Inspiration
Over 466 million people worldwide have disabling hearing loss, yet job interviews remain overwhelmingly audio-centric. Deaf and hard-of-hearing candidates face a compounding disadvantage: they must navigate real-time conversation while simultaneously proving competence-often without adequate tooling. Existing accessibility solutions (interpreters, captioning services) are expensive, inconsistent, and introduce a dependency that undermines candidate autonomy.
We asked: what if the candidate could speak for themselves-literally-using the language they already know?
VIBE (Voice Inclusion for Better Employment) bridges the gap between sign language and spoken interviews. Rather than asking candidates to adapt to an inaccessible system, VIBE adapts the system to the candidate. We chose to build an end-to-end platform rather than a single-feature tool because the interview problem isn't one obstacle-it's a chain of them: understanding the interviewer, formulating a structured response, and delivering it clearly. VIBE addresses all three.
What VIBE Does
VIBE is a two-mode AI interview platform:
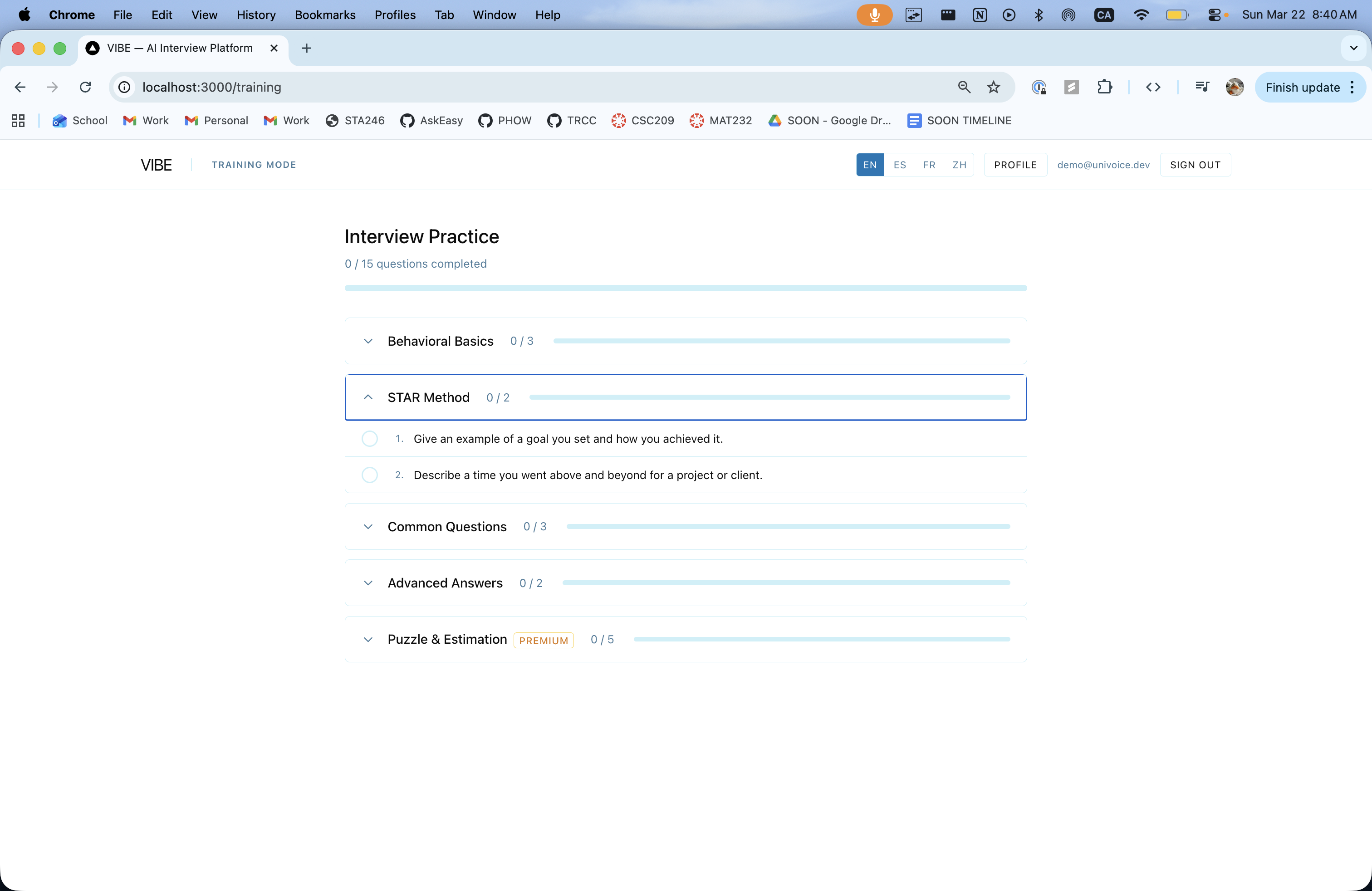
Training Mode - Practice with STAR Feedback
Candidates practice answering behavioral interview questions and receive instant, structured feedback based on the STAR method (Situation, Task, Action, Result). Each dimension is scored 0–100 with specific improvement suggestions. An AI-polished version of the answer is shown side-by-side so candidates can see how to articulate the same idea more effectively.
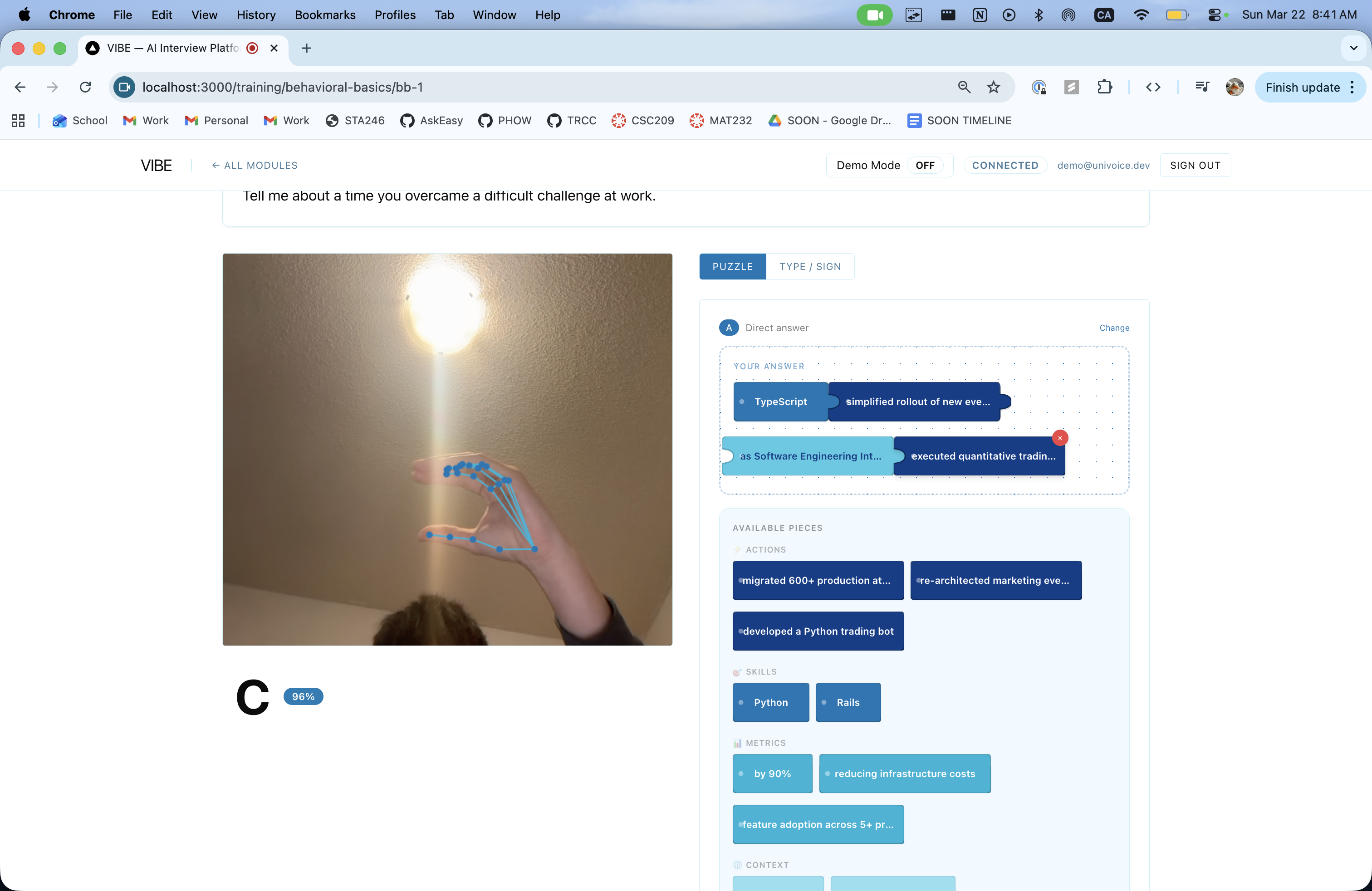
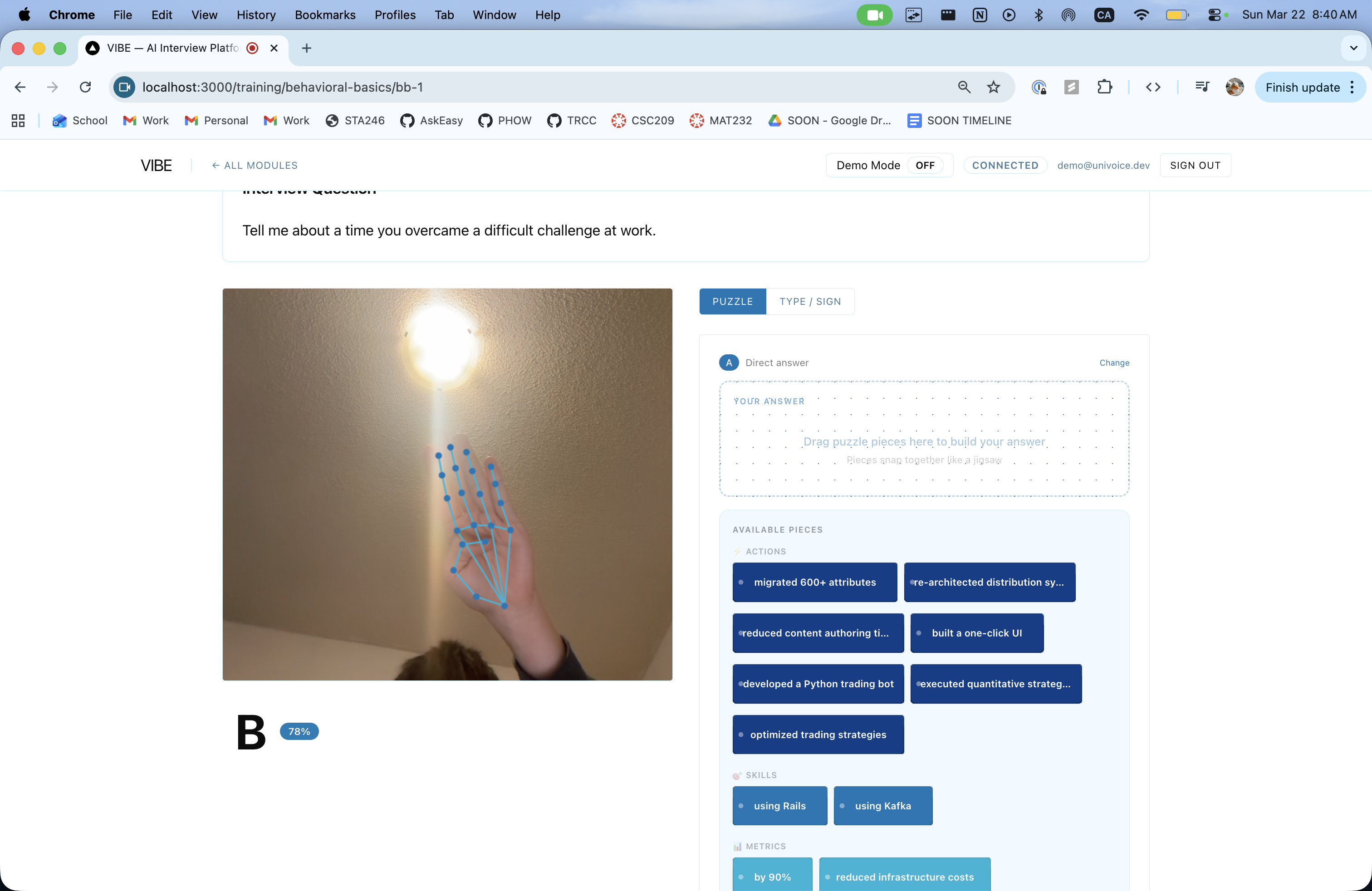
