-
-
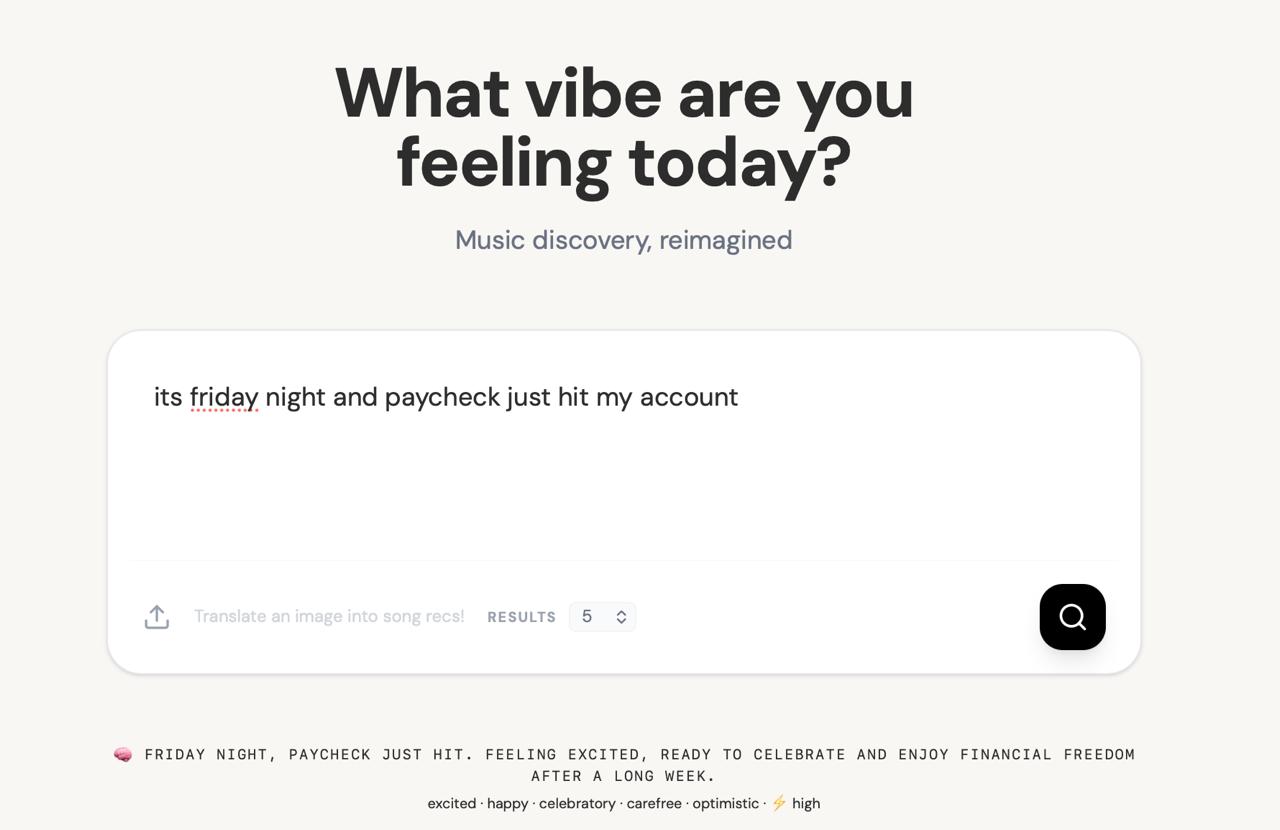
User interface with prompt
-
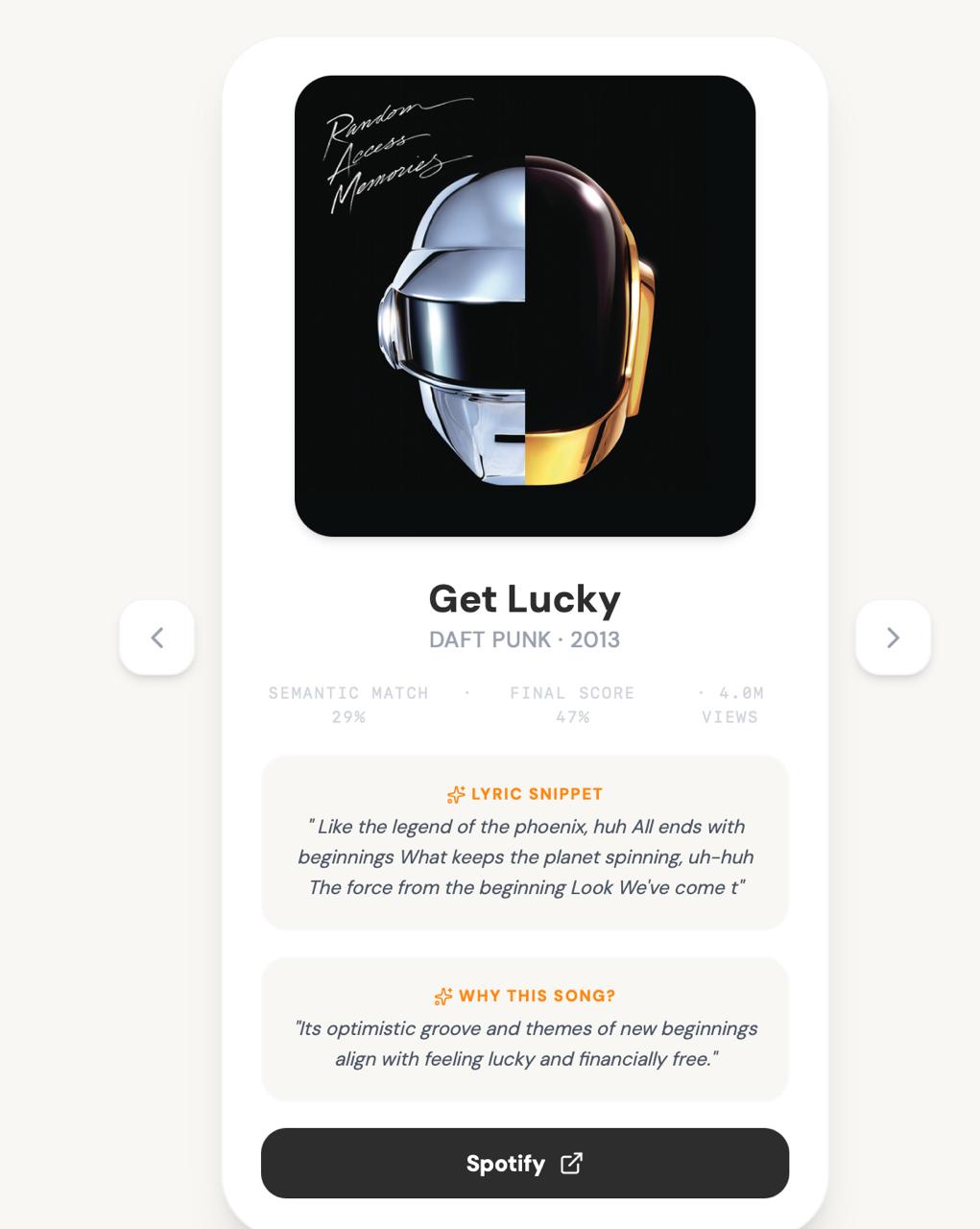
Recommendation 1
-
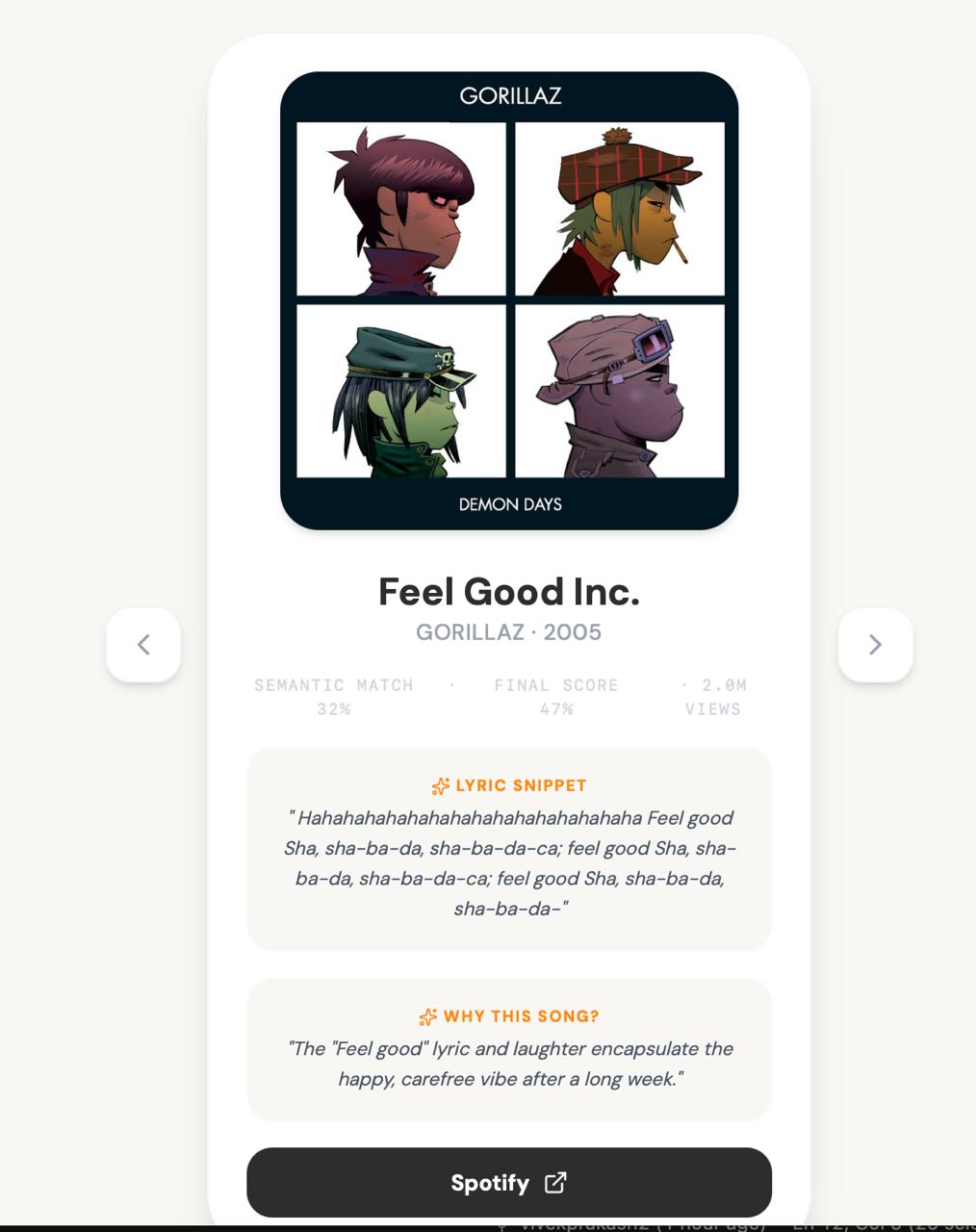
Recommendation 2
-
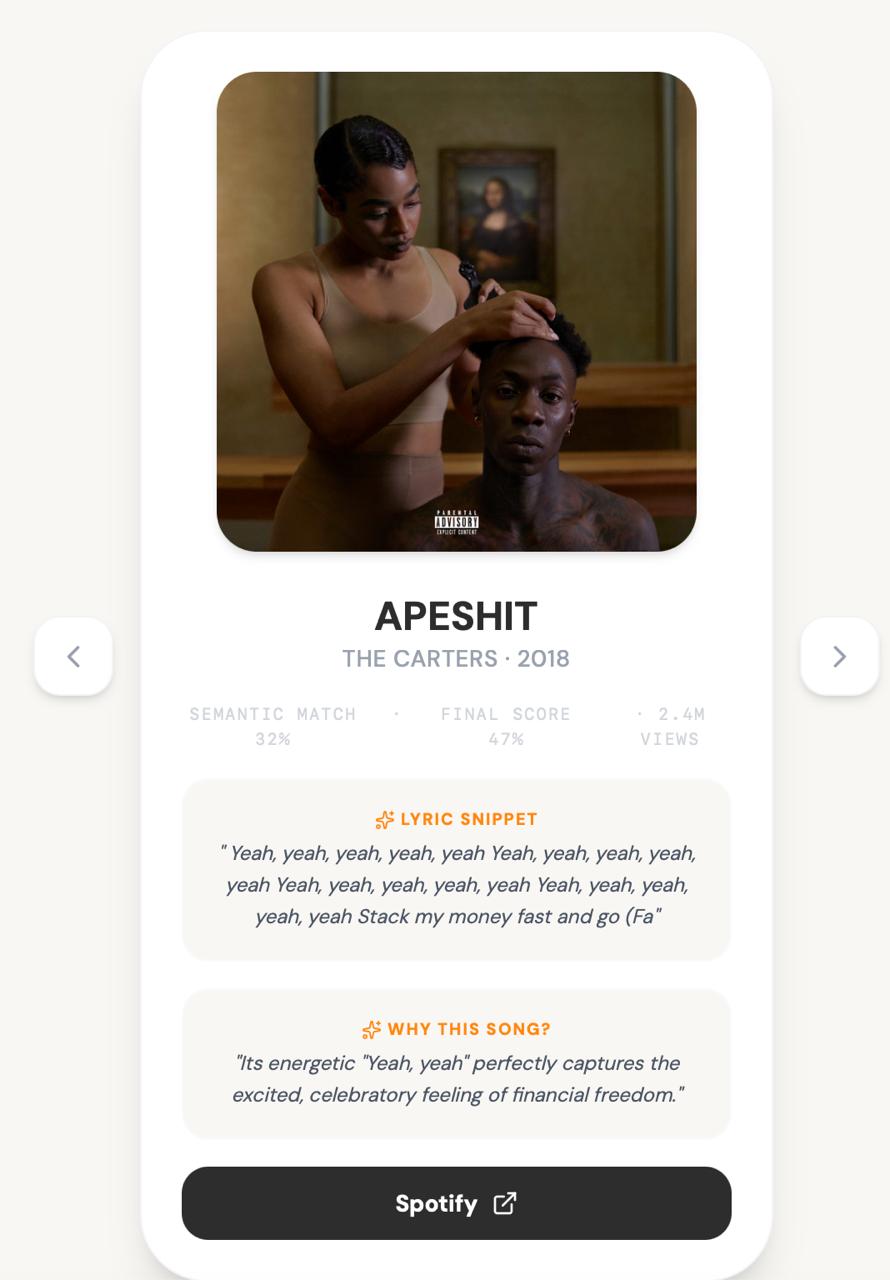
Recommendation 3
Vibe Engine 🎵
Your vibe, your soundtrack.
Inspiration
