-
Main Menu
-
Main Menu
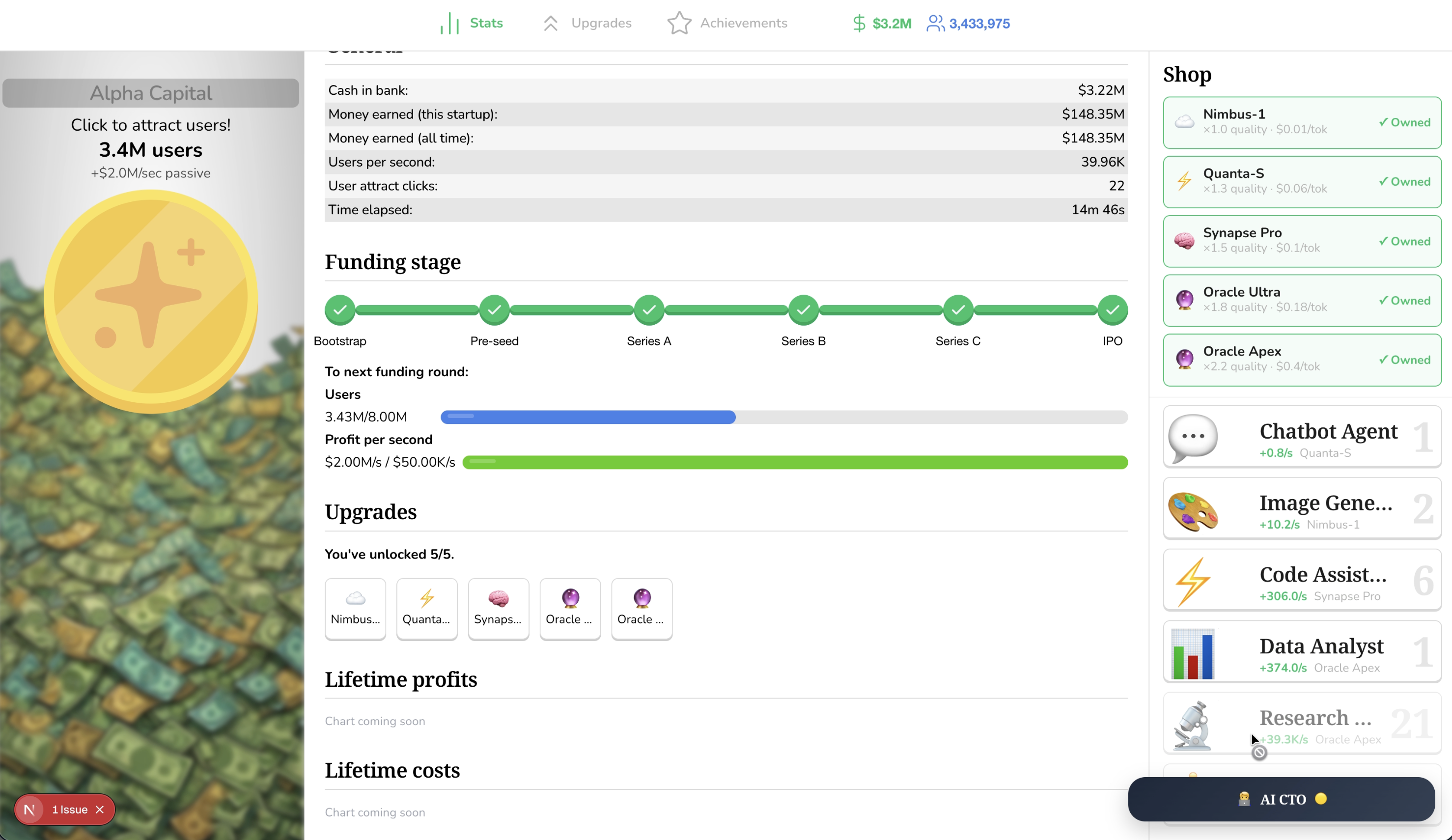
Inspiration 💡
We wanted to turn the chaos of building an AI startup into something playful, educational, and a little brutal. AI Agent Empire takes the
dopamine loop of idle games like Cookie Clicker and Adventure Capitalist and swaps out factories and grandmas for AI agents, prompt
engineering, token economics, and funding rounds.