A standout feature is the Puzzle Builder-a drag-and-drop interface where candidates assemble their answer from AI-generated story fragments pulled from their own resume. Blocks snap into S/T/A/R slots, and AI-generated filler words (shown in purple) stitch them into a coherent narrative. This teaches STAR structure through doing, not lecturing.
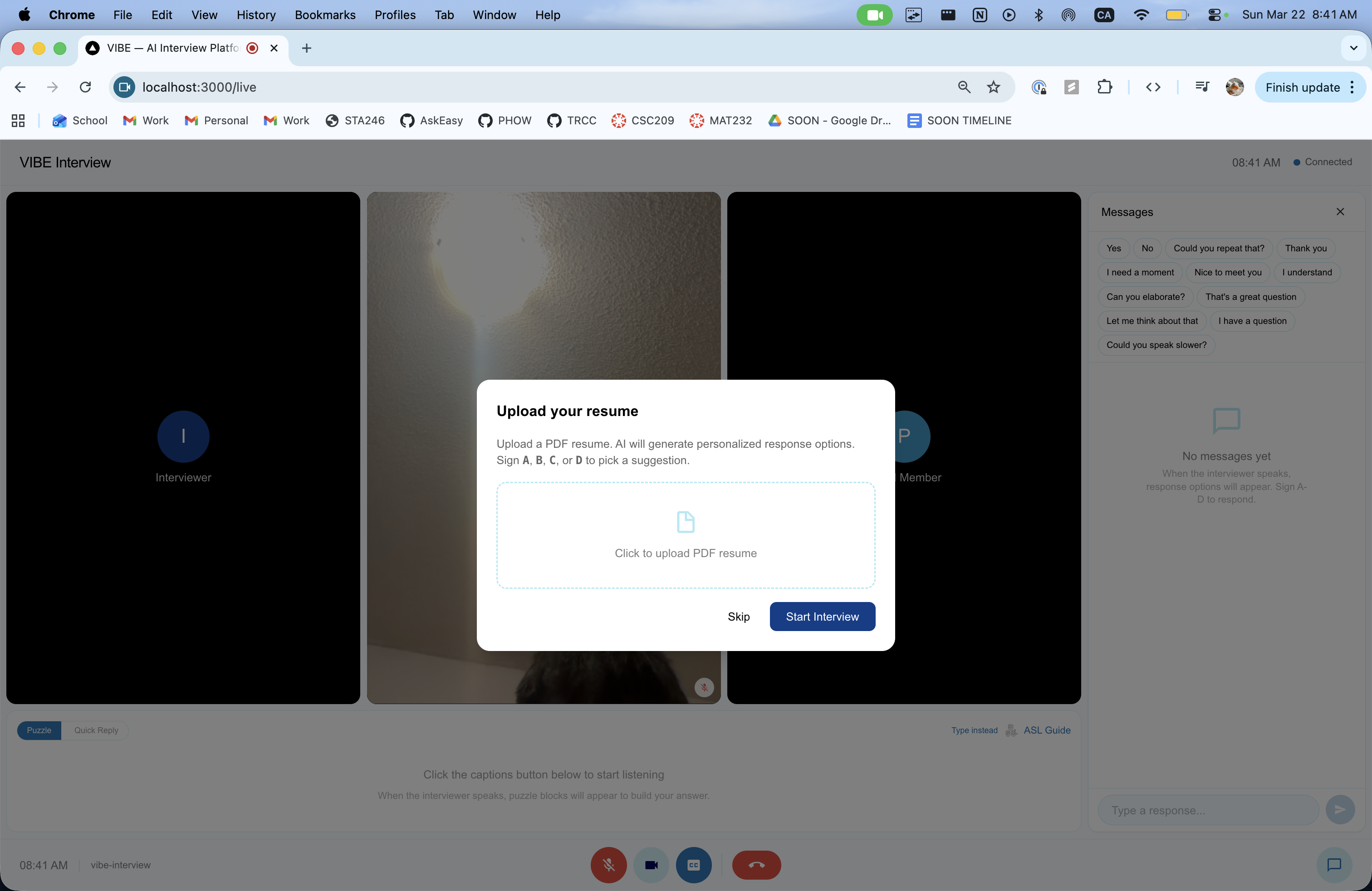
Live Mode - Real-Time Interview Communication
A three-panel interface for actual interviews:
Speech-to-Text Panel - The interviewer's speech is captured and transcribed in real time via Deepgram's nova-2 model. Interim results appear faded; final transcripts appear solid. The candidate reads the interviewer's words as they speak.
Sign-to-Speech Panel - The candidate signs ASL letters via webcam. MediaPipe detects 21 hand landmarks per frame, Fingerpose classifies