-
-
Visualization
-
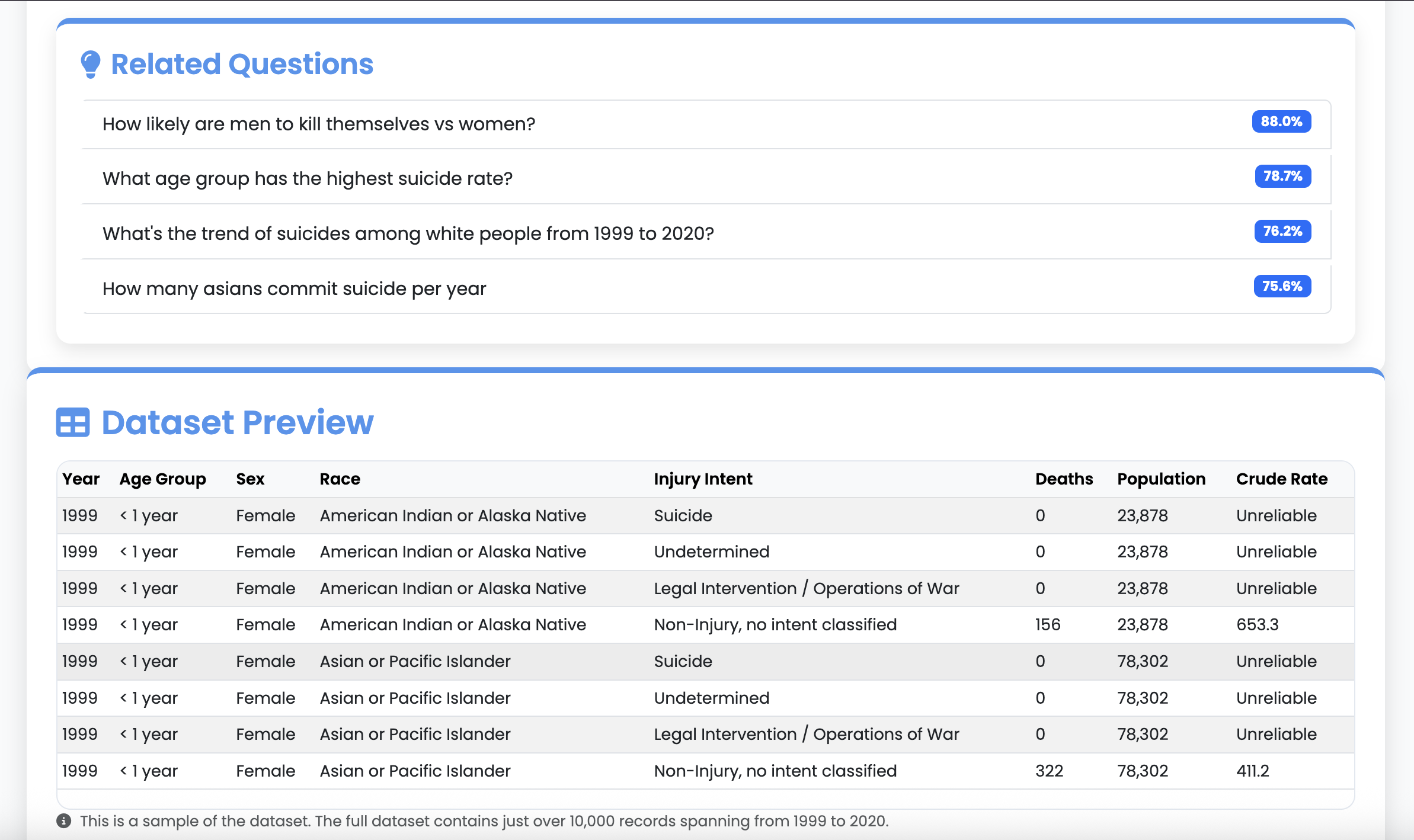
Vector-Based Relevant Searches with Scoring
-
Homepage
-
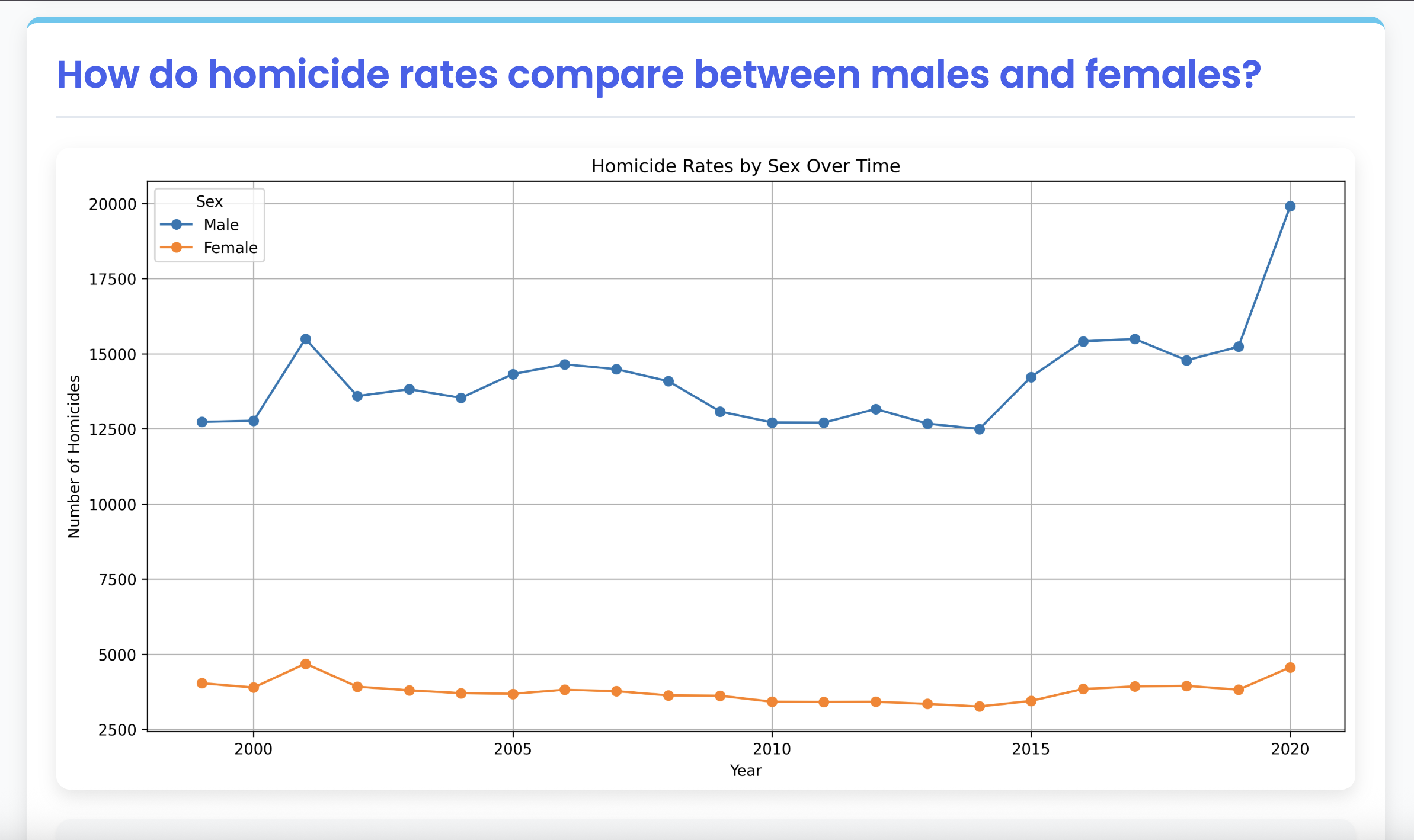
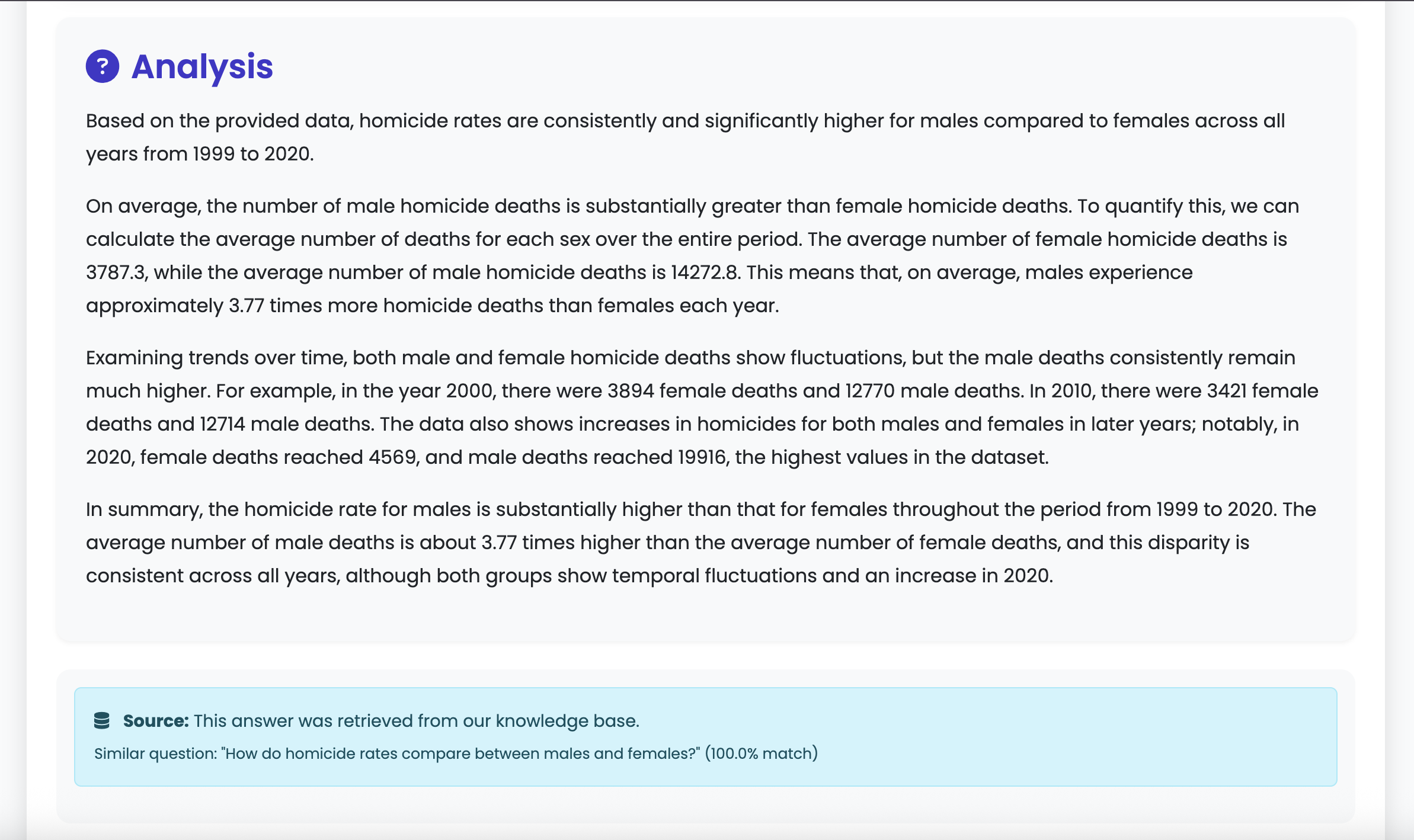
Analysis
Inspiration
As a data geek, I’ve always been fascinated by the power of data. If the data is publicly available, even better! Making data publicly available is important, but even if anyone could access it, that doesn't necessarily mean that they could or would want to go through the process of doing so. So, what if they could just ask a question and get their answer without the extra steps? No data tables, no coding, just knowledge!
What it does
Vextra is a smart insight engine. It bridges natural language questions with real statistics, turning curiosity into clear, visual answers. After providing visualizations