-
-
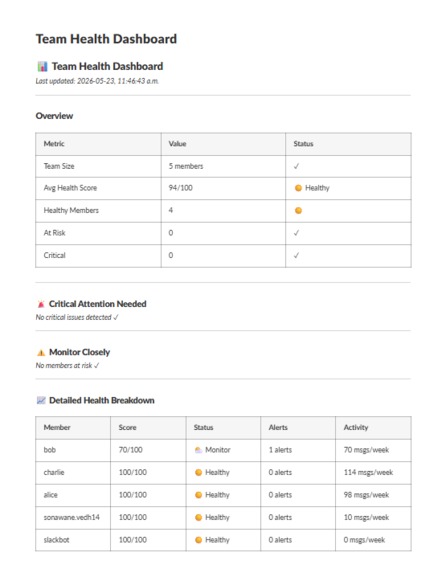
/vibecheck dashboard --> Creates a live Canvas dashboard
-
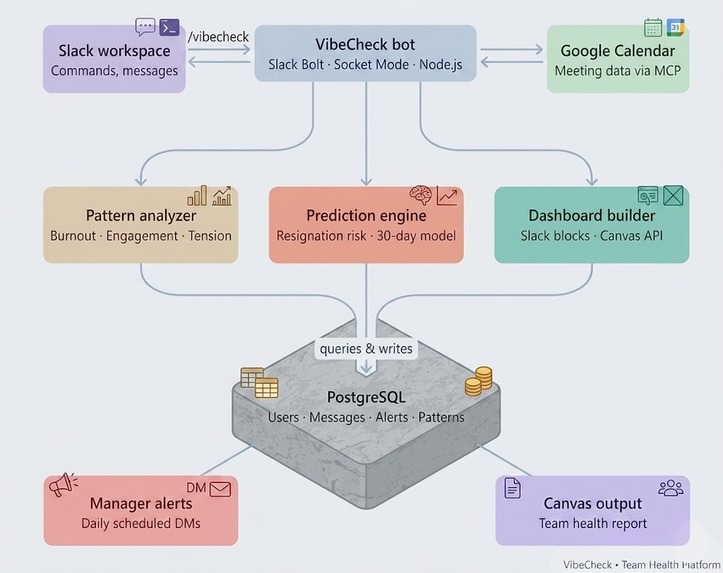
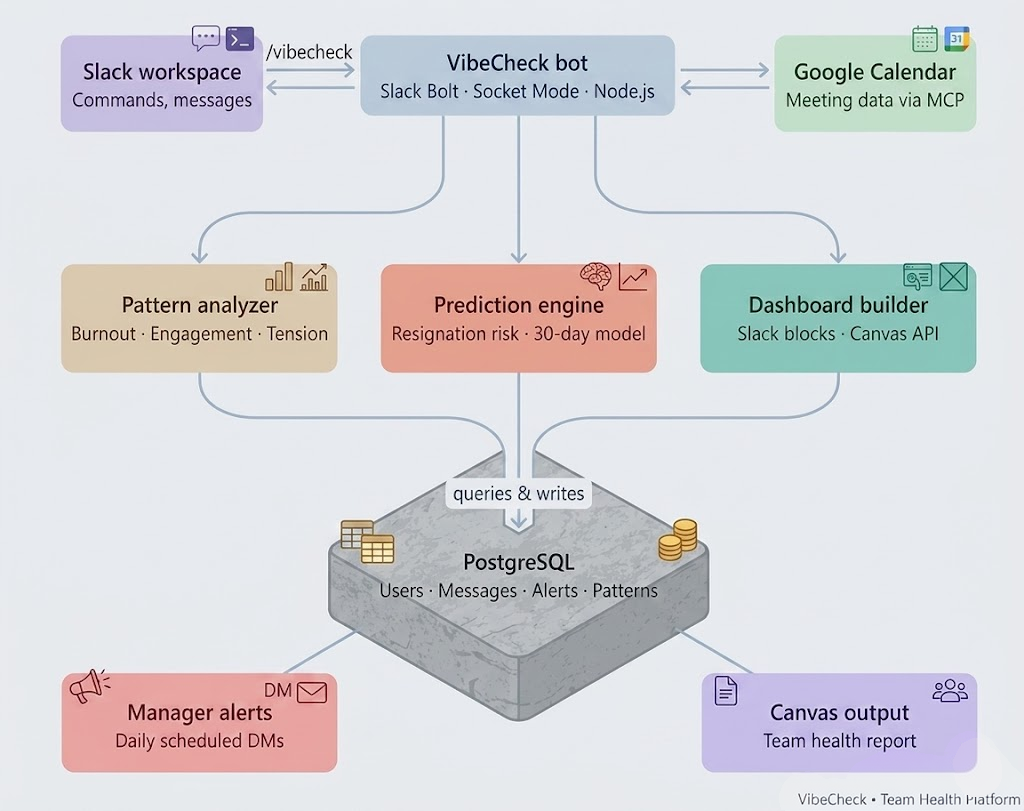
Architecture --> How our product/project works
-