them into ASL letters, and a text-building pipeline assembles words. The finished text is optionally polished by GPT-4o-mini, then spoken aloud via ElevenLabs TTS. Short phrases (< 20 characters) skip the polish step for instant delivery.
AI Suggestions Panel - After each interviewer question, four response options appear (Short, Detailed, Clarification, Pivot), selectable by ASL gesture (hold A/B/C/D for 500ms) or click. Selected responses go straight to TTS.
A manual text input fallback is always visible for situations where signing isn't practical.
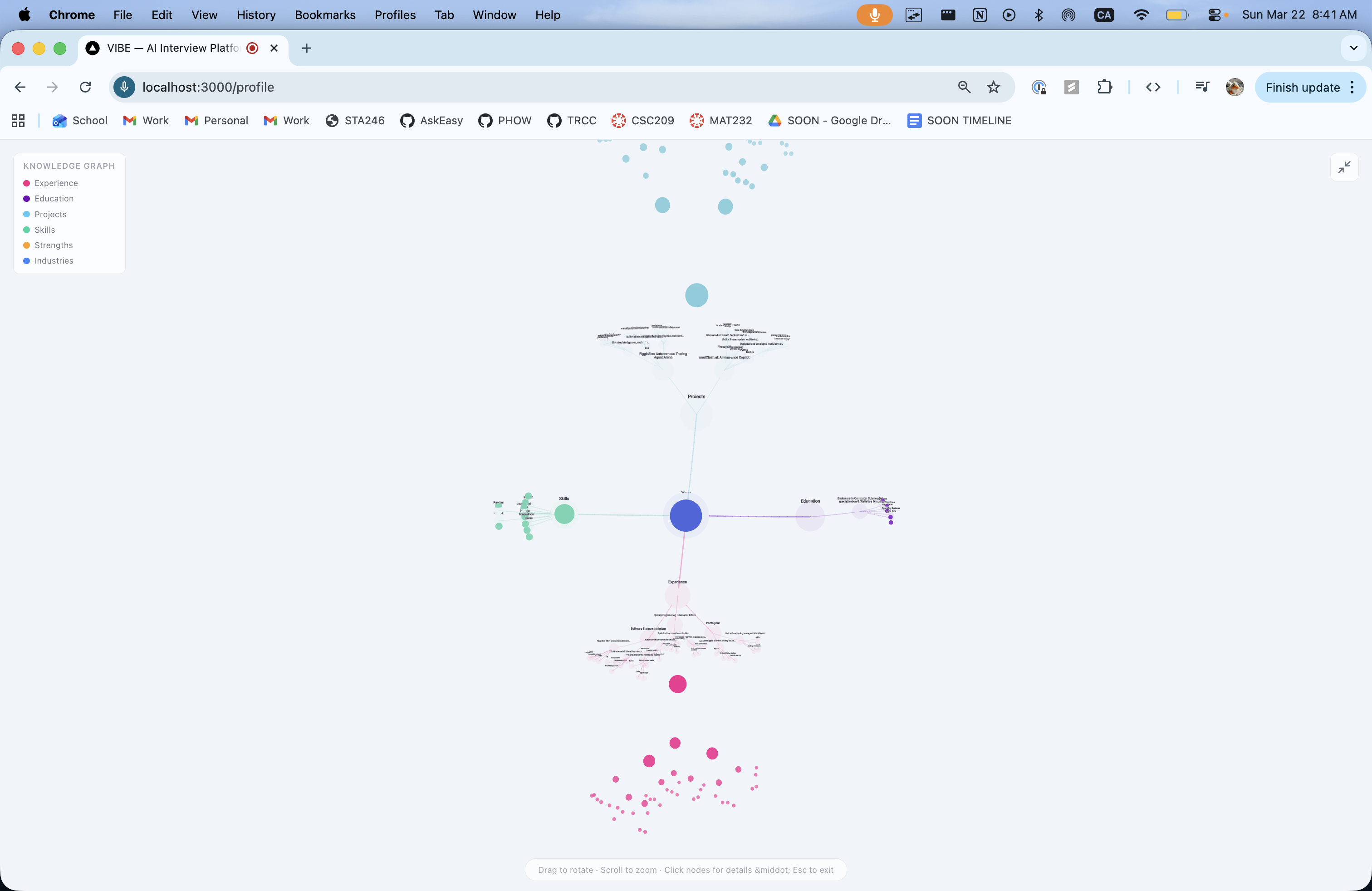
Profile & Knowledge Graph
Candidates upload their resume (PDF or text). GPT-4o-mini extracts structured data-skills, experiences, education, projects-and builds a 3D interactive knowledge graph rendered in Three.js. This five-tier