-
-

Slide 1: Intro
-

Slide 2: Why?
-
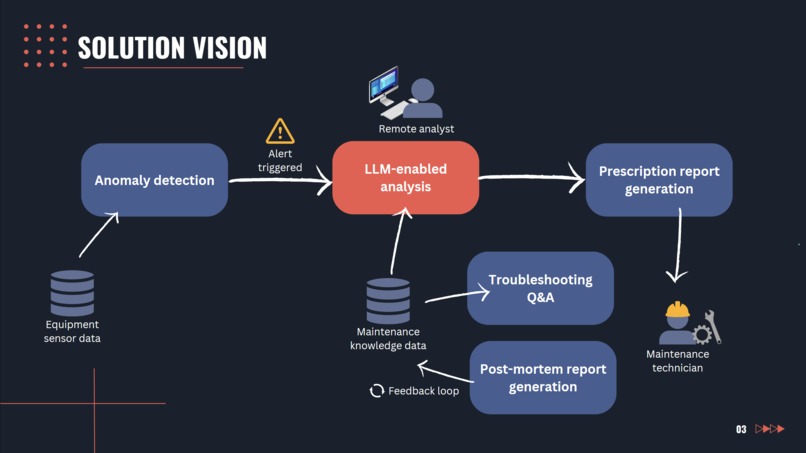
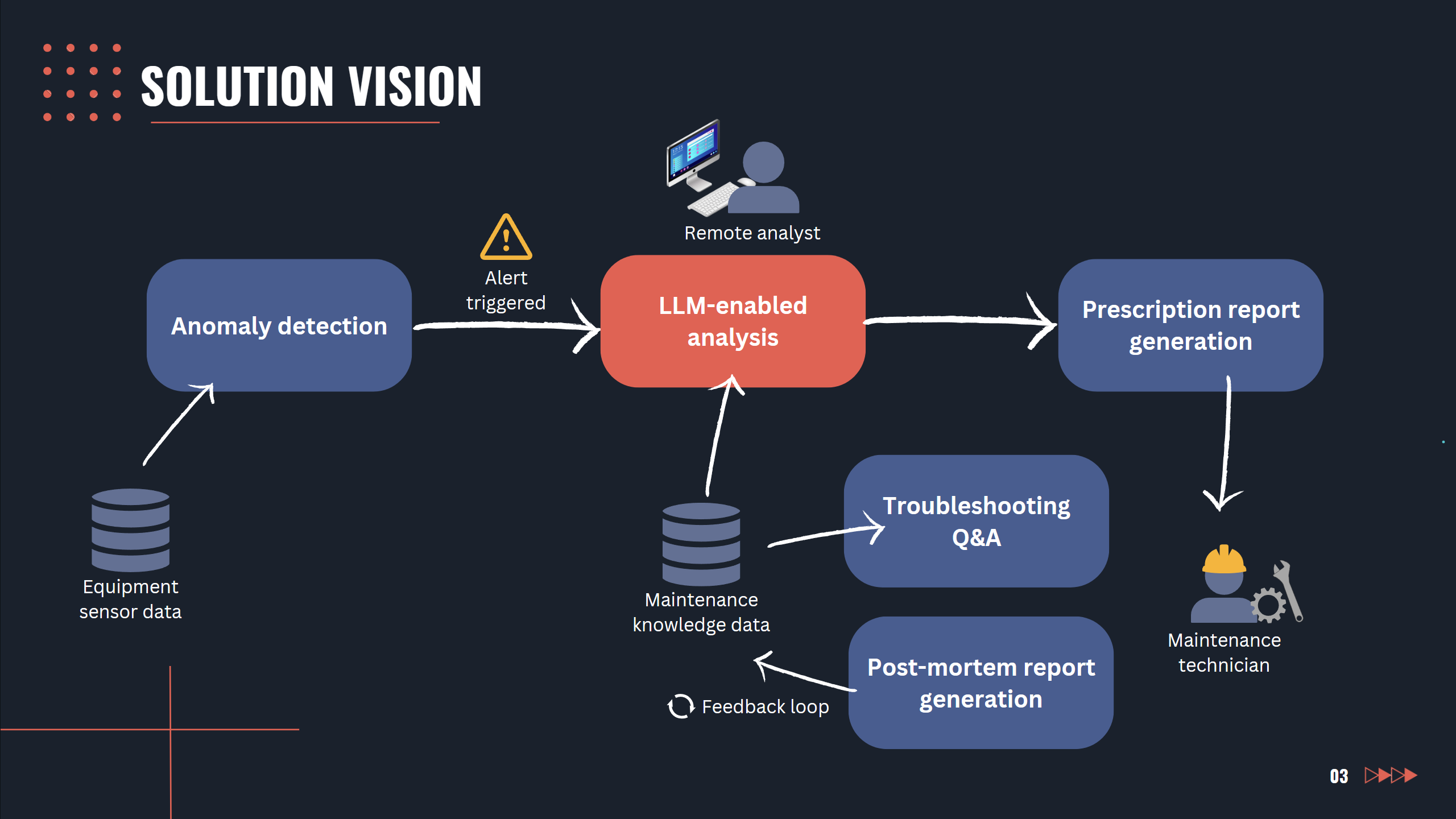
