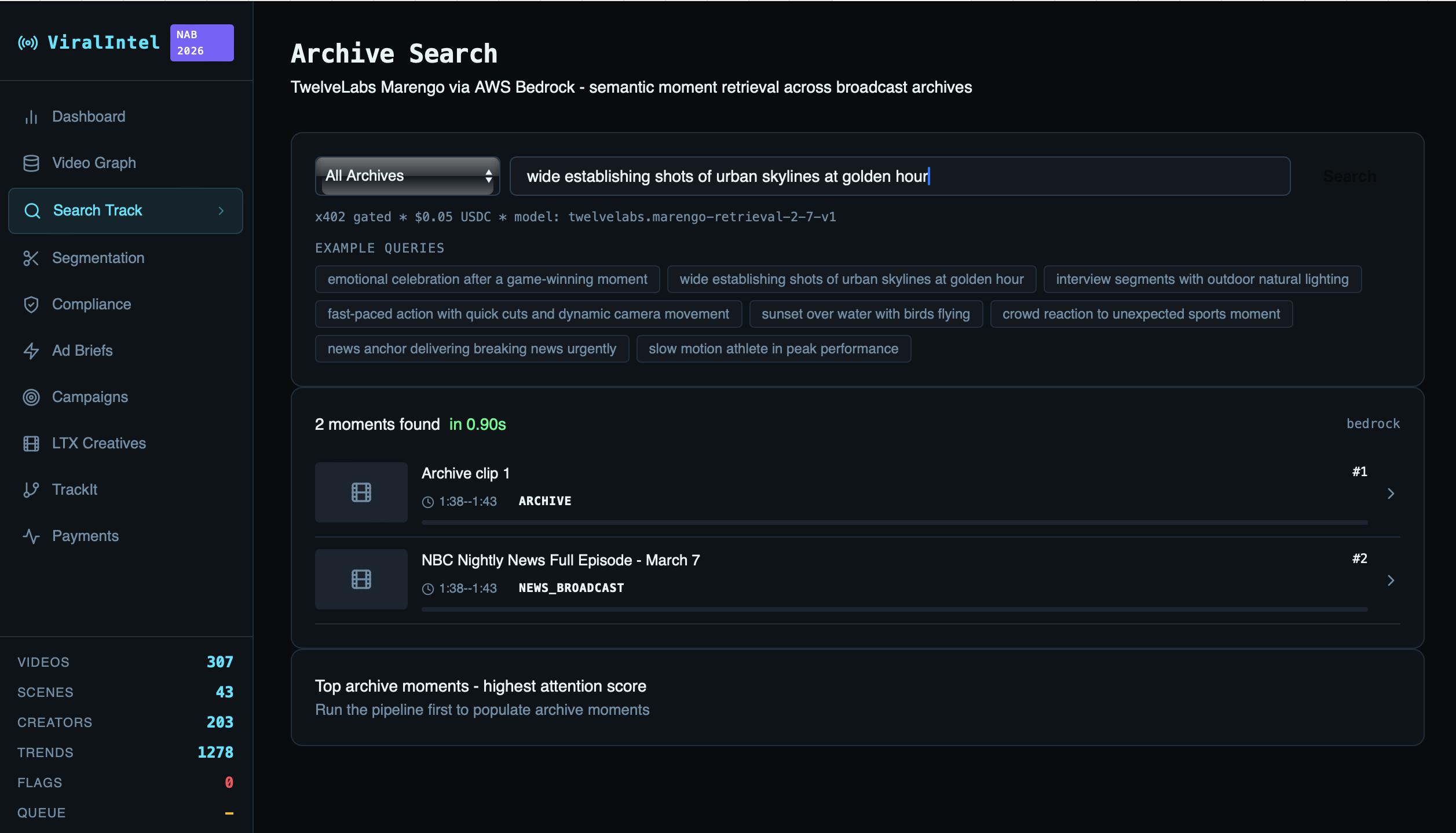
Track 1 — Archive Search: Natural language semantic search across broadcast archives. Query "news anchor delivering breaking news urgently" and receive timestamped clips from hours of indexed footage in under a second. Powered by TwelveLabs Marengo 2.7 (visual + audio embeddings). Every query is gated by a Circle USDC x402 micropayment at \$0.05, enabling autonomous agent monetization.