hierarchical visualization (You → Sections → Items → Details → Keywords) isn't just eye candy: it powers personalized STAR feedback and live AI suggestions that reference the candidate's actual background.
 Replace with actual architecture diagram or demo video link
Replace with actual architecture diagram or demo video link
How We Built It
Architecture
We used a pnpm monorepo with two packages:
client/- Next.js 14 (App Router), Tailwind CSS, shadcn/ui, React Three Fiberserver/- Express + Socket.IO
All real-time communication runs over Socket.IO WebSockets. We chose Socket.IO over WebRTC because we don't need peer-to-peer media streaming-just event-driven message passing with automatic reconnection.
Hand Detection Pipeline (Client-Side Only)
A critical design decision: no video ever leaves the user's device.
useMediaPipeinitializes the MediaPipe HandLandmarker with GPU acceleration, throttled to ~3 fps to prevent CPU starvationuseFingerposeclassifies detected landmarks against 16 ASL letter gesture definitionsuseLetterStabilizerrequires 500ms of consistent detection before confirming a letter-this eliminates jitter-induced false positivestext-formatter.tsruns greedy longest-match segmentation against a 5,000-word dictionary (e.g.,DAILYCOLD→DAILY COLD)-entirely deterministic, no LLM involved- A confidence gate (< 60% average) skips autocorrect to prevent mangling uncertain input
We support 16 ASL letters: A, B, C, D, F, G, H, I, K, L, P, Q, V, W, X, Y. We excluded letters that are indistinguishable from static hand poses (E/S/T are all closed fists, J/Z require motion tracking, M/N look identical to A, R/U are the same as V, O matches C).