Slide 3: Solution vision
-

Slide 4: Problem scope
-

Slide 5: Data
-
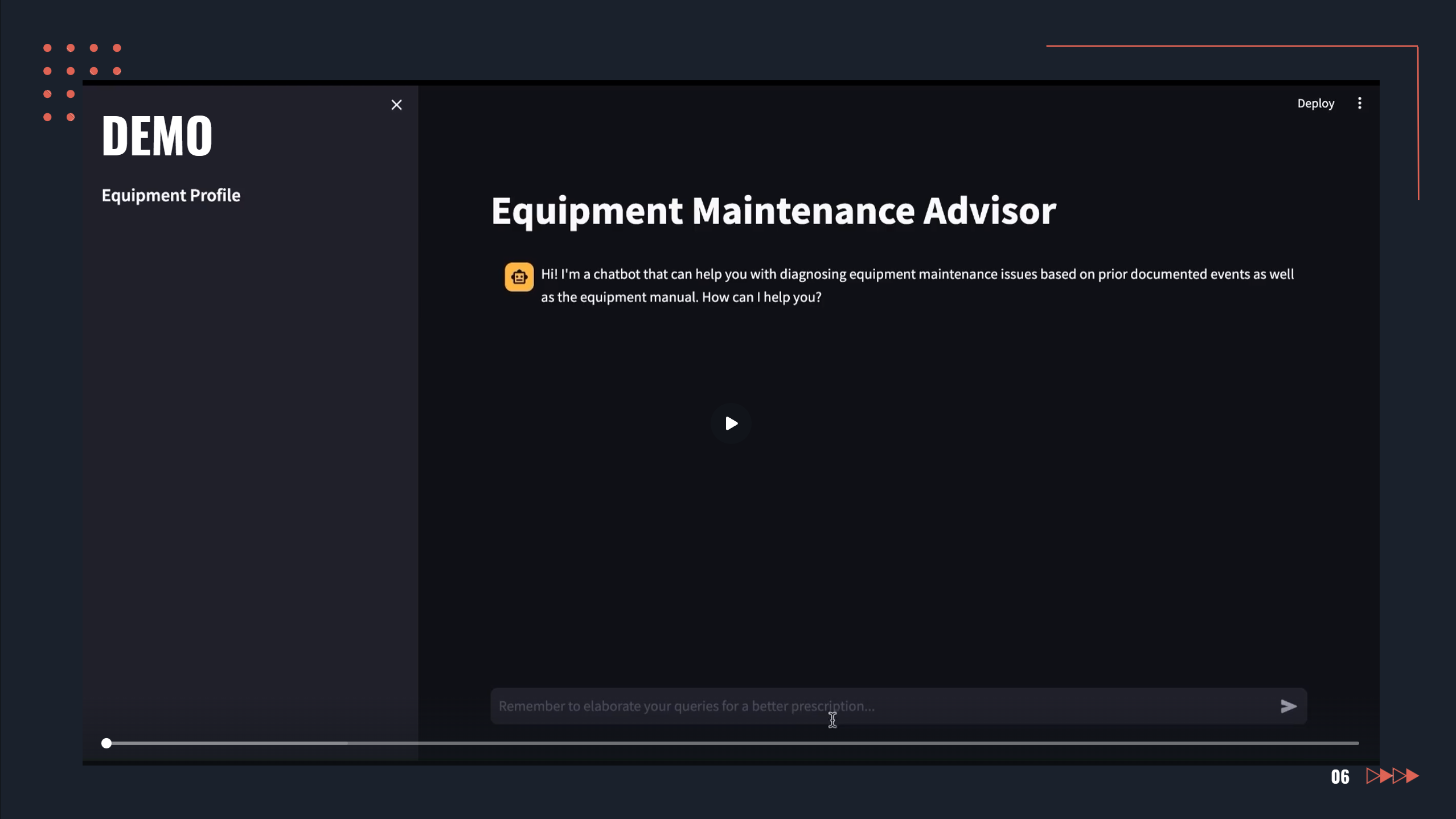