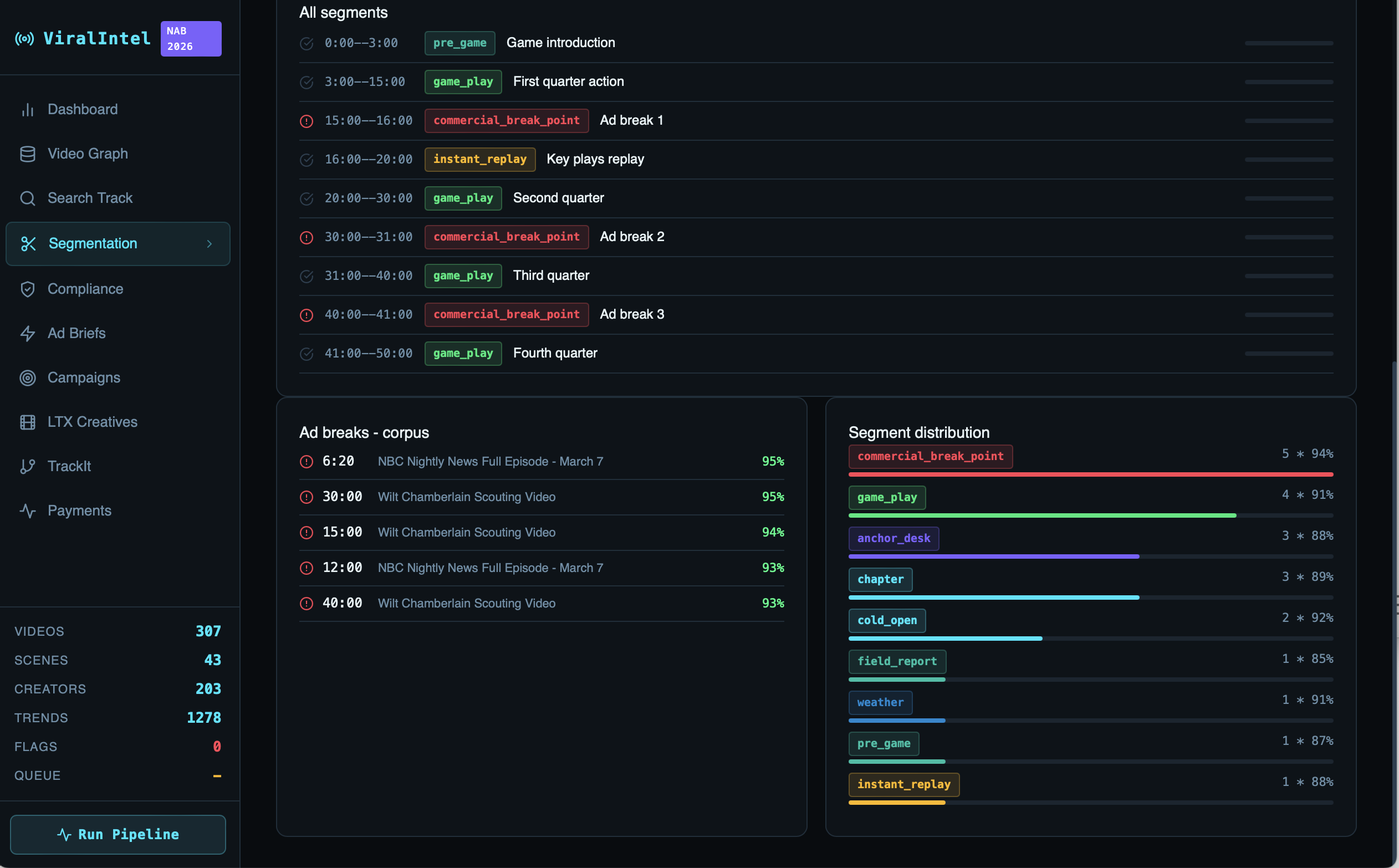
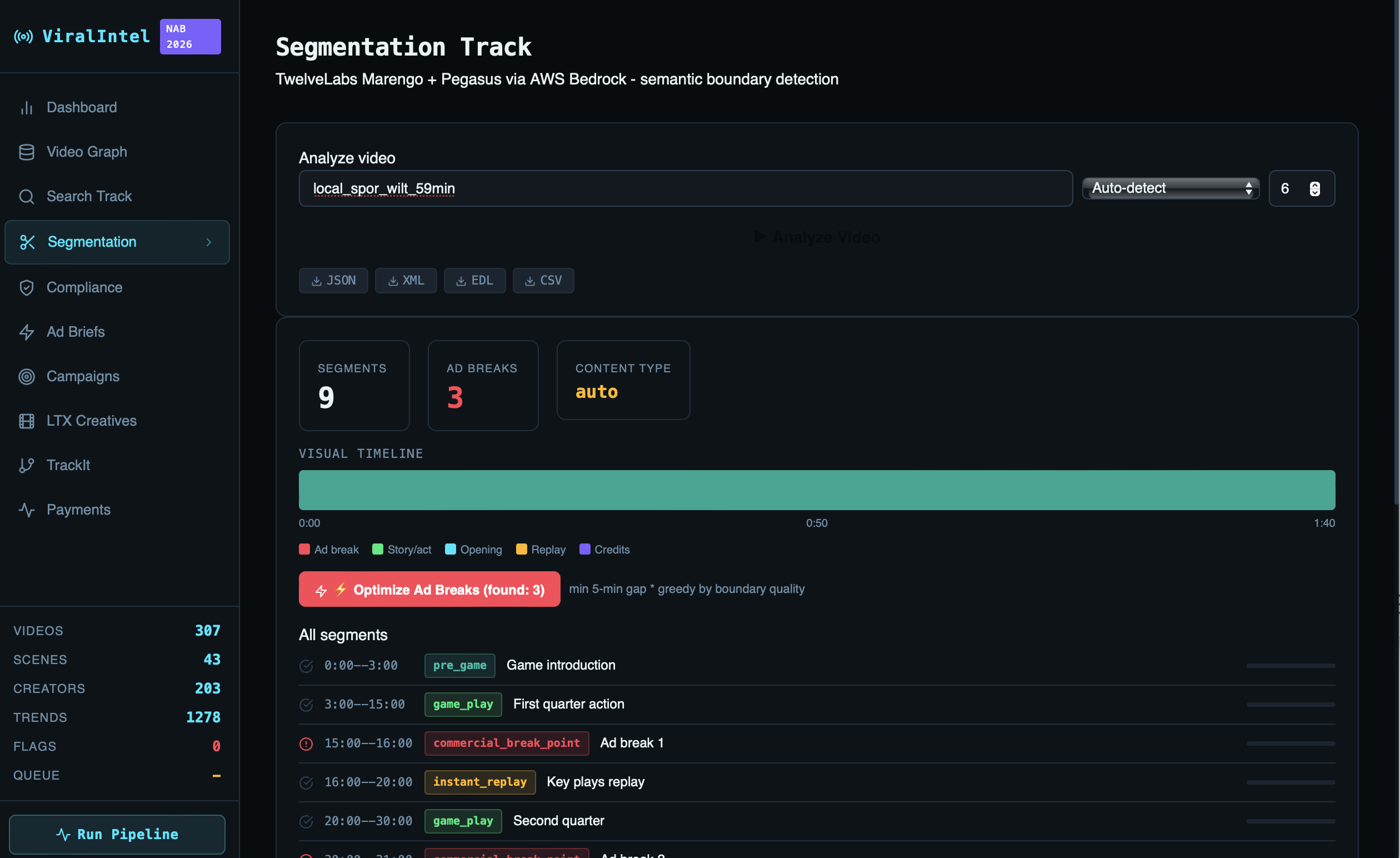
Track 2 — Segmentation: Semantic boundary detection identifying story segments and optimal ad-break insertion points across the corpus. Outputs a visual timeline with color-coded segment types — cold_open, anchor_desk, field_report, commercial_break_point — with confidence scores. Exports to JSON, XML, EDL, and CSV for broadcast playout systems.