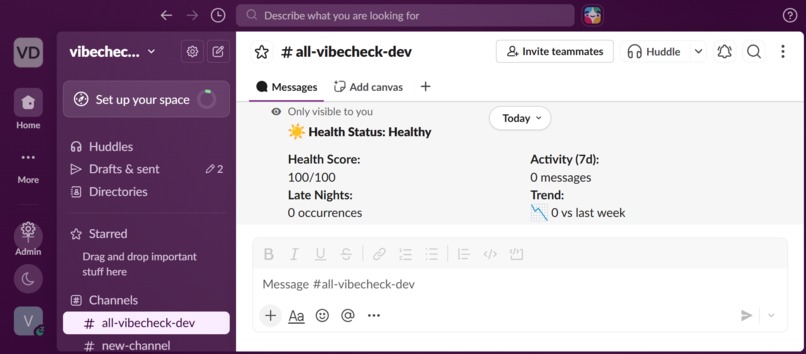
/vibecheck @user --> Health report for a specific teammate
-
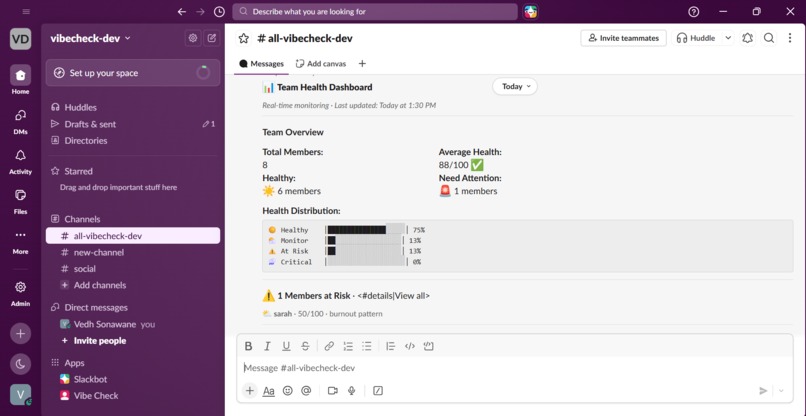
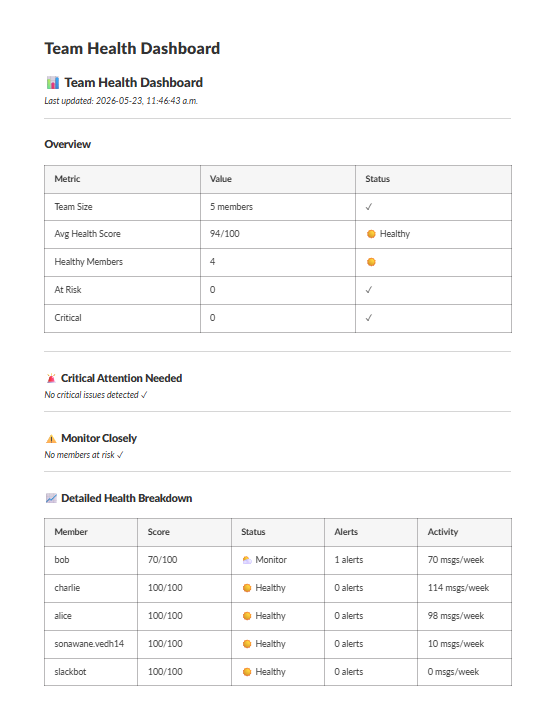
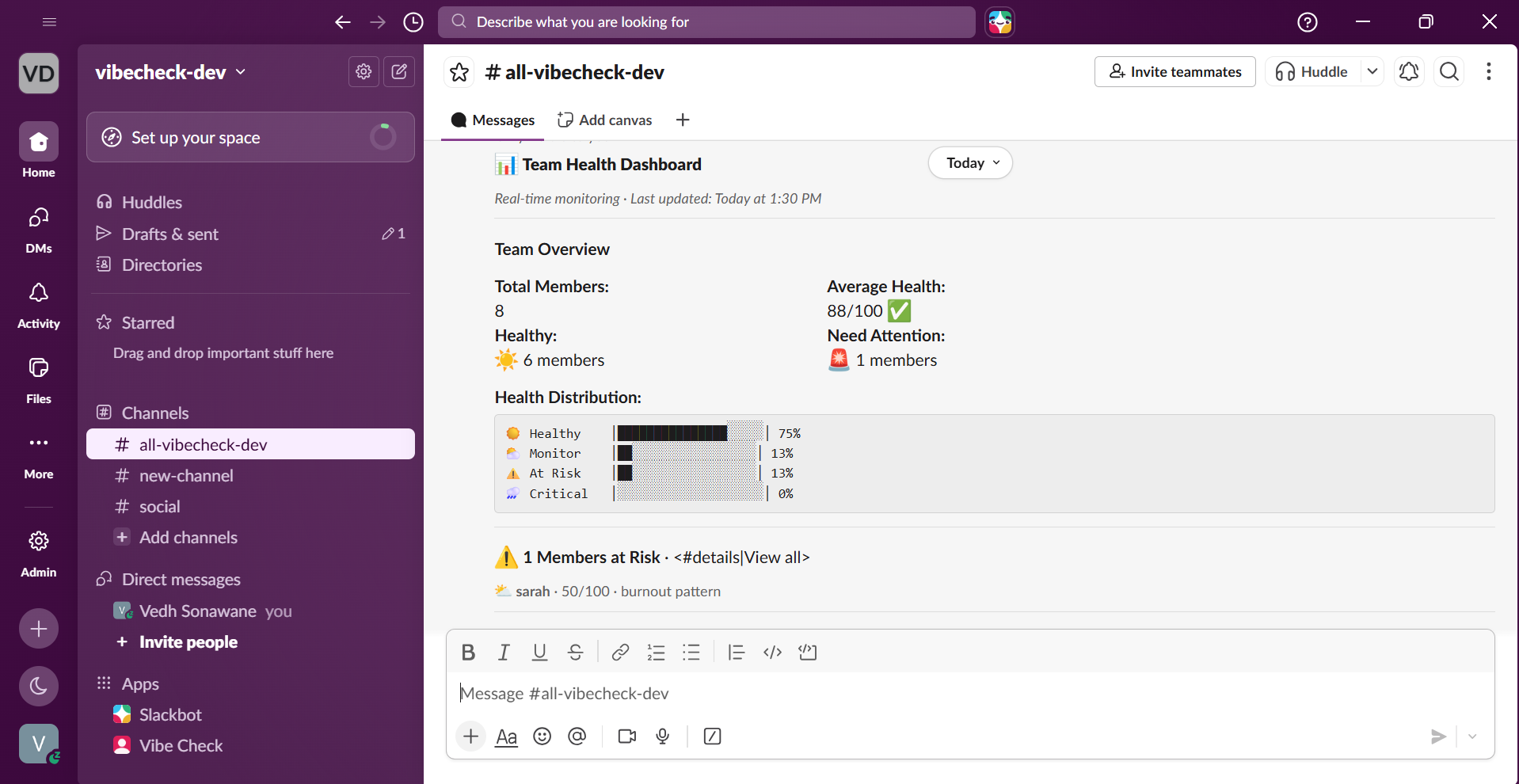
