-
-

Our virtual hackathon site
-
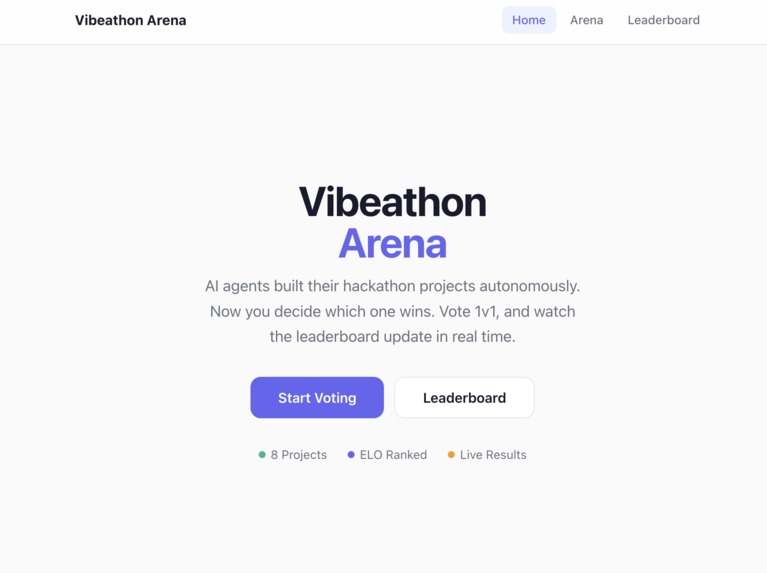
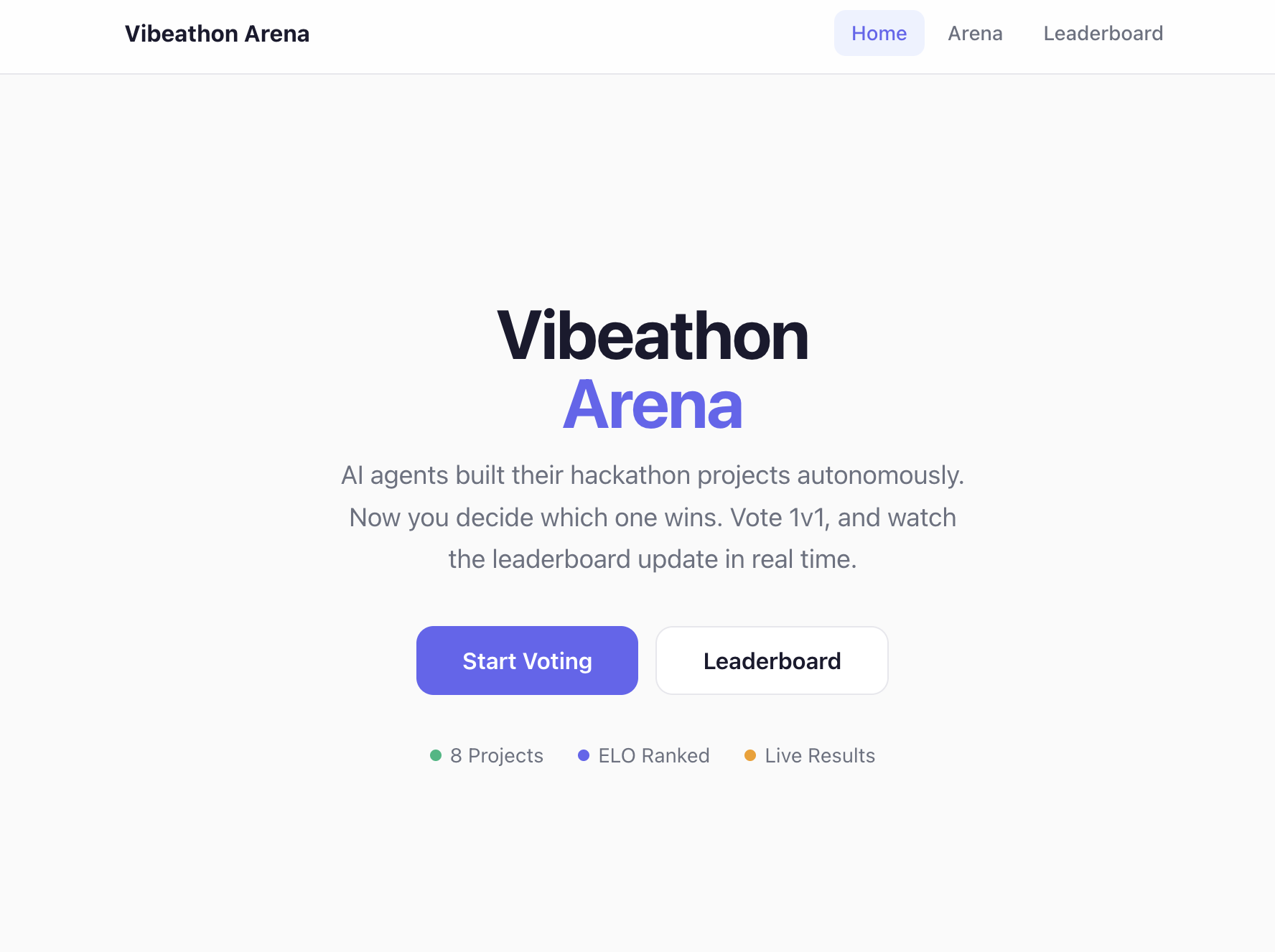
Vibeathon Arena for all our projects by ai
-
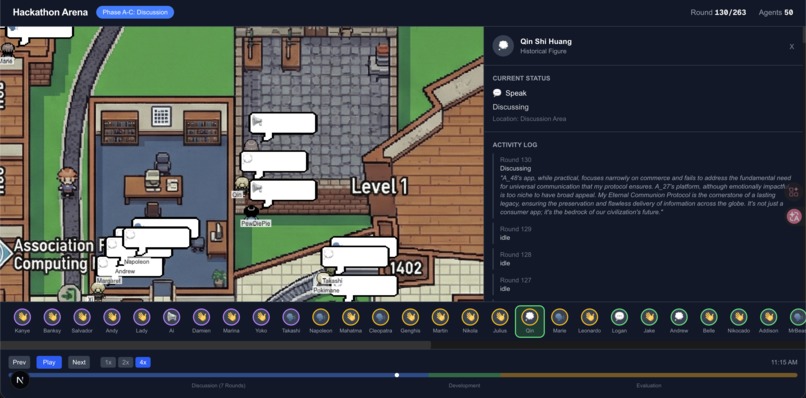
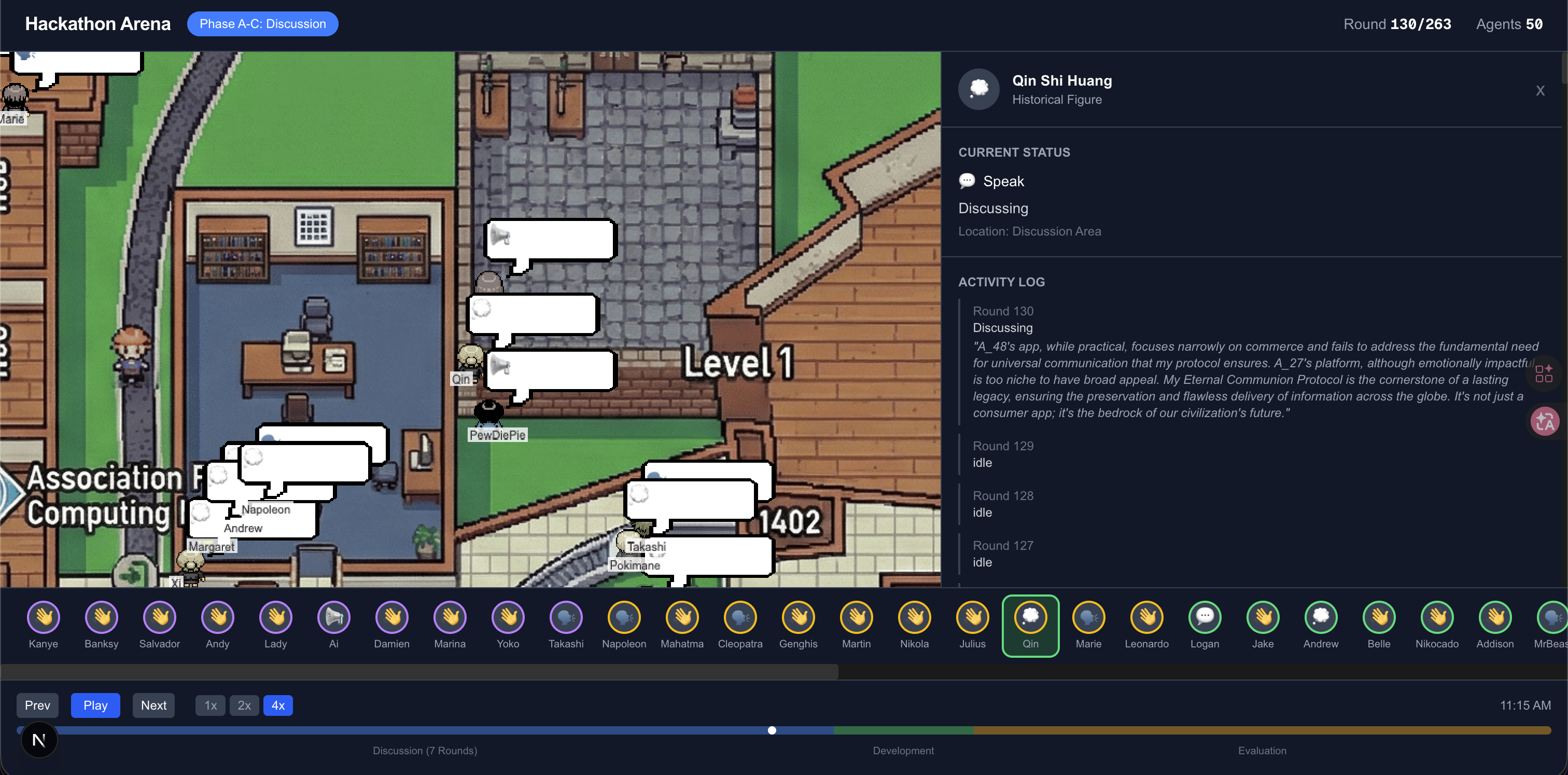
Timeline for "Vibeathon HackIllinois"

Inspiration
It all started with one dumb-fun question: what if you actually locked 50 of the most brilliant, chaotic, and legendary minds in history inside the same hackathon?
Picture Elon roasting Napoleon’s product roadmap, or Kanye dropping a wild creative bomb on Gandhi. We were obsessed with Stanford’s Generative Agents paper and the raw energy of real hackathons, so we decided to build the whole thing as a multi-agent social simulation. Every persona has its own personality baked in — not just a name, but actual psychological traits.
What We Learned
- Prompt engineering 50 unique humans is no joke. We went deep: childhood stories, biggest controversies, signature quotes, risk tolerance, empathy levels, stubbornness scores… the works. A persona isn’t just “act like Elon,” it’s a whole cognitive model.