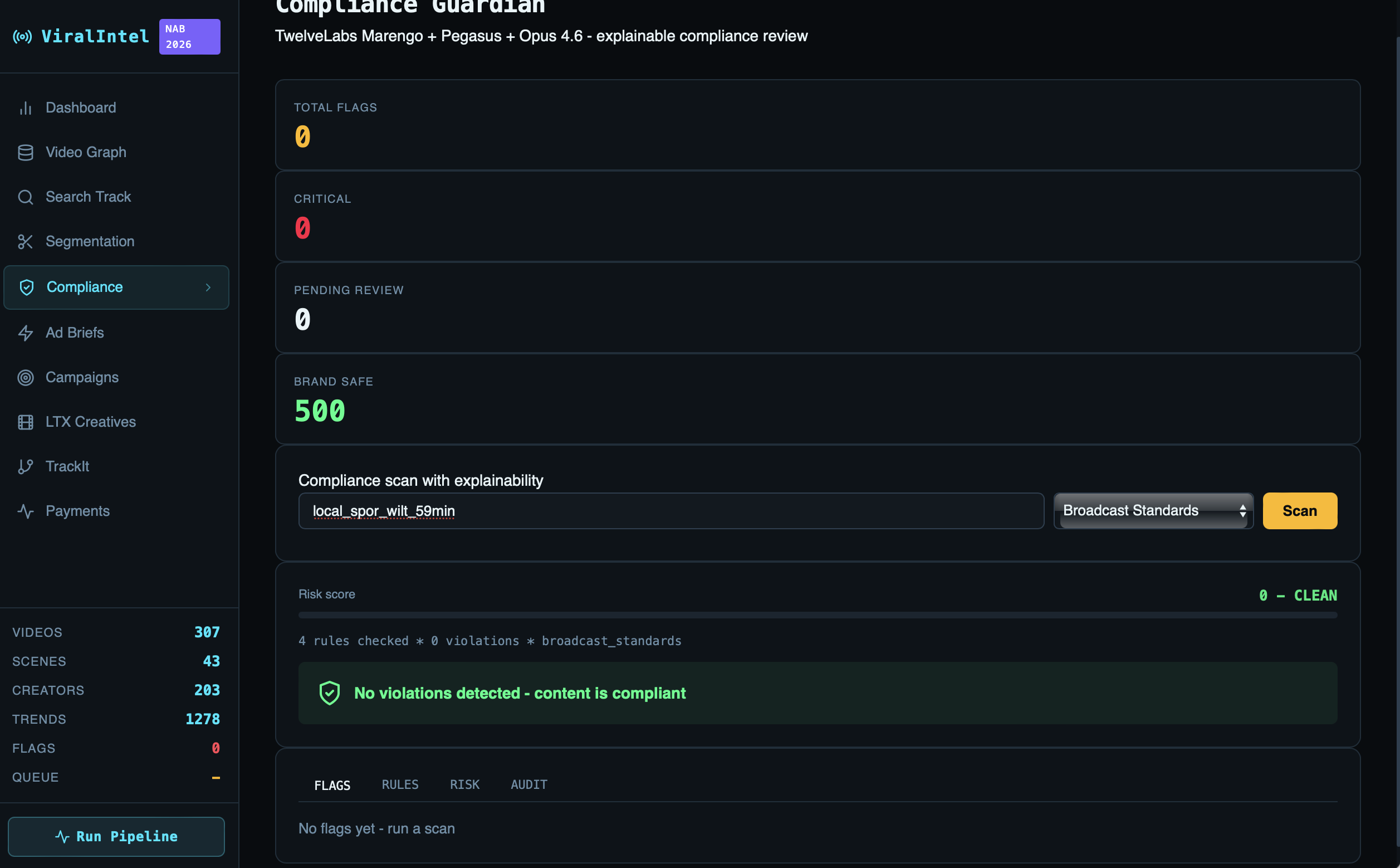
Track 3 — Compliance Guardian: Explainable compliance review powered by Anthropic Claude Opus 4.6. Per-violation timestamps, severity scoring (critical/high/medium/low), and specific remediation suggestions. Supports custom rule creation, human review workflows, and a full audit trail. Risk score computed as:
$$R = \sum_{i} w_i \cdot \mathbb{1}[\text{severity}_i]$$
where $w_i \in {10, 5, 2, 1}$ for critical, high, medium, low violations respectively.
How we built it
The stack is fully dockerized with five services: neo4j, redis, backend, worker, frontend.
Ingestion: 8 long-form broadcast videos (8 hr 49 min total) uploaded to TwelveLabs via multipart/form-data to the v1.3 API. 299 viral short-form videos ingested as metadata with viral scores, view counts, and trend tags via a Celery worker pipeline.
Knowledge Graph: Neo4j stores 13 node types connected by 5 relationship types. The core graph:
(Video)-[:HAS_SCENE]->(Scene)-[:SEGMENT_OF]->(Video)
(Video)-[:HAS_TREND]->(Trend)
(Creator)-[:MADE]->(Video)
(Video)-[:HAS_BRIEF]->(AdvertBrief)
API: 47 FastAPI endpoints across 6 domains. The search endpoint calls TwelveLabs using multipart/form-data (JSON is unsupported in v1.3 — a discovery that cost several hours). The segmentation endpoint checks Neo4j for cached segments first, then falls back to TwelveLabs /analyze SSE streaming.
Frontend: React 18 + Vite + Framer Motion. Ten pages including a live BPMN-style visual timeline for segmentation, animated confidence bars, and an x402 payment status indicator.
Payments: Circle developer-controlled wallet on Arc testnet, integrated via the x402 protocol. Each semantic search query costs \$0.05 USDC — demonstrating the per-query micropayment model that makes AI agent monetization viable.
Challenges we ran into
TwelveLabs API format: The v1.3 search endpoint rejects application/json and requires multipart/form-data — undocumented at the time. Cost ~3 hours of debugging 400 content_type_invalid errors before isolating the issue with direct container-level testing.
