-
-
Landing
-
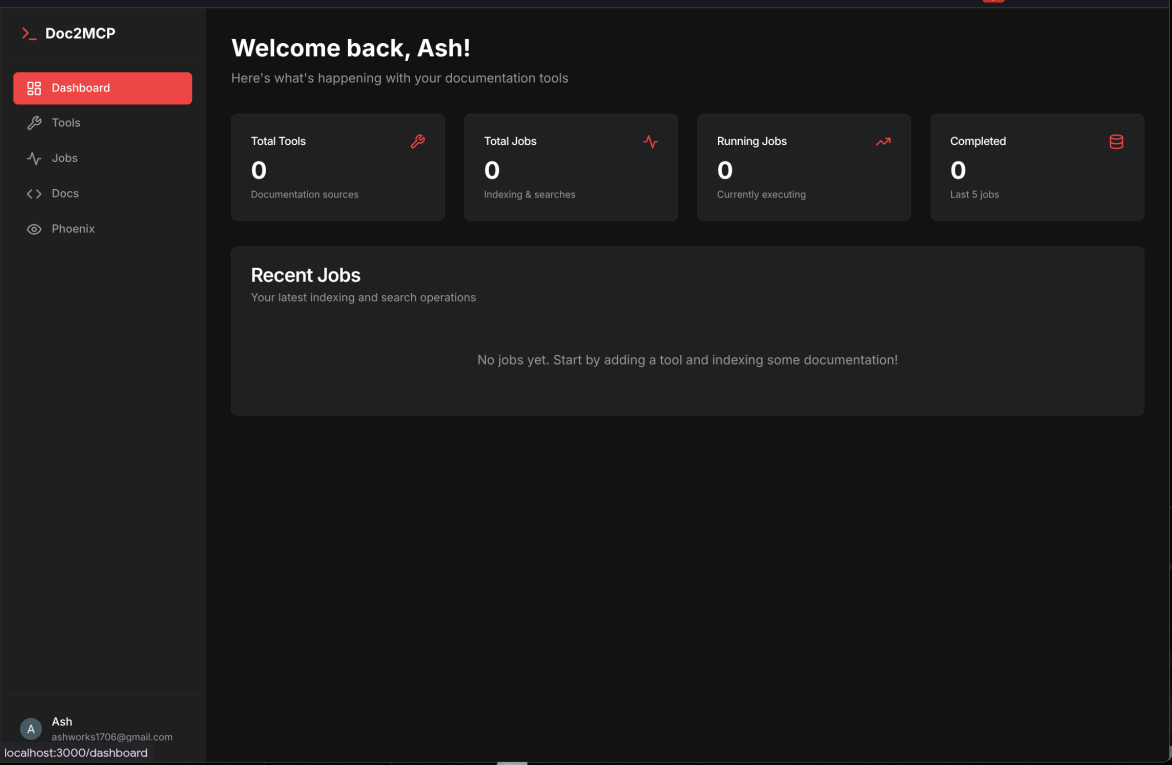
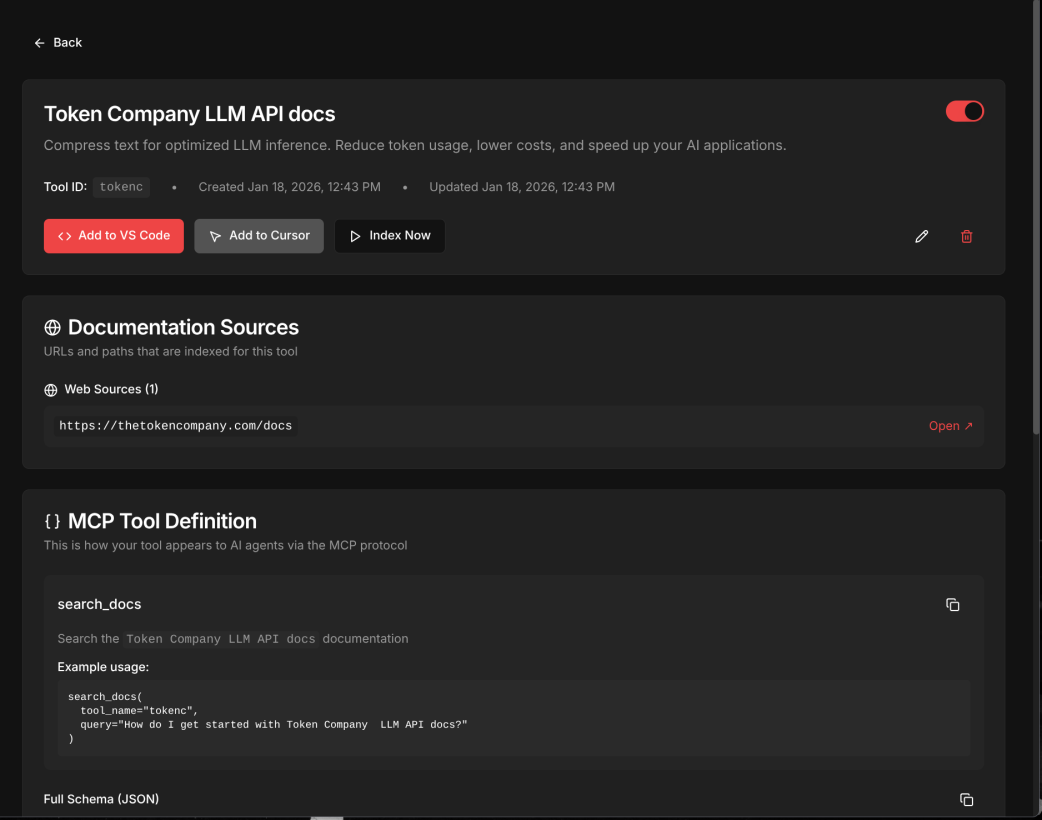
MCP Creation Dashboard
-
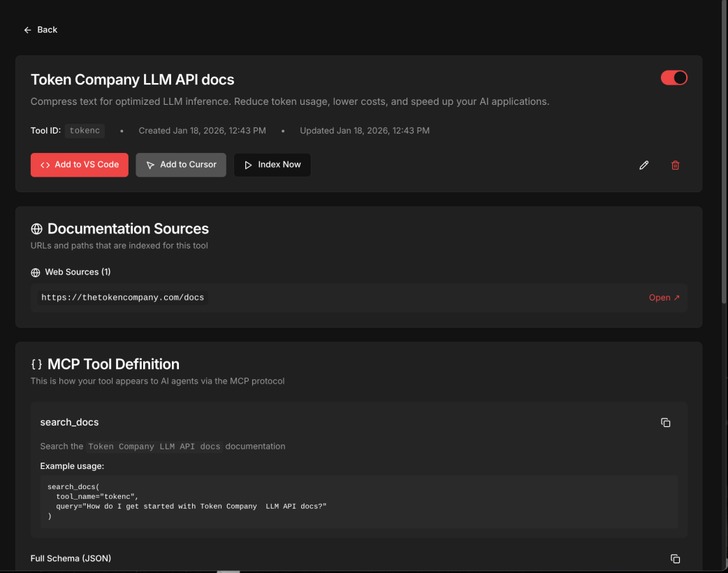
Doc Config
-
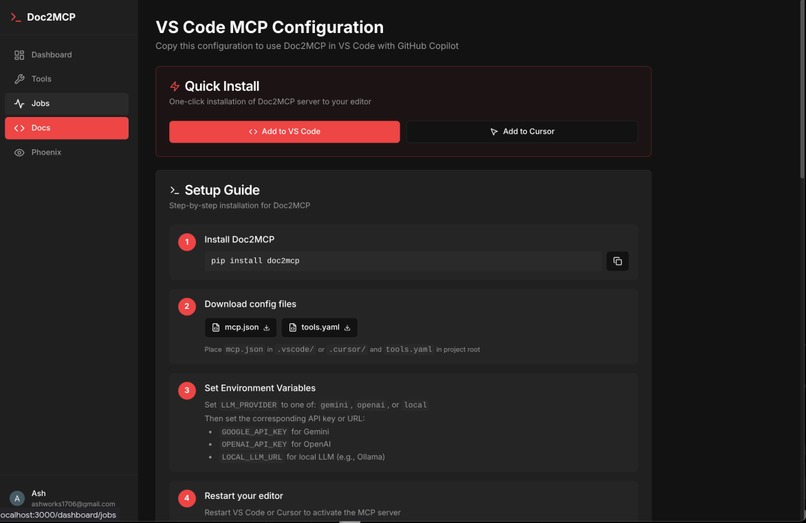
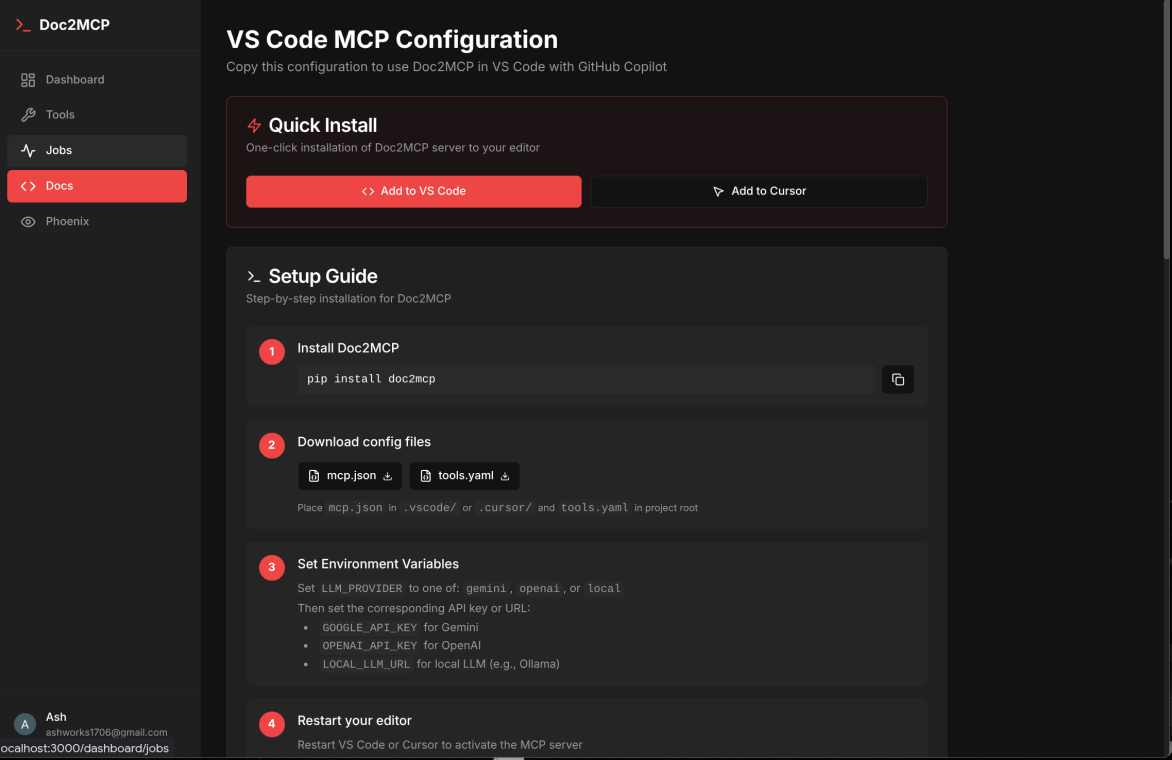
In-built Multi-IDE config support