AI Services (Server-Side)
| Service | Provider | Purpose |
|---|---|---|
| Speech-to-Text | Deepgram (nova-2) | Live interview transcription, 48kHz opus streaming |
| Text-to-Speech | ElevenLabs (Rachel voice, flash v2.5) | Candidate's voice output |
| TTS Fallback | OpenAI TTS | Graceful degradation if ElevenLabs fails |
| LLM | OpenAI GPT-4o-mini | STAR evaluation, answer polish, puzzle generation, AI suggestions |
| Knowledge Graph | OpenAI GPT-4o-mini | Resume → structured data extraction |
| Translation | OpenAI GPT-4o-mini | Multi-language support (EN/ES/FR/ZH) |
| Auth + Database | Supabase | PostgreSQL, JWT auth, profile storage |
Performance optimization: STAR evaluation and answer polish run as Promise.all()-two parallel GPT-4o-mini requests cut feedback latency roughly in half.
Puzzle Builder
The drag-and-drop Puzzle Builder uses @dnd-kit for accessible drag interactions. The flow:
- AI generates 4 experience options from the candidate's knowledge graph
- Candidate picks one; AI generates story-fragment blocks tagged by STAR category
- Candidate drags blocks into S/T/A/R slots
- AI stitches blocks with filler words, displayed in purple to show what's generated vs. what's theirs
Frontend Components
40+ React components, built with shadcn/ui primitives (Button, Card, Badge, Progress, Tabs). The 3D knowledge graph uses React Three Fiber with orbit controls, billboarded labels, 200 ambient particles, and fullscreen mode.
Validation & Testing
- Tested ASL recognition accuracy across different lighting conditions and skin tones to verify MediaPipe's robustness
- Validated Deepgram STT latency under varying network conditions; implemented keep-alive pings every 8 seconds to prevent the ~10–12s idle timeout
- Verified the confidence-gating threshold (60%) by running sample texts at varying detection confidence levels to find the point where autocorrect starts degrading quality
- Tested ElevenLabs → OpenAI TTS fallback path to confirm seamless degradation
- End-to-end user flow testing across all modes (training, live, profile) with demo mode toggle for reliable demonstrations
Challenges We Faced
ASL Letter Ambiguity (Resolved)
Many ASL letters are nearly identical as static hand poses. E, S, and T are all variations of a closed fist; M and N look like A; R and U match V. We resolved this by limiting to 16 letters with unique curl+direction signatures rather than attempting unreliable classification of the full alphabet. This was a pragmatic tradeoff-fewer letters, but much higher accuracy.
Deepgram Connection Stability (Resolved)
Deepgram's WebSocket connections would silently drop after ~10–12 seconds of silence. We implemented an 8-second keep-alive ping cycle and a reconnection strategy with exponential backoff (up to 5 retries). We also added connection-generation tracking to invalidate stale callbacks from previous connections, preventing ghost transcripts from appearing.
Text Segmentation Without an LLM (Resolved)
Spelling out words letter-by-letter produces unsegmented strings like HABORTNEXTSTEPSNOW. Using an LLM for segmentation would add latency and unpredictability. We built a deterministic greedy longest-match algorithm against a 5,000-word dictionary. It's not perfect for every edge case, but it's instant and predictable-and the confidence gate prevents it from corrupting uncertain input.
Balancing Polish Latency vs. Responsiveness (Resolved)
Running every piece of text through GPT-4o-mini for polish added noticeable delay. We implemented a short-text fast path: anything under 20 characters skips the LLM and goes directly to TTS. This means quick responses ("Yes", "No", "Thank you") feel instant, while longer answers get the polish they benefit from.
