-
-

our Devtr method vs others when benchmarked on RLVS dataset
-
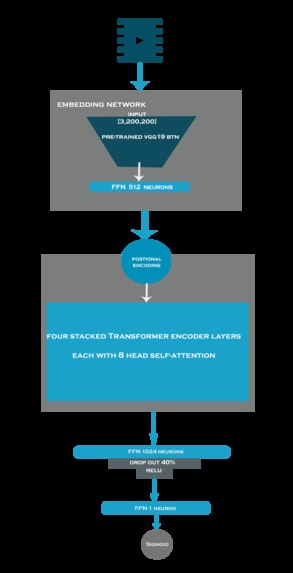
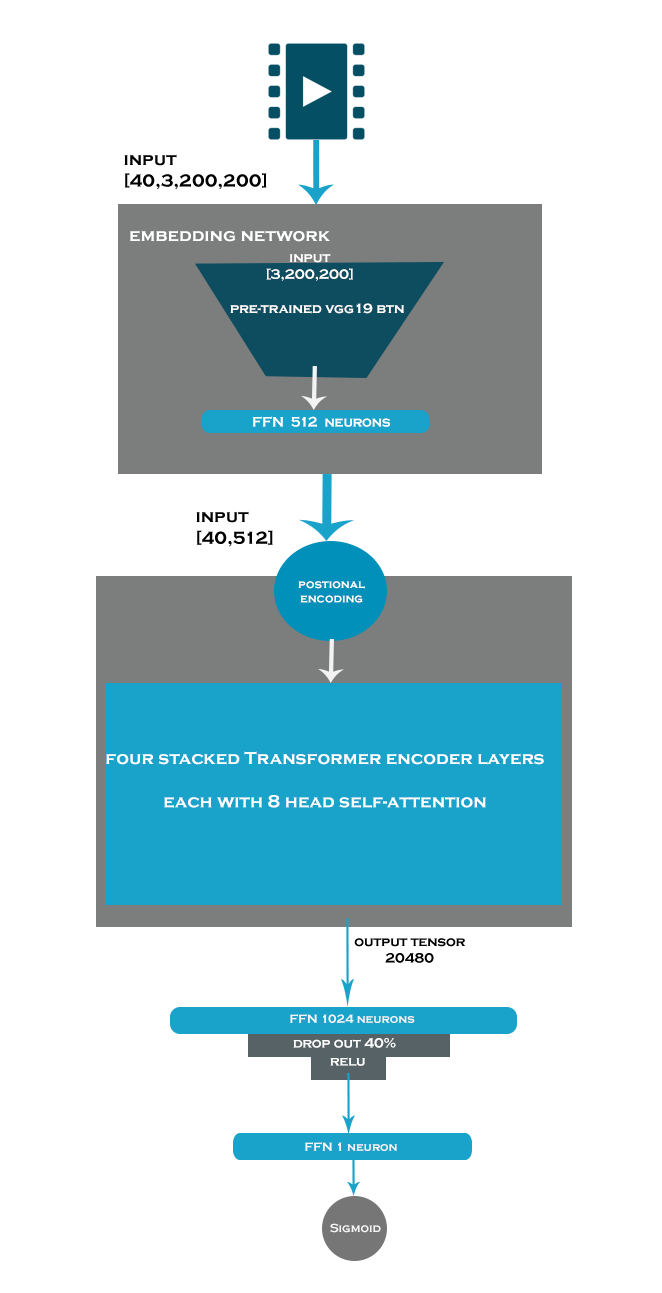
simple diagram for the Devtr model
-

seilancy map


Inspiration
transformer network has achieved very good results in term speed and accuracy one of big challenges facing researchers in computer vision with transformers especially in video tasks is the need for large data and high computational resources example Timesofrmer a video transformer by facebook which need hardware resources and good amount of data to get good results . recently we have proposed a new method called data-efficient video transformer (DeVTr) based on the transformer network as a Spatio-temporal learning method with a pre-trained 2d-Convolutional neural network (2d-CNN) as an embedding layer for the input data. The model has been trained and tested on the Real-life violence dataset (RLVS) and achieved an accuracy of 96.25%. also worth to mention that it was better than TimeSformer in both memory efficiency and convergence speed and accuracy. The (DeVTr) model has been trained for seven epochs and converged to its best results on the first epoch (epoch number zero) while using data of batch size was 16, the size of the video (40 frames, 3 color channels, 200-pixel height, 200-pixel width ).the total amount of GPU Memory for the model during the training was less than 8GB
the TimeSformer is a large model and need a large amount of GPU memory, we choose a video size of (20 frames, 3 color channels, 176-pixel height, 176-pixel width ) with a batch size of 4 the total amount of GPU RAM for TimeSformer was 13.7GB.
for more detail about our DeVTr paper https://ieeexplore.ieee.org/abstract/document/9530829
What it does
the menovideo package help you build video action recognition / video understanding model based on 1- build using our Novel model DeVTR with full customization or use our official implementation of DeVTr , also there is pre-trained weights available for free
2- we provide video dataset reader and preprocessing tolol inside the pacakge for you to easily read videos and make them as pytorch ready dataloaders
3- we also provide you with Timedistributed warper similar to keras Timedistributed warper which can help you easily build (classical CNN+LSTM )
How we built it
data-efficient video transformer (DeVTr) based on the transformer network as a Spatio-temporal learning method with a pre-trained 2d-Convolutional neural network (2d-CNN) as an embedding layer for the input data.
Challenges we ran into
limited time
Accomplishments that we're proud of
a new novel network has been proposed out-preforming network like Timesformer done by facebook research team in scope of limited data and hardware resources solving one of challenges that face researchers who dont have access to to high end hardware and have limited data for the task in hand and want to achieve good results
What we learned
What's next for menovideo: pytorch library for video understanding
more trained models in different tasks more video preprocessing tools


Log in or sign up for Devpost to join the conversation.