Slide 6: Demo
-
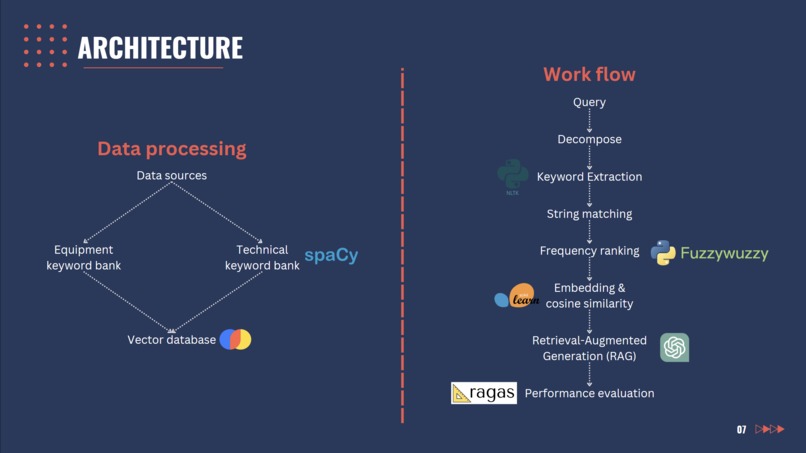
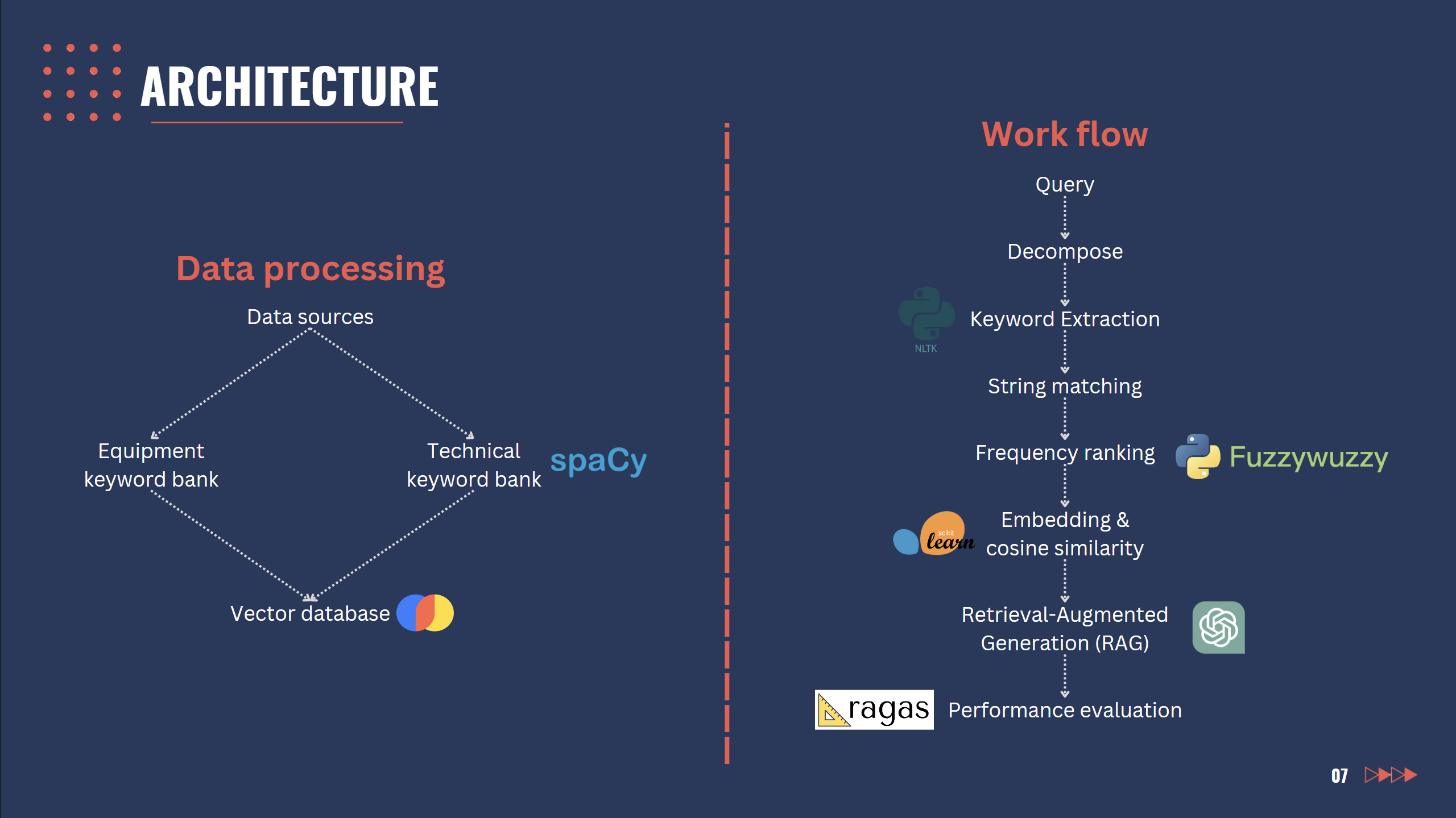
Slide 7: Architecture
-