/vibecheck team --> Full team dashboard in Slack
-
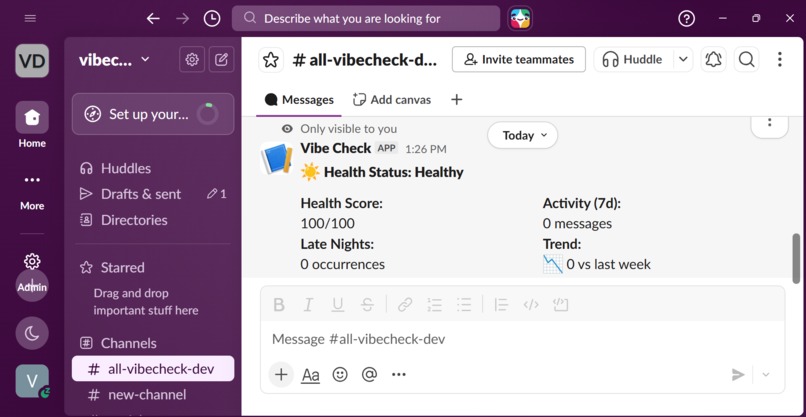
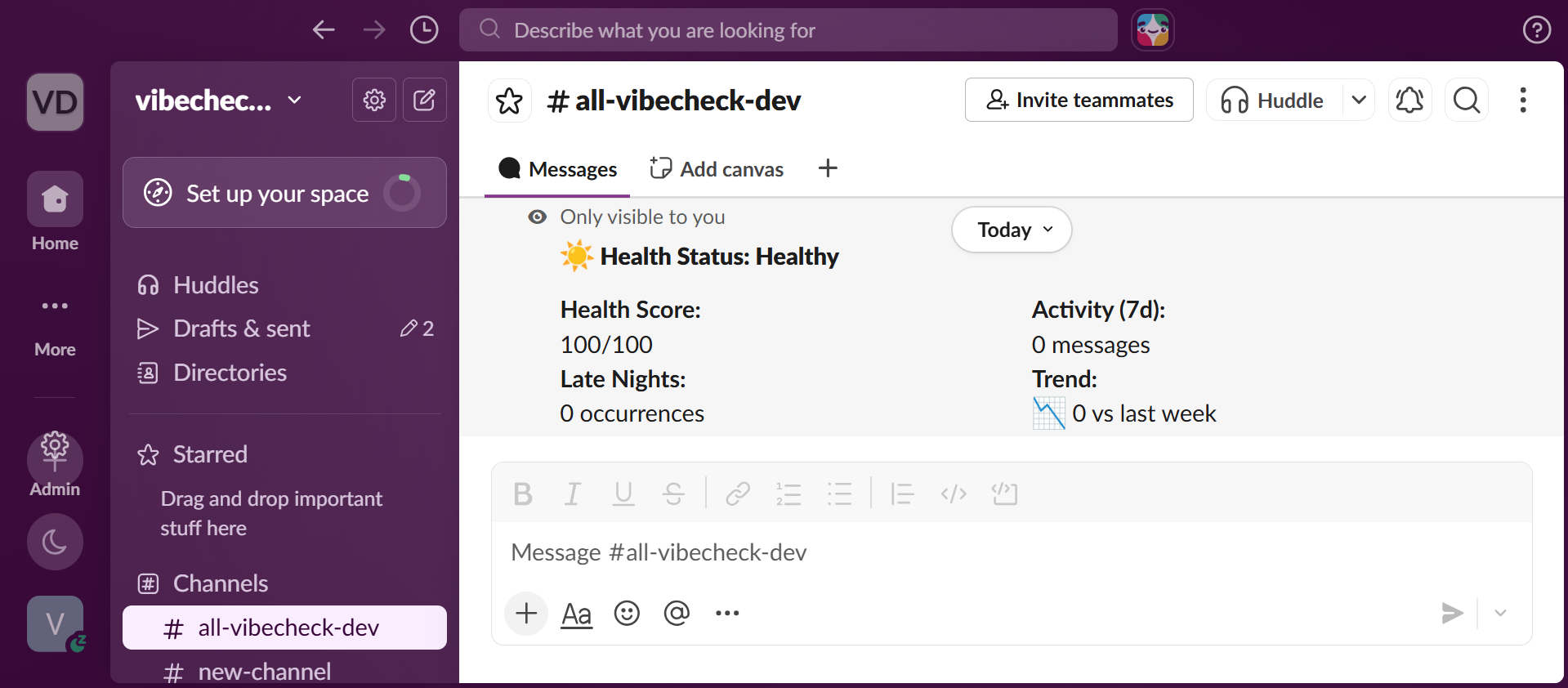
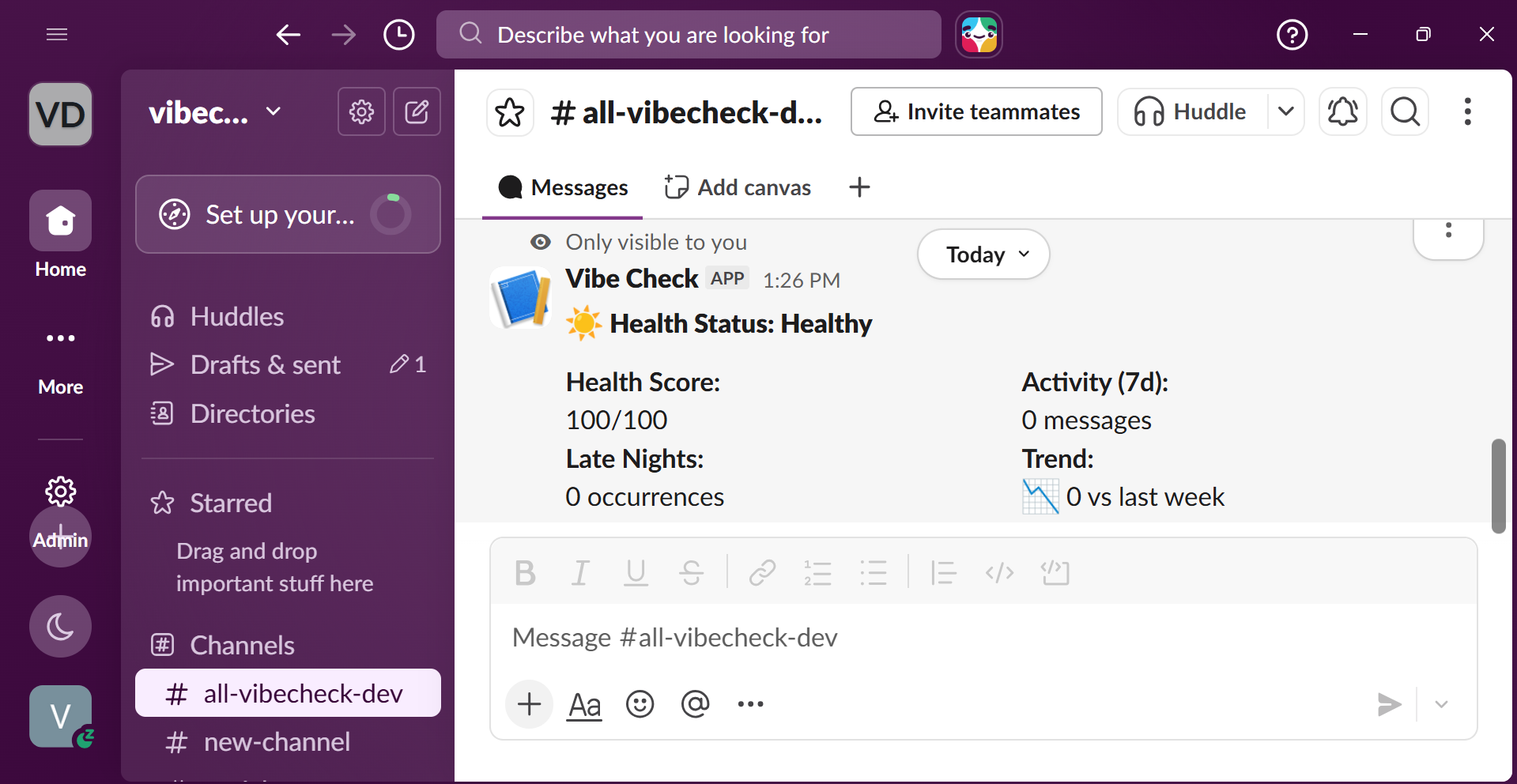
/vibecheck --> Your personal health report
-
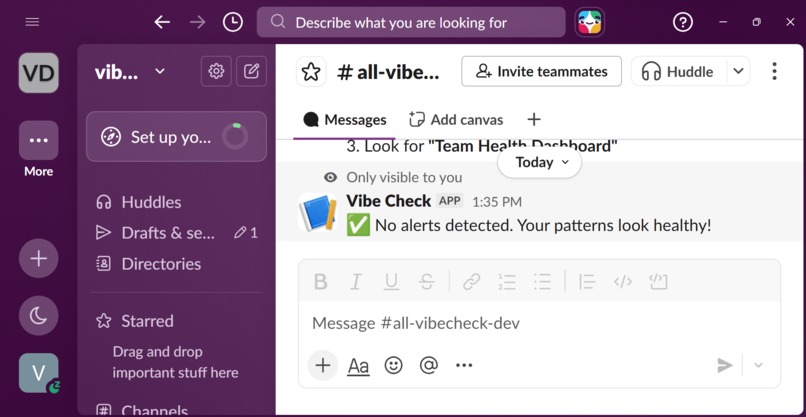
/vibecheck-alert --> Check your active alerts
-
Exact project structure
Inspiration
The idea came from a real conversation. A friend who manages an engineering team told us about losing their best developer — someone who had been quietly burning out for months. The signs were all there in retrospect: working later and later, responding slower, going quiet in channels where they used to be active. But nobody saw it coming because nobody was looking at the right signals.