-
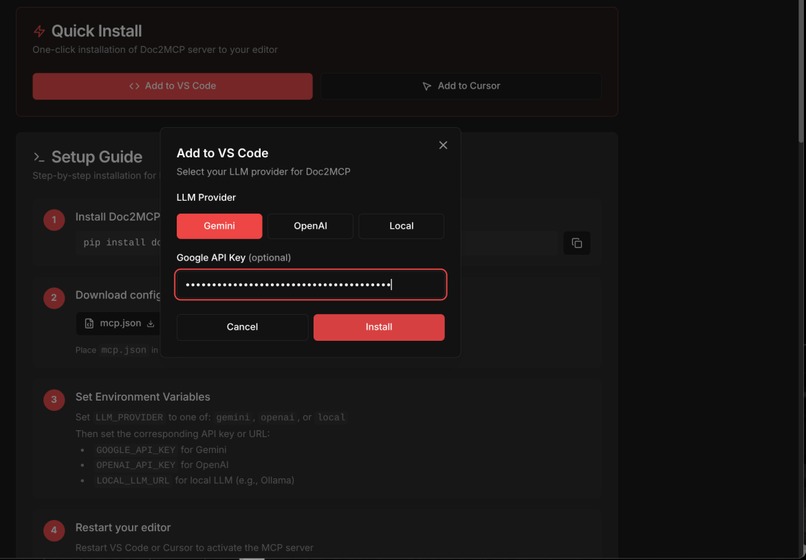
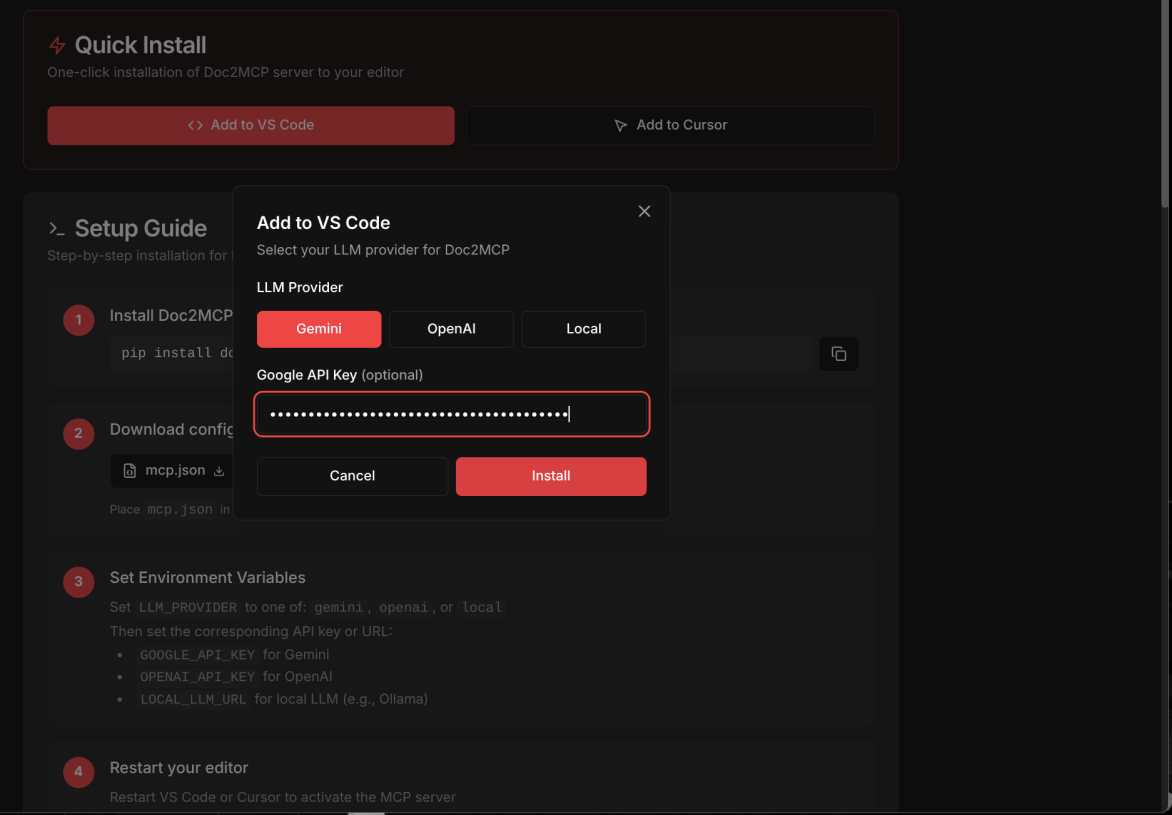
BOYK config for multiple providers
-
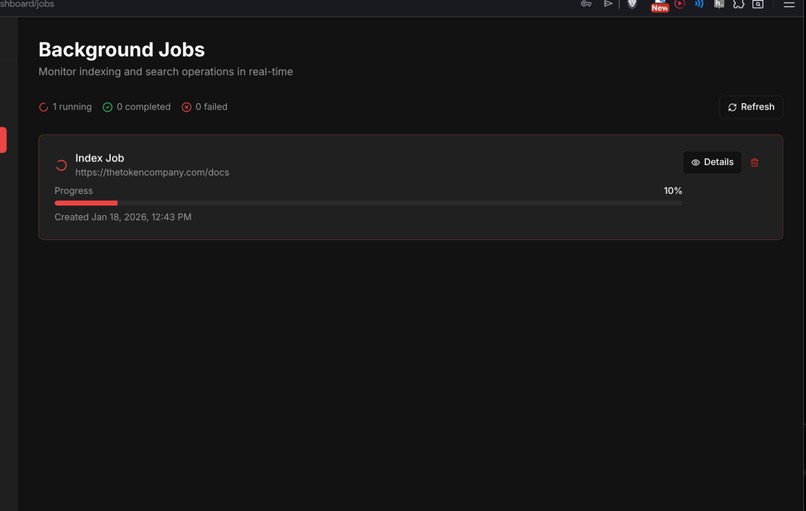
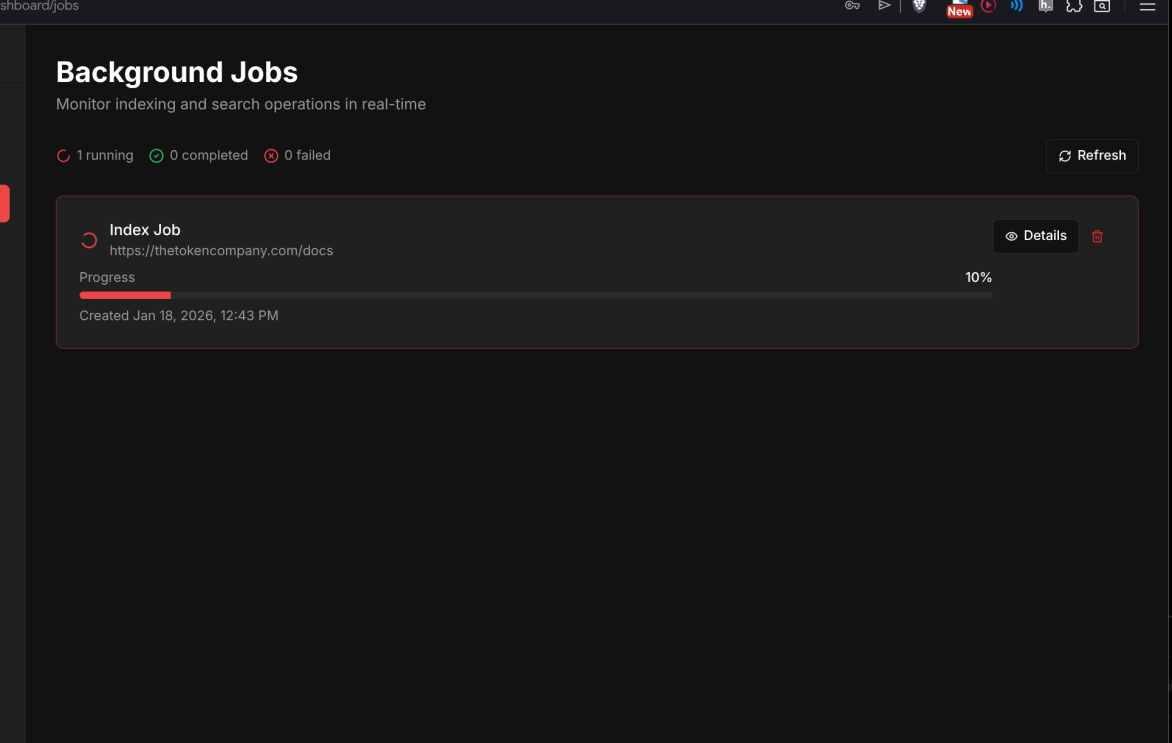
Jobs Indexing
-
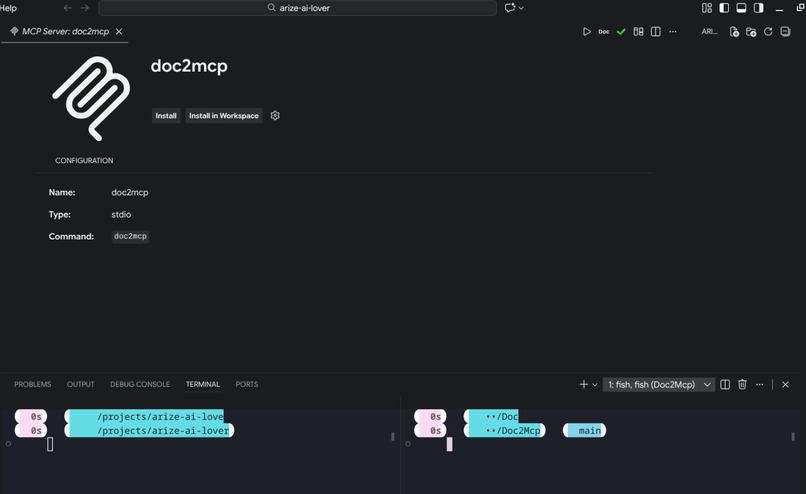
MCP in VS Code
-