Music recommendation has always felt impersonal. Spotify knows what you've listened to. It doesn't know how you feel. You can't type "I just closed a massive deal and I want to feel like a god" into a search bar and get something back that actually fits.
We wanted to build something that understands the vibe — not the genre, not the artist, not the playlist tag, but the raw emotional state behind the request. The insight was that lyrics are the most human part of a song, and if you could match the semantic meaning of a mood description to the semantic meaning of lyrics, you'd have a recommendation engine that actually gets it.
What It Does
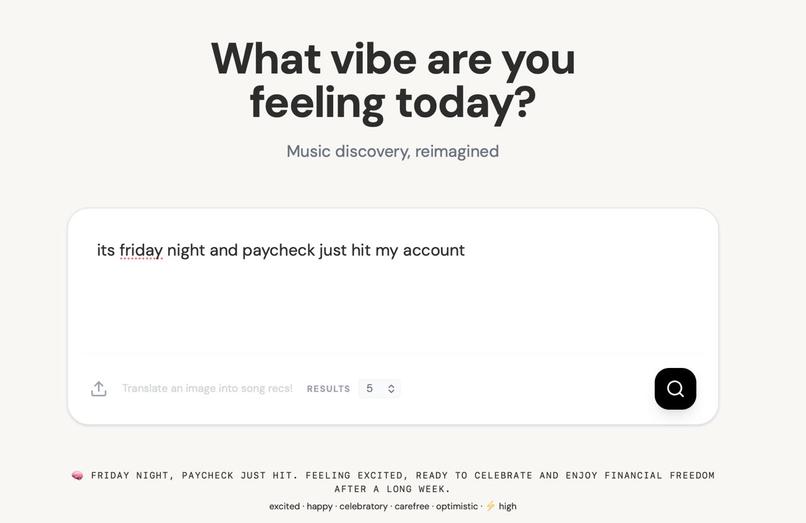
Vibe Engine takes a freeform description of a mood, feeling, or moment — anything from "grindset mindset" to "late night drive, windows down, thinking about everything" — and returns 10 songs whose lyrics semantically match that vibe.