Slide 8: Lessons
-

Slide 9: Team
-
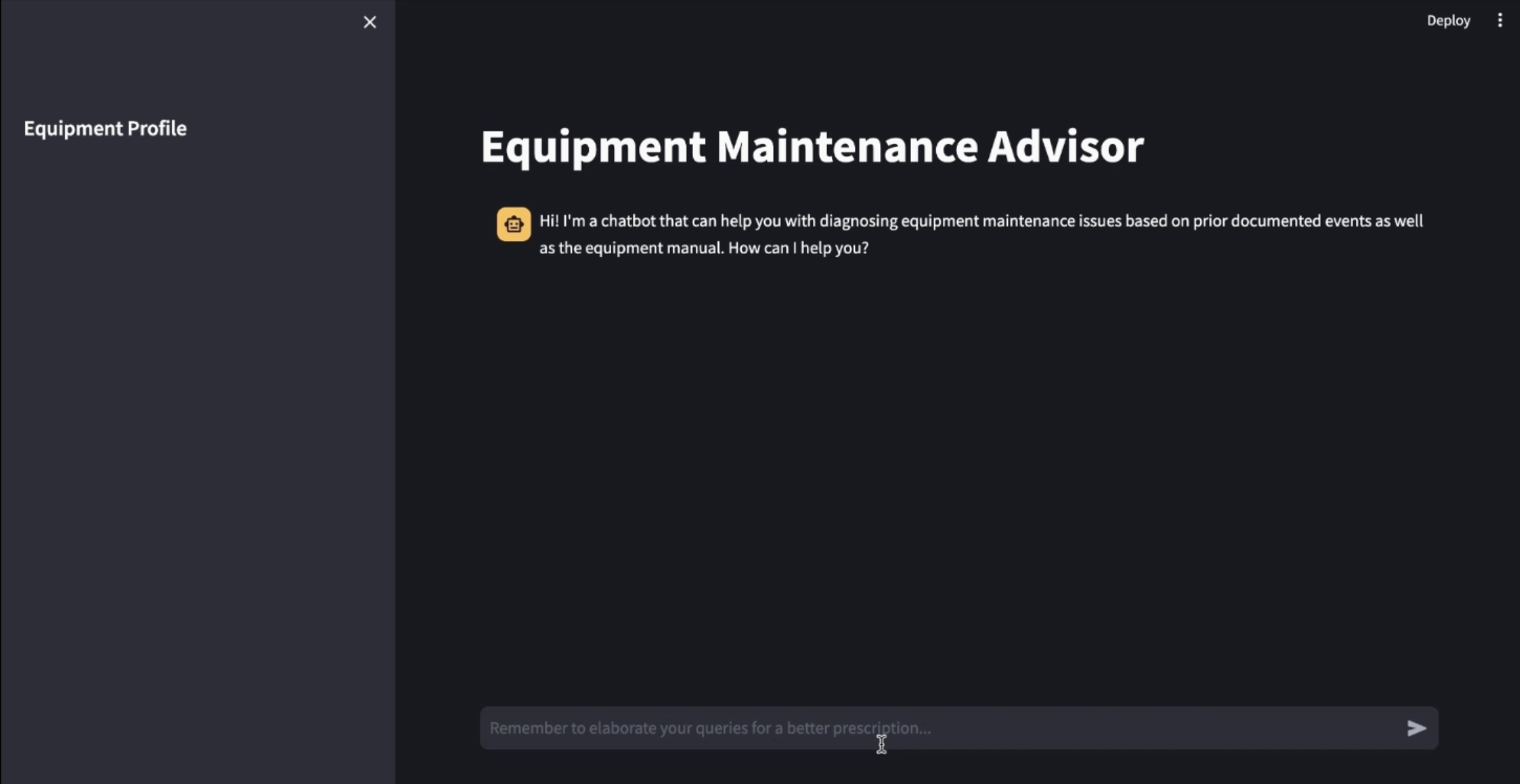
Starting layout upon entering the application