It's a game, but it's also a way to explore real startup tradeoffs: growth vs. efficiency, scaling vs. profitability, and cheap models with tight prompts vs. expensive models with bloated ones.
What it does 🚀
AI Agent Empire is an idle startup simulator where players grow an AI company from nothing to IPO. You hire six types of specialized AI
agents — Chatbot, Image Generator, Code Assistant, Data Analyst, Research Agent, and ML Orchestrator — choose LLM models for each, and
write prompts that directly affect their output quality.
As the game runs, agents generate users per second, users generate revenue, and operating costs eat into your margins. Bad prompts mean low service quality, user churn, and stalled growth. Good prompts mean efficient agents, healthy profit, and rapid scaling.
Players advance through seven funding rounds (Bootstrapped → Pre-Seed → Seed → Series A → B → C → IPO), each gated by user count, total
revenue, and net profit requirements. An AI CTO advisor analyzes your full company state and gives prioritized strategic advice plus real
business lessons. Hit IPO, earn Reputation, buy permanent upgrades, and Pivot for another run — faster and smarter each time. 35+
achievements track progress across earnings, users, prompt quality, profitability, and more.
How we built it 🛠️
We built the game with Next.js, React, TypeScript, and Tailwind CSS. The core gameplay runs through client-side state with continuous
interval-based loops (100ms ticks) handling user generation, revenue calculation, churn, operating costs, model quality multipliers,
funding stage progression, and prestige mechanics.
For the AI features, we built server-side API routes for prompt evaluation and the AI CTO advisor. Prompt evaluation is agent-type-aware —
TerpAI scores a chatbot prompt differently than a code assistant prompt, accessed through Playwright-driven server-side web automation so
credentials never touch the client. The CTO route takes a full snapshot of company state and returns structured JSON with health
assessment, prioritized advice, and a contextual business lesson. Results are cached on agent objects to avoid redundant calls.
Challenges we ran into ⚠️
One of the hardest parts was making prompt quality mechanically meaningful without feeling arbitrary. We tied it to user generation rate,
token efficiency, and a service quality system where the weighted average of all agent qualities drives user churn — so one bad agent drags
the whole company down.
Making LLM responses reliable enough for gameplay was another challenge: enforcing structured JSON, validating outputs, caching
evaluations, handling failures gracefully, and making the scoring agent-type-aware so a good chatbot prompt and a good research agent
prompt require genuinely different things.
Balancing idle game pacing with economic depth was the third major challenge. Idle games need to feel fast and rewarding, but the financial systems need enough friction that player decisions around prompt quality, model selection, and agent composition actually matter.
Accomplishments that we're proud of 🏆
We're proud that prompt writing has real, visible consequences — you can watch your user generation rate triple after improving a prompt
from 22/100 to 81/100. Model choice changes the economics in ways you feel immediately. The AI CTO makes concepts like unit economics and
token efficiency interactive instead of abstract.
We're also proud of the completeness: seven funding rounds, six agent types, five model tiers, 35+ achievements across ten categories, a
full prestige loop with eight permanent upgrades, real-time statistics with live charts, achievement toasts, and an IPO result card. It
feels like a real product, not a prototype with an AI wrapper.
What we learned 📚
We learned that AI works best when it supports the core gameplay loop instead of replacing it. The most interesting design work wasn't
"adding AI" — it was building systems where prompt quality, token cost, service quality, user churn, and business outcomes all reinforce
each other into a single coherent feedback loop.
We also learned how much work separates an LLM demo from a usable feature — validation, latency management, caching, fallback logic,
agent-type-aware evaluation, and making the AI output feel like gameplay feedback rather than a raw API response.
What's next for AI Agent Empire 🔮
Next, we want to expand the meta-progression system with deeper upgrade trees, add more agent archetypes and dynamic events, and introduce richer financial mechanics like investor negotiations and market conditions that shift between runs.
Longer term, we'd love to add competitive leaderboards (fastest IPO, highest valuation), shareable result cards, research trees that unlock new agent capabilities, agent orchestration mechanics where agents interact with each other, and more narrative flavor around building — and surviving — an AI startup.
Built With
- claudecode
- codex
- figma
- next.js
- playwright
- react
- tailwind
- terpai
- typescript










Log in or sign up for Devpost to join the conversation.