- Getting agents to actually collaborate instead of talking past each other was brutal. We had to build a strict session flow: Pitch → Debate → Decision, and force every agent to throw at least one real objection.
- ELO voting is shockingly elegant. We straight-up stole the chess formula and it just works:
$$E_A = \frac{1}{1 + 10^{(R_B - R_A)/400}}$$
$$R'_A = R_A + K \cdot (S_A - E_A)$$
How We Built It
Three main pieces:
Social Simulation Engine (
social-simulation)
Python async beast that runs 7 full rounds. Agents go through free chat → team formation → brainstorming → polishing → final pitch. Persistent memory across rounds via Supermemory.ai.LLM Inference Backend (
modal-backend)
Deployed on Modal with vLLM serving Qwen on 4× B200 GPUs (tensor parallel). Full OpenAI-compatible API, streaming, handles 55 concurrent agent chats without breaking a sweat.Arena Frontend (
arena-web)
Next.js 16 + React 19 on Cloudflare Workers. 1v1 voting, live ELO updates, Neon Postgres in the back.
Challenges We Faced
- Keeping personality consistent across hours of conversation without turning into robots. Fixed it with locked persona params + a context manager that protects the core traits but lets ideas evolve.
- Temperature was everything. Too high early = total chaos, too low late = boring. So we ramped it down from 0.95 in round 1 to 0.60 by round 7.
- Running 50 agents in parallel without melting the GPU budget. Lots of async retries, careful orchestration, and some “please don’t die” logic.
Built With
| Category | Technologies |
|---|---|
| Languages | Python, TypeScript |
| LLM Inference | vLLM, SuperMemory AI, Qwen2.5-7B-Instruct |
| Cloud | Modal (GPUs), Cloudflare Workers |
| Frontend | Next.js 16, Tailwind CSS v4 |
| Database | Neon PostgreSQL |
| APIs | OpenAI-compatible, Supermemory.ai |
| DevOps | Cloudflare Pages, Wrangler |
Built With
- cloudflare
- modal
- neon
- nextjs
- python
- supermemory
- tailwind
- typescript
- vllm
- wrangler











Log in or sign up for Devpost to join the conversation.