Users can also upload an image — album art, a photo, a mood board — and get recommendations based on the emotion the image conveys. Every result comes with:
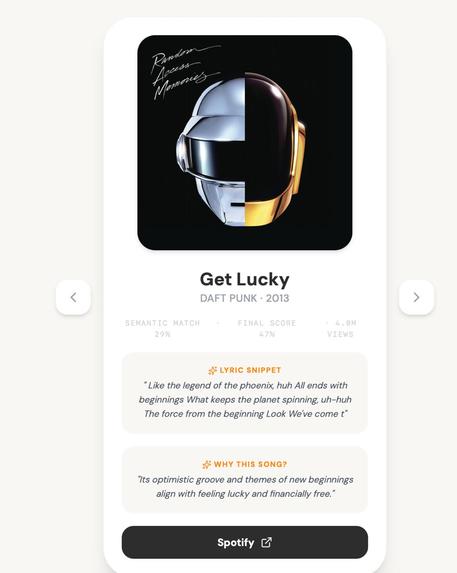
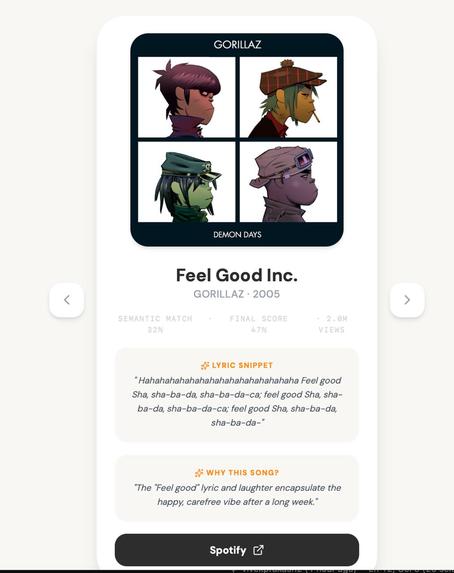
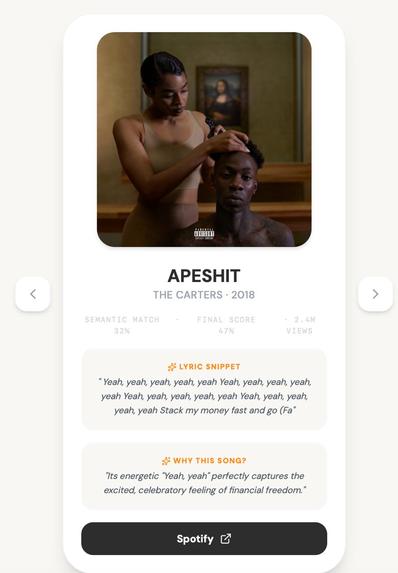
- Album art and a direct Spotify link
- A one-sentence AI-generated explanation of why the song was recommended
- Mood tags, themes, and energy level extracted from the query
How We Built It
The Data
We worked with a dataset of 500,000 songs ranked by view count, each with cleaned lyrics, stored in a single consolidated parquet file. The lyrics were embedded offline using sentence-transformers/all-MiniLM-L6-v2, a BERT-based model that maps text into a 384-dimensional semantic space:
$$\vec{e}_i = \text{Encoder}(\text{lyrics}_i), \quad \vec{e}_i \in \mathbb{R}^{384}$$
The full embedding matrix was precomputed and stored as a NumPy binary file:
$$E \in \mathbb{R}^{500000 \times 384}$$
Query Enrichment
Raw queries like "grindset mindset" are too sparse for reliable embedding. We used Gemini 2.5 Flash to expand them into structured retrieval signals:
{
"rewritten_prompt": "relentless ambition, hustle, self-discipline, winning mindset",
"moods": ["motivated", "focused", "intense"],
"keywords": ["grind", "ambition", "success"],
"energy": "high"
}
Multi-Angle Query Encoding
Rather than encoding just the rewritten prompt, we encode multiple semantic angles — the prompt, keywords, and moods — and average them into a single richer query vector:
$$\vec{q} = \frac{1}{n} \sum_{i=1}^{n} \text{Encoder}(p_i)$$
Blended Ranking
Pure semantic similarity isn't enough — an obscure song with a perfect lyric match isn't useful if nobody knows it. We blend three signals into a final score:
$$\text{score}_i = \alpha \cdot \text{sem}_i + \beta \cdot \text{pop}_i + \gamma \cdot \text{rec}_i$$
where sem is the cosine similarity between the query and lyric embedding, pop is the log-normalised view count, rec is the normalised release year, and weights α = 0.7, β = 0.2, γ = 0.1 by default. Songs below a semantic similarity floor are zeroed out regardless of popularity.