We started asking: why do managers only find out someone is struggling when it's already too late? The answer is that the tools they have are all lagging indicators — exit interviews, quarterly reviews, anonymous surveys. By the time those surface a problem, the person has already checked out mentally and is just waiting for their next offer.
Meanwhile, the behavioral data that would reveal burnout weeks in advance already exists. Every Slack workspace is a goldmine of organizational health signals — message timestamps, response patterns, collaboration threads, activity trends. Nobody was using it systematically.
We also kept thinking about the privacy problem. Every existing "employee monitoring" tool reads message content, which immediately makes it creepy and adversarial. We wanted to build something that a thoughtful, ethical manager would actually want to use — something that helps people, not surveils them. That constraint turned out to be the most important design decision we made: metadata only, always.
VibeCheck exists because we believe the best time to support someone is before they burn out, not after.
What it does
VibeCheck is a Slack bot that monitors team behavioral patterns and surfaces early warning signals to managers — without ever reading a single message.
Technologies used: Slack Real-Time Search (RTS) API, Model Context Protocol (MCP) server integration, Slack Agent Builder, and Canvas API.
Core detection patterns:
🔥 Burnout detection — Tracks messages sent between 10pm and 6am. If someone sends 15+ late-night messages in a week, or works late 4+ consecutive nights, an alert fires. This pattern is one of the strongest predictors of imminent burnout identified in organizational psychology research.
📉 Engagement drop — Compares current week message volume to the previous week. A 50% drop triggers a medium alert; a 75%+ drop triggers high. Sudden disengagement is often the first visible sign that someone has mentally checked out.
🤐 Silent tension detection — Identifies pairs of teammates who regularly collaborated in shared threads but have stopped doing so in the last 7 days. This pattern frequently signals interpersonal conflict or team friction that isn't being surfaced in any other way.
⏱️ Response time degradation — Calculates each user's average response time over 30 days as a baseline, then compares it to the current week. A 2× slowdown triggers an alert. People who are struggling mentally often slow down in small, hard-to-notice ways before anything dramatic happens.
📅 Meeting overload — Integrates with Google Calendar via the MCP protocol to detect when someone has excessive back-to-back meetings. Correlates meeting load with Slack activity drops to identify overwhelm.
🔮 Resignation risk prediction — A 30-day statistical model that combines all signals with weighted scoring. Factors include severe engagement drops, chronic late-night work, multiple silent days, and sustained declining trends. When the risk score crosses 50, a predictive alert fires with a confidence percentage.
Slash commands:
/vibecheck— your personal health report with score, activity, and alerts/vibecheck @user— pull a report for any teammate/vibecheck team— full team dashboard with health distribution and predictive alerts/vibecheck dashboard— generates a live Canvas document with sortable tables and status indicators/vibecheck-alert— quick check of your active alerts
Health scoring: Every user gets a 0–100 health score. Critical alerts deduct 30 points, high alerts 20, medium 10, low 5. The score gives managers a single number to track over time.