-
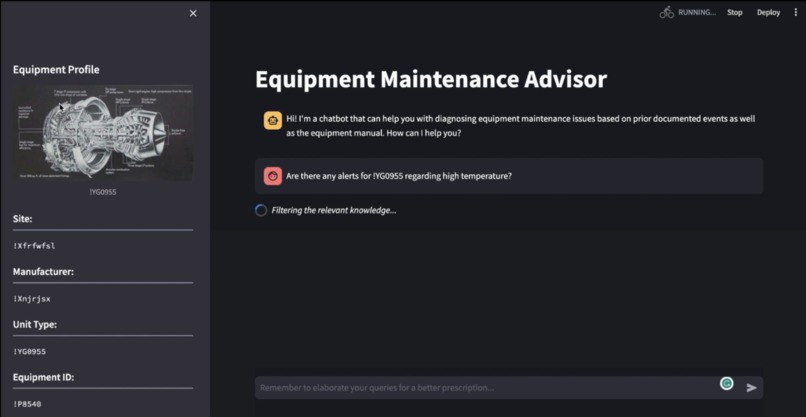
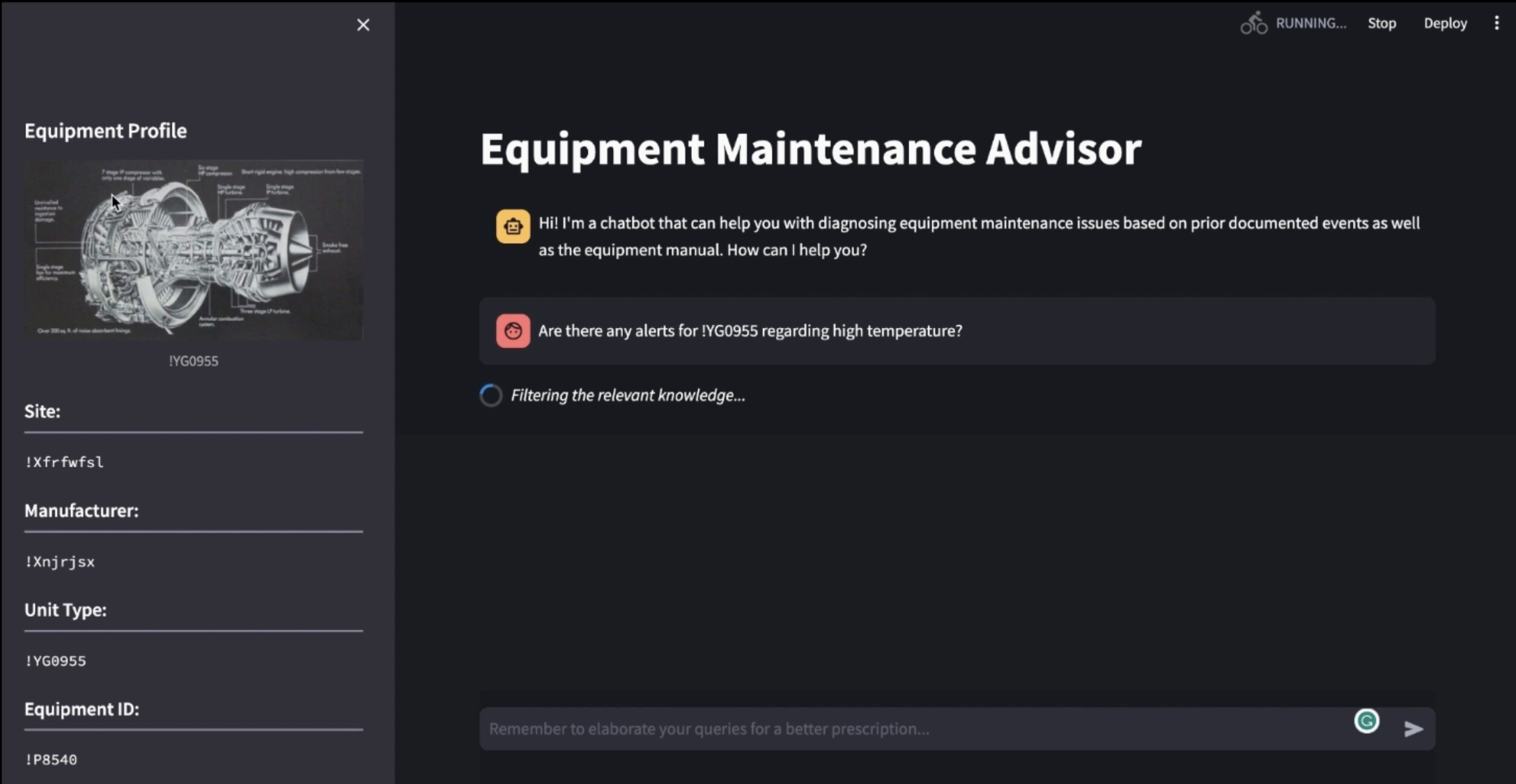
Loading message "Filtering