Diversity Filtering
To avoid returning multiple songs from the same artist, we enforce a max per artist cap and deduplicate titles across results. Candidates are drawn from a larger pool before filtering, ensuring we always return diverse results.
Image-Based Recommendations
Rather than re-embedding the full corpus with a multimodal model like CLIP — which would have required days of compute — we used an LLM-as-bridge approach: image → Gemini Vision → text description → existing text embedding pipeline. A pragmatic tradeoff that gave us multimodal recommendations without touching the precomputed index.
Explainability
All explanations are generated in a single Gemini API call, returning a structured JSON array of one-sentence explanations for all 10 results simultaneously. This keeps latency low while making every recommendation interpretable.
The Stack
| Layer | Technology |
|---|---|
| Embeddings | sentence-transformers/all-MiniLM-L6-v2 |
| Similarity search | scikit-learn cosine similarity |
| Query enrichment | Gemini 2.5 Flash |
| Image understanding | Gemini Vision |
| Song metadata | Spotify Web API |
| Backend | FastAPI + Uvicorn |
| Frontend | React + Vite |
Challenges We Ran Into
Spotify mismatch. The Spotify search API returns something even when the exact song isn't on the platform — leading to confidently wrong links. We implemented a fuzzy match validator that compares the returned title and artist against the query before accepting the result, returning null rather than a wrong link.
Compute constraints. Embedding 500,000 lyric documents is expensive. We precomputed the entire matrix offline, reducing inference-time compute to a single cosine similarity operation against the query vector — fast enough to run on CPU without a GPU.
Time constraints. With 36 hours on the clock, every architectural decision was a tradeoff between correctness and speed. We made deliberate choices to keep the stack simple — a single Python module for the pipeline, FastAPI for the backend, precomputed embeddings on disk — rather than reaching for more sophisticated infrastructure that would have consumed the clock.
Multimodal tradeoff. Rather than re-embedding the full corpus with CLIP, we used an LLM-as-bridge (image → text → embedding), which was a pragmatic hackathon tradeoff that let us ship multimodal support without rebuilding the index.
Accomplishments That We're Proud Of
- Building a semantic search pipeline over half a million songs that runs on CPU in real time
- Shipping a fully working image-to-music recommendation feature in under 36 hours
- Designing an explainability layer that gives every recommendation a human-readable reason without adding significant latency
- Keeping the entire pipeline clean enough that the same
recommend()function powers both text and image queries
What We Learned
- Semantic search over lyrics is surprisingly effective at capturing feeling, not just topic
- LLM enrichment as a preprocessing step dramatically improves retrieval quality for short, abstract queries
- Batching LLM calls and deferring external API lookups to the end of a pipeline makes a measurable difference in perceived responsiveness
- Shipping something real in 36 hours requires ruthless prioritisation — good enough architecture that works beats perfect architecture that doesn't ship
What's Next for Vibe Engine
- Faster search — swap cosine similarity over the full matrix for FAISS approximate nearest neighbour search to cut query latency on larger corpora
- True multimodal embeddings — replace the LLM bridge with a CLIP-based index so image queries match directly in embedding space without the text intermediate
- Personalisation — let users thumbs-up or thumbs-down results to shift the query vector in real time
- Playlist generation — extend from 10 songs to a full coherent playlist with arc and energy curve
- Expanded corpus — move beyond lyrics to incorporate audio features, tempo, and key for a richer match signal
Built at Hackalytics 2026.
Built With
- all-minilm-l6-v2
- fastapi
- gemini-2.5-flash
- google-colab
- google-drive
- google-gemini-api
- numpy
- numpy-binary
- pandas
- parquet
- pyarrow
- pyspark
- python
- python-dotenv
- python-multipart
- react
- scikit-learn
- spotify
- spotipy
- uvicorn


Log in or sign up for Devpost to join the conversation.