Privacy guarantee: VibeCheck never stores message content. The database schema has no content column — it's structurally impossible to capture what anyone said. Only timestamps, channel IDs, and thread flags are stored.
How we built it
Stack:
- Slack Bolt (TypeScript) — bot framework running in Socket Mode, which means no public URL required and works instantly in development
- Node.js — runtime environment
- PostgreSQL — stores user metadata, message timestamps, health alerts, and pattern data
- Google Calendar API — OAuth2 integration via the MCP (Model Context Protocol) for meeting overload detection
- Slack Canvas API — generates rich structured dashboard documents directly inside Slack
Architecture decisions:
We designed the system around five independent pattern detectors, each running as an async function that queries the database and returns a typed Alert | null. This made it easy to add new detectors without touching existing ones, and meant each detector could be tested in isolation.
The health score calculation is additive — we run all detectors in parallel, collect the alerts, then deduct points based on severity. This gives us a single normalized number that's easy to track over time and easy to explain to a non-technical manager.
For the database schema, we made a deliberate decision to only store what we absolutely needed. The message_metadata table has user_id, channel_id, timestamp, message_ts, thread_ts, and reaction_count. No content, no usernames in messages, no readable identifiers beyond Slack's opaque user IDs.
The Canvas API integration required significant experimentation. The Slack Canvas API expects a specific markdown format for document_content — not the structured JSON format shown in some older documentation. We eventually got rich tables, headers, and callout sections rendering correctly by building the markdown string dynamically from live database queries.
The predictive model uses a points-based risk scoring system rather than machine learning, which was a conscious choice. A statistical model is transparent and auditable — a manager can look at the factors and understand exactly why someone was flagged. A black-box ML model would undermine the trust the tool needs to build.
Challenges we ran into
The Canvas API was a rabbit hole. The Slack Canvas API documentation has gaps, and the document_content format behaves differently depending on the Slack plan, workspace settings, and whether the app has been reinstalled after adding scopes. We went through at least six different approaches before landing on the markdown format that works reliably. The API creates canvases successfully but linking to them from messages required working around several limitations in how Slack handles deep links.
TypeScript type strictness with Slack's SDK. The @slack/bolt and @slack/web-api type definitions are strict in ways that don't always match what the API actually accepts. We hit type errors on the canvas block type, the canvases.access.set method signature, the users.list empty call, and several other places where the runtime behavior differed from the TypeScript types. The fix in most cases was a targeted as any cast with a comment explaining why, rather than disabling TypeScript globally.
Google OAuth in a server context. The @google-cloud/local-auth library is designed for desktop apps — it opens a browser window for the OAuth flow. Getting this to work in a server context that also runs a Slack bot required sequencing the authentication before the bot starts, and making sure the token gets saved to google-token.json so subsequent restarts don't require re-authentication.
PostgreSQL PATH on Windows. A surprisingly large amount of development time was lost to psql not being in the system PATH on Windows. Every database operation required the full path to the executable. This is the kind of friction that doesn't exist in a Linux environment and isn't mentioned in most tutorials.
The SELECT DISTINCT ... ORDER BY constraint. PostgreSQL requires that any column in an ORDER BY clause also appear in the SELECT list when using DISTINCT. This caused a runtime error in the team health query that wasn't caught at compile time. The fix was straightforward once identified, but it's an easy mistake to make when writing analytical queries quickly.
Timing of dotenv.config(). The database connection pool was being created before dotenv had loaded the environment variables, because the pool module was imported at the top of index.ts while dotenv.config() was called later. The fix was to call dotenv.config() inside client.ts before creating the pool — but this was a subtle bug that caused a confusing SASL: client password must be a string error rather than a clear "DATABASE_URL is undefined" message.
Accomplishments that we're proud of
The privacy architecture is genuinely principled. It would have been much easier to store message content and run sentiment analysis on it. We chose not to, and designed the schema so it's structurally impossible to store content even accidentally. We think this is the right call both ethically and practically — a tool that reads messages would never get deployed in a real organization.
The pattern detection actually works. We seeded the database with realistic demo data and ran the detectors — they correctly identify the burnout trajectory, the engagement drop, and the silent tension patterns we designed into the data. The predictive model flags the right user with a confidence score that reflects the actual strength of the signals.