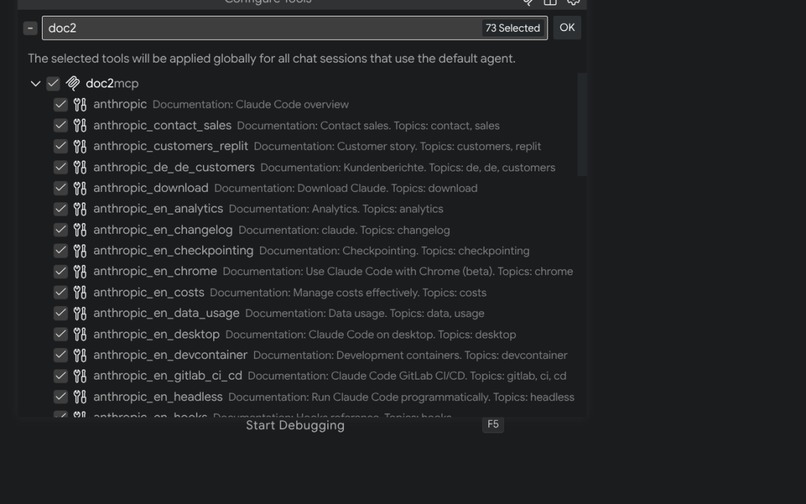
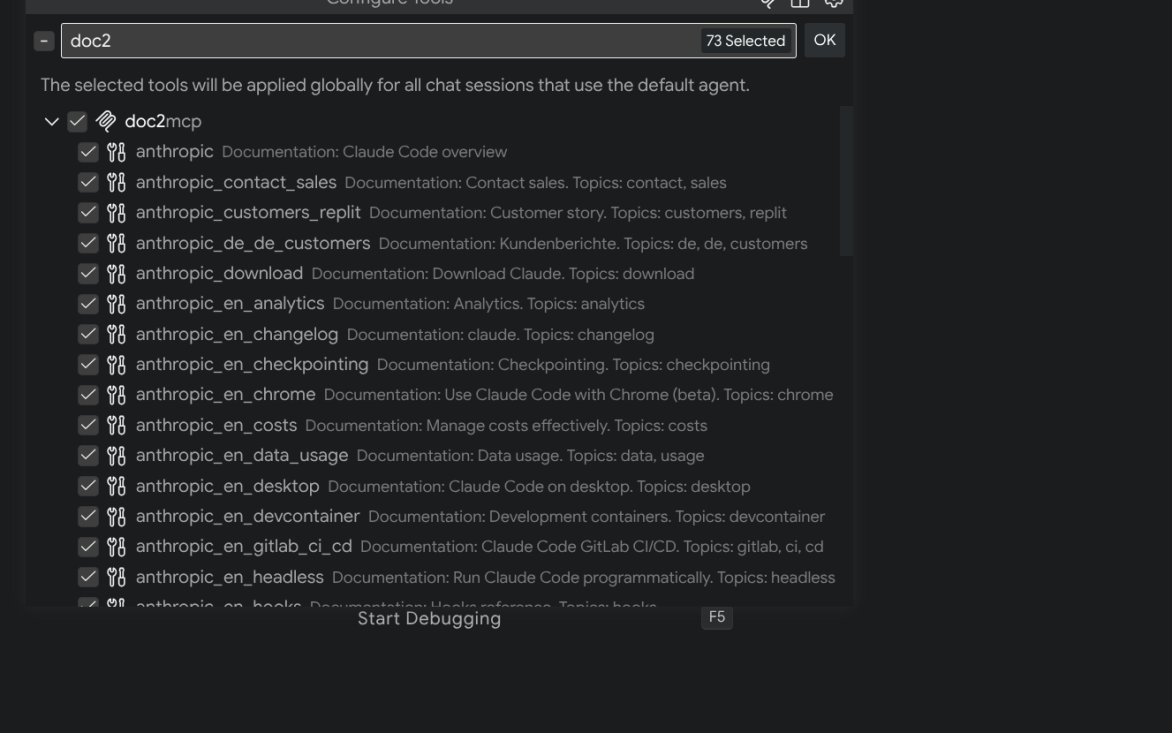
Tools in VS code accessible by Copilot
-
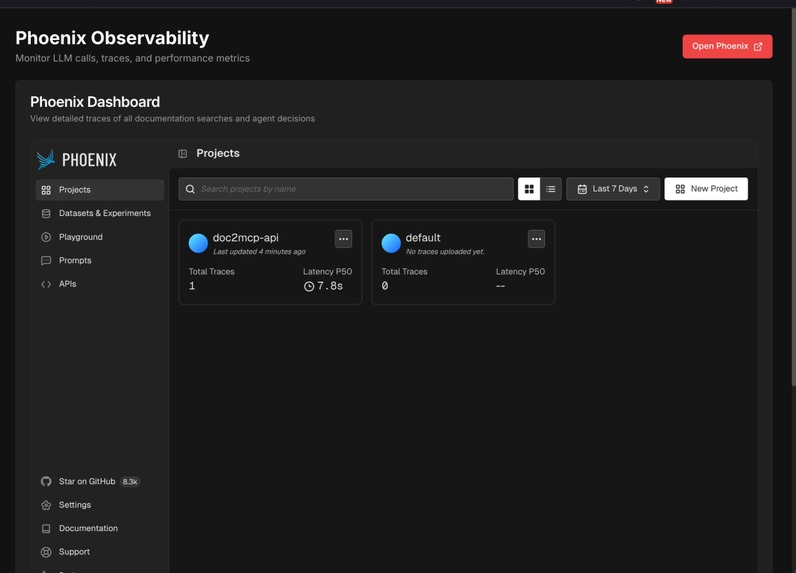
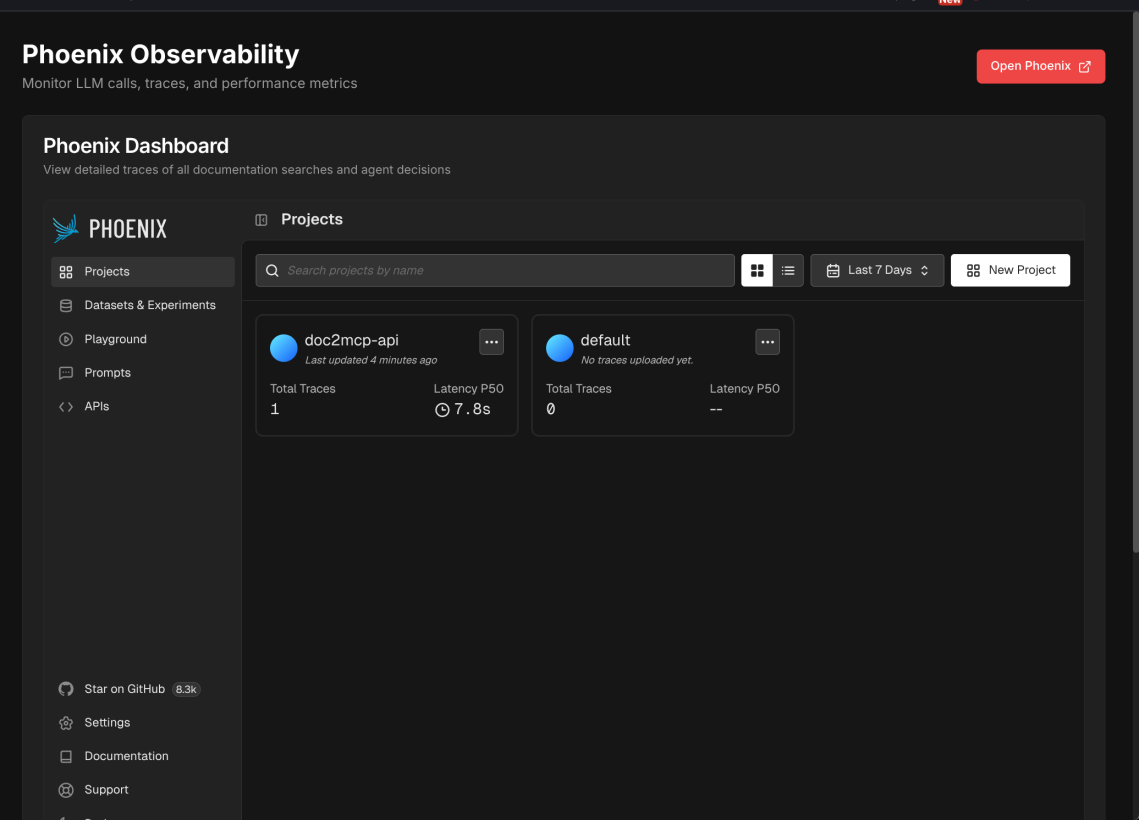
Phoenix Dashboard
-
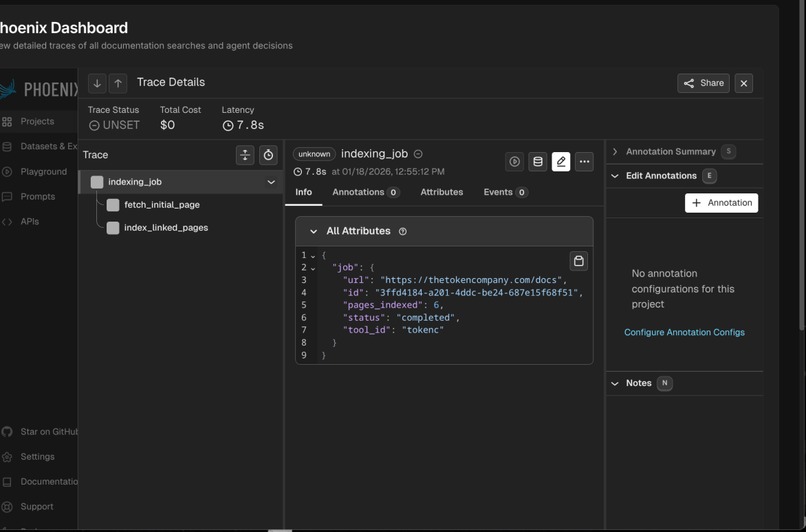
Arize AI Trace
Doc2MCP - Hackathon Submission
Inspiration
When we started this hackathon, we had a completely different idea. We wanted to build something with Babylon.js, but we hit a wall almost immediately. The documentation was scattered across dozens of pages, the API surface was massive, and there was no MCP we could plug into our coding assistant to help us vibe code faster. We spent more time fighting with docs than actually building. Eventually, we dropped the project entirely out of frustration. We were about to give up on the hackathon when we realized: if we're struggling this hard, so is everyone else. That's when we decided to stop building around the problem and start solving it. Doc2MCP was born from that frustration - a platform that turns any documentation into an MCP server so developers never have to abandon a project just because the docs are a mess.