and an in-depth analysis, Vextra will suggest follow-up prompts that may interest the user based on the question they originally asked.
Key Features
Ask a Question:
Users can ask questions like "What were the top causes of death for Black females in 2010?" or "How did injury related deaths change over time?"
Get an Answer:
If a similar question (≥99% vector similarity) has already been asked, Vextra will return...
- A pre-generated visualization (PNG, base64 encoded)
- A detailed, human-readable analysis
Otherwise...
- Vextra prompts Gemini 2.0 Flash to generate a visualization in Python
- The chart is converted into a base64 PNG and stored in MongoDB Atlas
- The data behind the visualization is extracted and stored temporarily as a CSV file
- Gemini uses that data to write an accurate analysis in a human readable format
- Using Vertex AI, we then create an embedding and store the findings in MongoDB Atlas for future retrieval
- Results are sent back to the user along with smart suggestions, which are other searches related to the users original question. Suggestions must have a 75% or higher similarity.
How it was built
Vextra combines vector search, GenAI, and real-time data visualization into a cohesive insight engine.
Data Source
Vextra uses the CDC Wonder Underlying Cause of Death dataset (1999–2020), a rich public dataset with mortality statistics categorized by Year, Age Group, Sex, Race, and Injury Intent as Cause of Death. The data is hosted as tab delimited .txt files on GitHub, which we accessed via raw URLs, which in turn helped solve a major hosting challenge.
AI + Language Model
Vextra uses Google Vertex AI for...