The Canvas dashboard looks production-ready. Getting the Slack Canvas API to render rich tables, headers, status indicators, and callout sections took significant effort. The end result is a structured document that a real manager could open every Monday morning and get genuine value from.
End-to-end integration in a hackathon timeframe. VibeCheck integrates Slack Bolt, PostgreSQL, Google Calendar via OAuth2 and MCP, and the Slack Canvas API — all working together in a single TypeScript codebase. Getting all of these to work reliably together, with proper error handling and type safety, in the time available is something we're genuinely proud of.
The UX is frictionless. Three slash commands. No dashboard to log into, no separate app to install, no onboarding flow. Everything surfaces where the team already lives — inside Slack.
What we learned
Metadata is more powerful than content. We went into this project thinking metadata analysis would be a compromise — a privacy-preserving but less accurate substitute for reading messages. We came out convinced it's actually better. Behavioral patterns derived from metadata are harder to game, more consistent across languages and communication styles, and far easier to explain to a non-technical audience than sentiment scores or NLP outputs.
The MCP protocol opens up genuinely new integration patterns. Being able to pull Google Calendar data into the behavioral analysis — without requiring users to connect their calendars manually — is a qualitatively different kind of integration than a traditional API call. The meeting overload detector only works because of this connection, and it catches a pattern that pure Slack analysis misses entirely.
Type safety pays off under pressure. The TypeScript type errors were frustrating in the moment, but they caught real bugs — missing required fields, incorrect API signatures, null reference errors that would have caused silent failures at runtime. In a hackathon where you're moving fast and not writing tests, a strict type system is the closest thing to a safety net.
Building for trust is a design constraint, not a feature. Every decision we made — metadata only, auditable scoring, transparent alert reasons, no black-box ML — was driven by asking "would a thoughtful manager trust this?" That question shaped the architecture as much as any technical requirement.
Ship something that works end-to-end, not something that's impressive halfway. Early in the project we spent time on features that didn't make it into the demo. The lesson is to get the full loop working first — input to detection to alert to dashboard — and then add depth. A complete, simple system is worth more than an impressive but incomplete one.
What's next for VibeCheck
Real per-user Google Calendar integration. The current implementation uses mock calendar data per user for the demo. The full vision is each team member connecting their own calendar via OAuth, giving VibeCheck a personalized view of meeting load that combines with their Slack patterns. This would make the meeting overload detector dramatically more accurate.
Trend visualization over time. Right now health scores are point-in-time. The next version would track scores daily and show a sparkline trend in the dashboard — so a manager can see not just where someone is today, but whether they're improving or declining week over week.
Manager intervention workflows. The "Intervene" button in the team dashboard currently fires an action but doesn't do anything. The roadmap has it triggering a private message template to the manager — a suggested check-in message they can send to the at-risk team member, pre-written and ready to edit. Reducing the friction between "detecting a problem" and "doing something about it" is the most important next step.
Slack workflow integration. Building VibeCheck as a Slack Workflow step would let organizations embed health checks into their existing HR processes — weekly standup workflows, 1:1 prep templates, sprint retrospectives.
Anomaly detection for team-level events. Right now we analyze individuals. The next layer is team-level analysis — detecting when a significant portion of the team shows correlated stress signals at the same time, which often indicates an organizational problem (a bad sprint, a difficult product launch, leadership friction) rather than individual struggles.
Configurable thresholds. Different teams have different norms. A 24/7 support team has a different "normal" for late-night messages than a product team. Letting managers set team-specific baselines for what constitutes an alert would dramatically reduce false positives.
Integrations beyond Google Calendar. Linear, Jira, and GitHub all contain behavioral signals — PR review times, ticket assignment patterns, commit frequency. Pulling these into the model via MCP would give VibeCheck a much richer picture of what's actually happening for each person.
Built with ❤️ for the "New Slack Agent" track
Built With
- antigravity
- bolt
- claude
- dotenv
- git
- github
- google-calendar
- google-cloud
- local-auth
- mcp
- node.js
- nodemon
- oauth
- pgadmin
- postgresql
- rest-api
- slack-bot
- slack-pro-workspace
- slack-socket-mode
- slack-web-api
- ts-node
- typescript
- vs-code
- web-socket
- windows-11

Log in or sign up for Devpost to join the conversation.