What it does
Doc2MCP turns any documentation into an MCP server that plugs directly into your coding assistant.
The problem: AI coding assistants hallucinate when they don't know your library. They guess function signatures, invent parameters, and waste your time.
The solution: Paste a docs URL → our Gemini-powered agent crawls it intelligently → you get a working MCP in minutes → GitHub Copilot and Claude can now query it in real-time.
The platform:
- Web dashboard — manage doc sources, track indexing jobs with live progress, and result tracing, thanks to Arize.AI
- Smart crawling — automatic sitemap discovery, intelligent link following
- MCP generation — one-click VS Code config export
- Full observability — every search traced through Arize Phoenix
- Cost-efficient — The Token Company's bear-1 compression keeps token costs low on massive doc sites
- The result: Grounded code generation for any library, no matter how niche or poorly documented.
How we built it
Frontend — Next.js 14 with TypeScript, Clerk auth, Prisma + SQLite, and shadcn/ui. Users add doc sources, monitor indexing jobs via WebSocket, and export MCP configs for VS Code with one click.
Backend — FastAPI with Redis-backed job queue. Handles async document processing and streams real-time progress to the frontend.
Doc2MCP Agent — The core. A Python MCP server that uses Google Gemini to intelligently crawl documentation, deciding which links to follow based on your query. Jina Reader handles web scraping. Smart caching stores page summaries so repeat queries are instant.
The Token Company Integration — Every page the agent analyzes gets compressed through bear-1 before hitting the LLM. We use two compression tiers: 0.4 aggressiveness during exploration, 0.3 during synthesis to preserve detail. This is what makes crawling large doc sites economically viable.
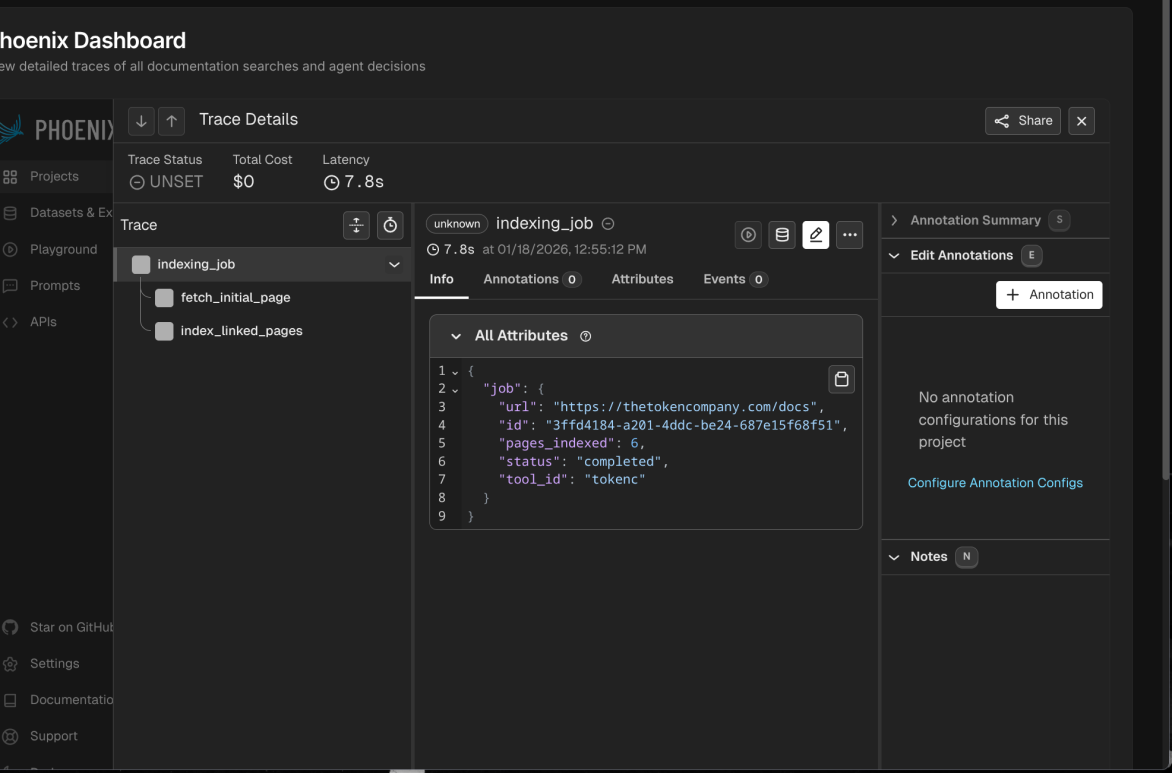
Arize Phoenix Integration — Full OpenTelemetry tracing on every operation. Every navigation decision, every LLM call, every compression ratio is logged. We used Phoenix's prompt playground to iterate on our navigation prompts until the agent stopped wandering through irrelevant pages.