3D Graph Performance (Resolved)
Rendering a 5-tier knowledge graph with potentially hundreds of nodes in Three.js required careful optimization. We used instanced rendering for particles, billboarded text sprites for labels, and lazy loading for deep nodes. Fullscreen mode toggles a dedicated render loop to prevent the graph from consuming resources when minimized.
Accomplishments & Learnings
What We're Proud Of
Zero-server vision pipeline: All hand detection and text formatting runs client-side. No video is ever transmitted. This is both a privacy guarantee and a performance win-there's no network latency in the detection loop.
The Puzzle Builder: This is our most original contribution. Instead of asking candidates to write STAR answers from scratch (intimidating) or giving them a template (generic), we let them build answers from their own experiences using drag-and-drop. The purple filler words make the AI's contribution transparent.
Graceful degradation everywhere: ElevenLabs fails → OpenAI TTS. Deepgram drops → automatic reconnection. Low confidence → skip autocorrect. Short text → skip polish. The system never hard-fails; it always falls back to something that works.
Real-time three-panel live mode: Having speech-to-text, sign-to-speech, and AI suggestions all updating simultaneously via WebSockets, while maintaining responsive UI, was a significant engineering challenge.
What We Learned
Accessibility is a design constraint, not a feature: Building for deaf users forced better architecture decisions-client-side processing for privacy, visual feedback for every state change, always-visible text fallback. These patterns benefit all users.
Confidence thresholds matter more than accuracy: A 95%-accurate gesture detector that's wrong 5% of the time is worse than an 80%-accurate one that knows when it's uncertain. The confidence gate and stability timer transformed a shaky detector into a reliable one.
Socket.IO's reconnection model is underrated: We initially considered WebRTC for the live mode, but Socket.IO's built-in reconnection, event namespacing, and room management saved us days of infrastructure work.
What's Next
Short-Term Improvements (1–2 Weeks)
Motion-based letter detection: Adding J and Z support using temporal landmark tracking (comparing hand positions across frames rather than single-frame classification). This would expand our alphabet from 16 to 18 letters.
Word-level sign detection: Moving beyond letter-by-letter spelling to recognize common ASL words as complete gestures. Starting with the 50 most common interview words ("experience", "team", "problem", etc.) would dramatically speed up communication.
Session recording & playback: Saving full interview sessions (transcripts, responses, timing data) so candidates can review their performance and track improvement over time.
Real authentication flow: Replacing the demo user with full Supabase email verification, password reset, and optional OAuth (Google, GitHub).
Long-Term Scalability
On-device TTS model: Running a lightweight TTS model in the browser (via ONNX/WebAssembly) would eliminate the ElevenLabs API dependency, reduce latency, and allow offline practice. This is feasible-models like Piper TTS already run in-browser.
Employer-side integration: Providing interviewers with a companion interface that shows the candidate's captions and provides awareness cues (e.g., "candidate is formulating a response"). This transforms VIBE from a candidate tool into a bilateral communication platform.
Mobile support: Adapting the MediaPipe pipeline for mobile browsers (already supported by MediaPipe) and optimizing the three-panel layout for smaller screens. This would dramatically expand reach, especially in regions where mobile is the primary computing device.
Language expansion: The architecture already supports multi-language translation (EN/ES/FR/ZH). Extending to additional sign languages (BSL, LSF, JSL) would require new gesture definition sets but no architectural changes-the pipeline is language-agnostic by design.
Enterprise deployment: Offering VIBE as a white-label solution for HR platforms and job boards. The WebSocket architecture scales horizontally, and Supabase's row-level security supports multi-tenant isolation out of the box.
Built With
- deepgram
- elevenlabs
- express.js
- mediapipe
- nextjs
- openai
- socket.io




Log in or sign up for Devpost to join the conversation.