- Text embeddings (text-embedding-004) which converts user questions into vector space for similarity searches
- Generative AI (Gemini 2.0 Flash) which generates Python code to create visualizations (charts), base64 encoded PNGs from those charts, and analytical summaries of the plotted data. I found that Gemini performed best when first asked to visualize, then to analyze the data derived from the visualization. This two-step approach greatly reduced hallucinations.
Vector Search + Storage
Vextra uses MongoDB Atlas as both the primary database and the vector store. By leveraging MongoDB’s native vector search, it was possible to store user questions as embeddings and retrieve similar queries based on semantic similarity. Visualizations generated by the model were saved as base64-encoded PNG strings, and insights were stored as clean, structured text. Along with the response, Vextra also links related searches using a similarity threshold of 75% or higher, allowing it to surface relevant prompts alongside each result. MongoDB’s flexible schema made it easy to manage this mixed data while doubling as a powerful semantic search engine.
Hosting
Vextra uses GCP cloud run with smart autoscaling to accommodate any kind of traffic. This was a necessary upgrade from Render (free tier) as scaling is snappy and you don't have to wait for it to spin up, even if there hasn't been any recent traffic! We did keep other parts of our architecture the same - no local file storage, no bundled datasets, and the charts are still kept in the database.
Challenges
AI Misinterpreting the Raw Data
Problem: Early on, it was discovered that GenAI models like Gemini would often hallucinate or misinterpret results when asked to analyze the raw CDC data directly. The dataset includes many categorical and structural nuances that weren’t reliably understood by the model, leading to inaccurate or misleading summaries. Solution: Flipping the workflow! First prompting the model to generate a visualization, then exporting the plotted data as a temporary CSV file. Once the data was in a simplified, numeric format, the model was far more accurate in generating meaningful insights.
Vector Matching Was Too Strict
Problem: The prompt design requires a 99%+ similarity score to return a cached result from vector search. While this reduced duplication, it undermined the value of the vector system. Solution: Adding "Related Searches" panel to show results with 75%+ similarity compared to the original question, allowing Vextra to showcase the power of semantic matching and suggest useful adjacent queries that might interest the user, even if they didn’t match exactly.
No Disk Access on Render Free Tier
Problem: Render’s free hosting plan comes with no persistent disk storage, which meant we couldn’t locally store the raw dataset or generated images. Solution: Pulling the data files (tab delimited TXT files) directly from GitHub raw content on demand. Instead of storing charts as files, we switched from SVG to PNG images encoded in base64, allowing us to save them directly in MongoDB alongside the query and analysis. This made it possible to store our visualizations without extra libraries or tools, and has the added benefit of working seamlessly between local and production environments. We've now upgraded to GCP for hosting, as mentioned above.
Accomplishments
Getting everything to work together felt like assembling a puzzle where each piece had different constraints. The fact that Vextra can now handle a natural language question, intelligently determine if it's been answered before, and generate both a visualization and a meaningful insight if not, feels like a big win! One major accomplishment was refining the prompt strategy so the AI consistently outputs accurate and relevant information. That change alone transformed Vextra from a neat demo into something trustworthy. Another point of pride is how little Vextra relies on traditional file systems. Despite hurdles with hosting on a free tier, the architecture remains lightweight and portable.
What I learned
I've learned that GenAI is very good at certain things and really bad at others, especially when interpreting raw statistical data. It needs structure. And sometimes, it's not about asking for an answer, but knowing how to ask. While there are models with niche capabilities that may have handled the task better, it was important to me to use a generalist base model and make the magic happen. I also gained a deeper appreciation for semantic search. Matching meaning rather than keywords opens the door to an entirely different class of user experience, one where the system feels more intelligent because it understands the intent behind the question. Lastly, I learned that constraints, like no disk access, aren’t always blockers, sometimes, they’re just design challenges! Creative solutions like in-memory processing and base64 encoding helped me build something functional even in a restricted environment.
What's next
Ideally, this weekend project could turn into something robust and universally useful. Here is my plan...
- A full frontend experience with a search bar, auto-suggestions, and chart previews
- Support for additional datasets, including more open resources in the health sector or even environmental or data related to education, the options are endless!
- A feedback loop that lets users rate how helpful a result was, so the system can improve over time
- Scheduled or manually ran deletions that could weed out improper or out-of-date responses to give answers that are always relevant and factually correct as the model improves.
- Giving users the option to upload their own data for analysis in a private or public setting
- Maybe even some sort of social aspect where people can share their results!
Vextra is just getting started, but the goal remains the same; to make open data truly accessible through smart, visual, and conversational insights!
Updates
- Vextra is now hosted on GCP instead of Render! (06/13/2025)

Log in or sign up for Devpost to join the conversation.