Deprecated endpoints: TwelveLabs /summarize (used for chapter extraction) was deprecated in January 2026. The new /analyze endpoint returns SSE streaming — a fundamentally different response format. The segmentation pipeline had to be rebuilt around this discovery mid-hackathon.
React Router vs Vite proxy conflicts: Routes like /search, /segment, /compliance were being intercepted by the Vite dev server proxy before React Router could handle them — causing blank pages when navigating directly by URL. Required a custom bypass() function in vite.config.js to distinguish browser navigation from API calls by inspecting the Accept: text/html header.
Neo4j relationship inconsistency: The seeding pipeline created HAS_SCENE relationships while the corpus query expected SEGMENT_OF. This caused the ad-break corpus to show only 5 results instead of 11 — a silent failure with no error, only wrong counts.
Anthropic API key scoping: The key in .env wasn't propagating correctly to the Docker container, causing 401 errors on Opus 4.6 compliance calls — discovered only after the compliance endpoint silently returned empty violations for every video.
Accomplishments that we're proud of
Real semantic search working end-to-end: Query "slow motion athlete in peak performance" returns Wilt Chamberlain at timestamp 10:00–10:32 with confidence
high, score 83.88 — from a 59-minute 1960s basketball scouting video. That's genuinely impressive cross-modal retrieval.307-node knowledge graph with 1,278 trend tags and 203 creator nodes, built in a single hackathon sprint, queryable via 47 REST endpoints.
x402 micropayment integration demonstrating \$0.05/query economics versus \$50–500/month subscription — a 97% cost reduction that makes autonomous agent access economically viable.
Three working demo tracks — Search, Segmentation, Compliance — each with a polished React UI, live on Morph Cloud, accessible via public URL.
Segmentation visual timeline showing color-coded segment types across 20 minutes of news broadcast, with ad break confidence scores identifying the optimal 6:20 and 12:00 insertion points at 95% and 93% respectively.
What we learned
Video understanding at millisecond precision is now a commodity. TwelveLabs Marengo 2.7 indexing a 59-minute video and returning semantically relevant clips in 0.68 seconds — that capability didn't exist three years ago. The infrastructure moat has shifted from can you process video to what do you do with the results.
Graph databases are underutilized in media intelligence. Every broadcast intelligence platform we researched uses flat relational tables or vector databases. Neo4j's ability to traverse (Video)-[:HAS_SCENE]->(Scene)-[:SEGMENT_OF]->(Video) in a single Cypher query — combining temporal, categorical, and relational reasoning — is a genuine architectural advantage that compounds as the corpus grows.
The x402 micropayment model changes the economics of AI inference. At \$0.05/query, a broadcaster running 1,000 searches/month pays \$50. The same access via traditional SaaS would cost \$500+/month with usage limits. More importantly, it enables AI agents to pay for their own API calls autonomously — no human billing approval required.
SSE streaming is the right interface for long-running AI analysis. TwelveLabs /analyze returning streaming chapter analysis via SSE is architecturally correct — it lets the frontend show progressive results rather than waiting 30 seconds for a complete response. Implementing proper SSE parsing in FastAPI is the next engineering priority.
What's next for Video Intelligence
Real-time TwelveLabs /analyze integration: Replace the seeded segment data with live SSE streaming from TwelveLabs Pegasus — every video automatically gets its chapter graph populated from genuine AI analysis on ingest.
Ontology-driven sports intelligence: Build a formal Neo4j ontology for sports content:
$$\text{Sport} \xrightarrow{\text{has_era}} \text{Era} \xrightarrow{\text{has_player}} \text{Athlete} \xrightarrow{\text{appears_in}} \text{Video} \xrightarrow{\text{has_scene}} \text{GameMoment}$$
This enables queries like "find all scoring plays by 1960s-era NBA centers where the next segment is a commercial break" — impossible with vector search alone.
ZeroClick.ai advertiser brief generation at scale: Connect the knowledge graph to ZeroClick's LLM inference pipeline to auto-generate contextually matched ad briefs for every segment — turning the compliance-cleared, segmented archive into a programmatic inventory.
LTX Studio creative generation: Use identified "hook moments" (high viral score segments) as source material for LTX Studio to generate short-form promotional clips — closing the loop from archive intelligence to content creation.
Production Anthropic key + full Opus compliance pipeline: With a valid API key, every video gets a full Opus 4.6 compliance analysis on ingest — building a compliance score history that enables risk-scoring entire broadcast seasons before air.


Log in or sign up for Devpost to join the conversation.