Infrastructure — Docker Compose orchestrates everything: frontend, backend, Redis, and Phoenix. One command spins up the entire stack.
The Role of The Token Company
Documentation pages are verbose. A single API reference page can be 10,000+ tokens of boilerplate, navigation chrome, and repetitive examples. Our agent visits multiple pages per query, and each page gets analyzed by Gemini. Without compression, we'd burn through API credits faster than we could demo.
That's where The Token Company's bear-1 model became essential.
We integrated tokenc at two critical points in the pipeline:
During exploration (0.4 aggressiveness) — When the agent fetches a page to decide where to navigate next, we compress the content before sending it to Gemini. This is moderate compression that strips boilerplate while preserving enough structure for the LLM to understand the page layout and identify promising links.
During synthesis (0.3 aggressiveness) — When we've collected relevant excerpts and need to generate the final answer, we use lighter compression. Accuracy matters more here, so we preserve more detail while still cutting redundant content.
Every compression operation is traced with exact metrics: original tokens, compressed tokens, tokens saved, compression ratio. On a typical search across 5-6 documentation pages, we see 40-60% token reduction without meaningful information loss.
bear-1 is what makes Doc2MCP economically viable. Without it, the per-query cost would make the product impractical for regular use. With it, we can crawl extensive documentation sites and still keep costs manageable.
The Role of Arize Phoenix
Our agent was broken initially, and we had no idea why. Searches returned irrelevant content or nothing at all. The navigation seemed random. We were debugging blind.
Phoenix gave us visibility into every decision the agent made.
We instrumented three key spans:
doc_search— the overall search operation with query and tool namenav_decision— per-page analysis with URL, compression metrics, and navigation choicessynthesis— final answer generation with compression stats
What the traces revealed:
The agent was re-visiting the same URLs because our visited-set logic had a bug. We saw it in the traces immediately — the same URL appearing in multiple nav_decision spans within a single search.
The navigation prompts were too vague. Traces showed Gemini returning generic link suggestions instead of prioritizing API references and guides. We tightened the system prompt and saw immediate improvement in link quality.
Compression was sometimes failing silently. Traces showed was_compressed: false on content that should have been compressed — turned out we had a minimum length threshold that was too high.
Without Phoenix, we'd still be guessing. The traces turned a black-box agent into something we could actually debug and improve systematically.
Challenges we ran into
Intelligent navigation without brute-force crawling — Documentation sites can have thousands of pages. We couldn't fetch everything upfront. The solution was using Gemini to analyze each page and decide which links were worth following based on the user's query. Getting this navigation logic right took multiple iterations.
Making it economically viable — Our agent makes multiple LLM calls per search: one per page visited, plus a final synthesis call. Without compression, costs would spiral on large doc sites. Integrating The Token Company's bear-1 model at two compression tiers (exploration vs. synthesis) was essential.
Debugging an agent that runs in loops — Early versions would fetch the same pages repeatedly or wander into irrelevant sections. Without observability, we had no idea why. Phoenix tracing revealed the exact decision points where things went wrong.
MCP protocol integration — MCP is new. Getting the server to expose tools correctly, handle stdio transport, and integrate with VS Code's config format required reading specs carefully and testing against real clients.
Real-time job monitoring — Long-running indexing jobs need progress feedback. We built WebSocket streaming from FastAPI to Next.js so users see live updates as pages get crawled and indexed.
Accomplishments we're proud of
It actually works — Not a mockup. You can add a docs URL, watch it index in real-time, export the MCP config, and use it in VS Code immediately.
One-command deployment — docker-compose up spins up the full stack: Next.js frontend, FastAPI backend, Redis queue, Phoenix observability.
Intelligent crawling — The agent doesn't fetch everything. It navigates based on your query, which makes it fast and cost-effective.
Two-tier compression pipeline — Different aggressiveness levels for exploration vs. synthesis, all traced with exact token savings.
Full observability — Every LLM call, every navigation decision, every compression operation is visible in Phoenix.
Clean architecture — Separation between the web platform, the job queue, and the MCP server. Each component can run independently.
What we learned
Observability isn't optional for agents — You cannot debug agentic systems without tracing. Phoenix paid for itself in the first hour of debugging.
Compression changes the economics — The difference between "costs too much to use" and "viable product" was bear-1 integration.
MCP is the right abstraction — Instead of building custom integrations for every AI assistant, one MCP server works with anything that supports the protocol.
Navigation is harder than retrieval — Fetching a page is easy. Deciding which page to fetch next is the actual problem.
Cache aggressively — Page summaries, sitemap indexes, and compressed content all get cached. Repeat queries are nearly instant.
What's next for Doc2MCP
Vector search — Add embeddings for semantic similarity matching across cached documentation.
More sources — GitHub repos, Notion, Confluence, Google Docs.
Smarter refresh — Detect when docs change and re-index only updated pages.
Multi-model support — Let users choose between Gemini, Claude, GPT-4, or local models.
Team workspaces — Shared doc libraries and MCP configs across organizations.
Usage analytics — Track which queries are common, which docs get hit most, where the agent struggles.


Log in or sign up for Devpost to join the conversation.