the relevant knowledge" while application is processing query
-
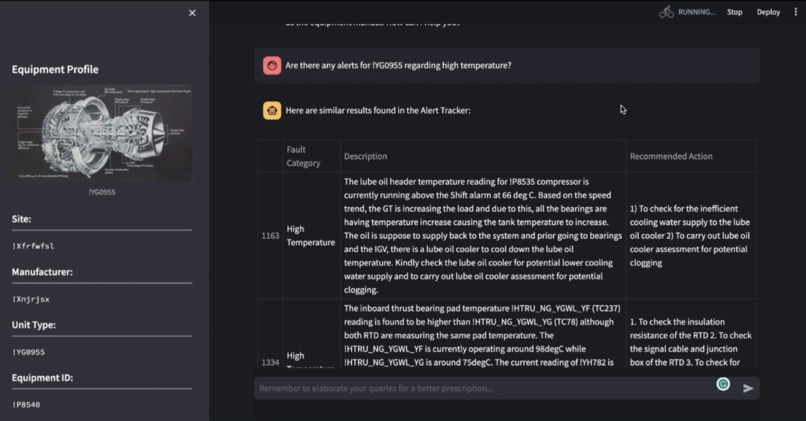
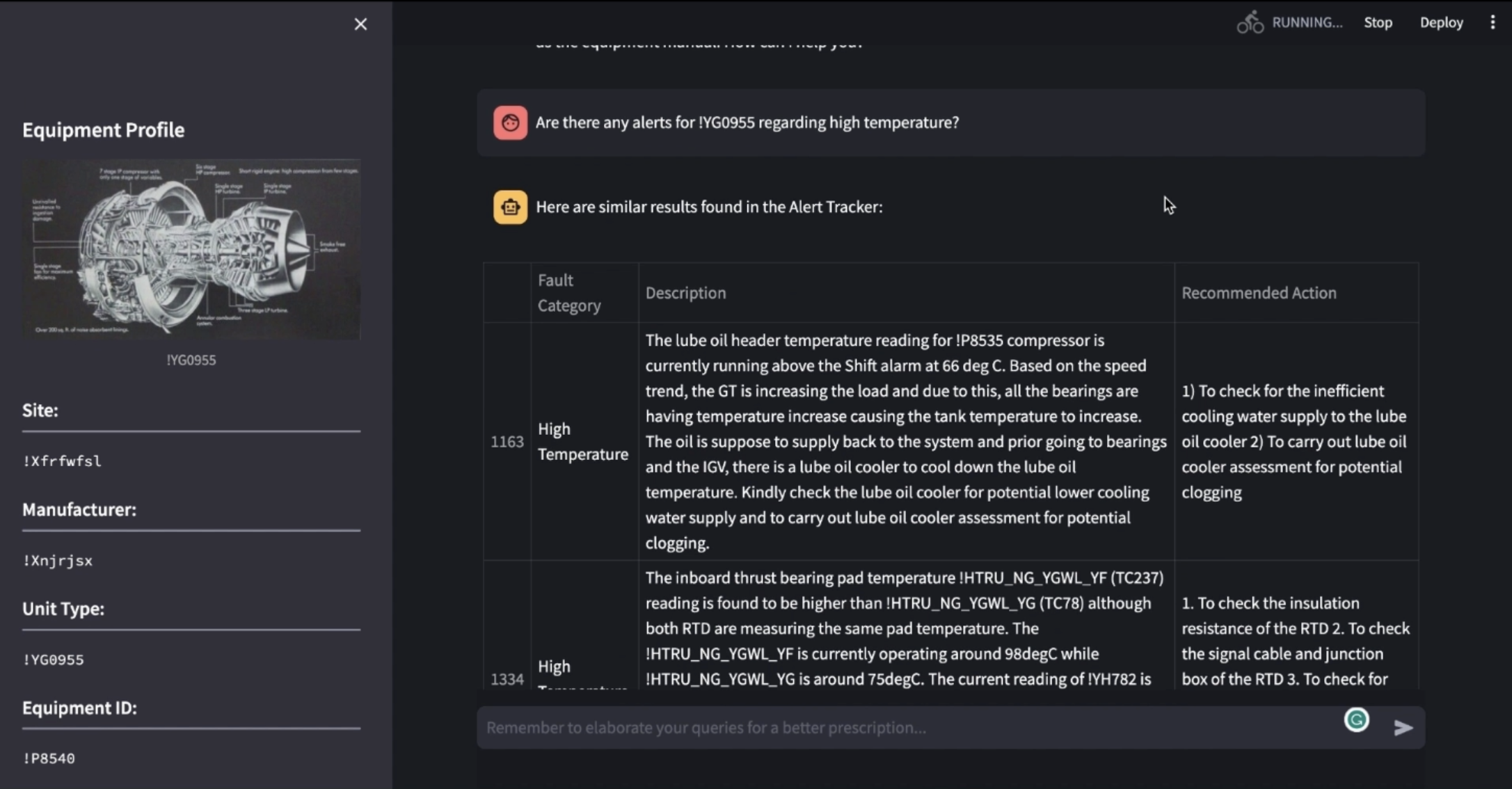
Chat output as table for retrieving past records
-
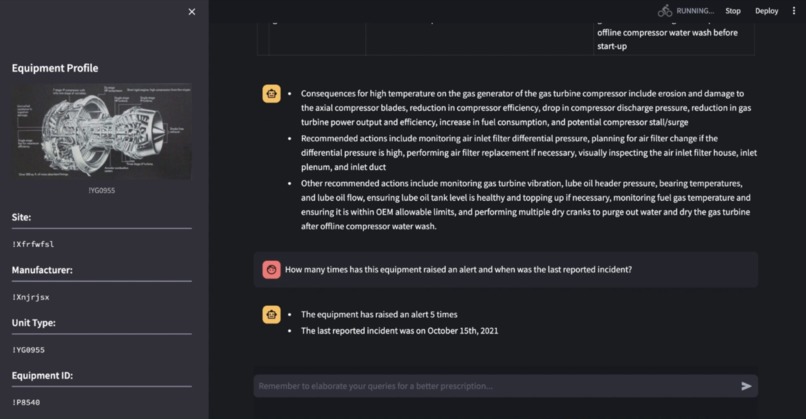
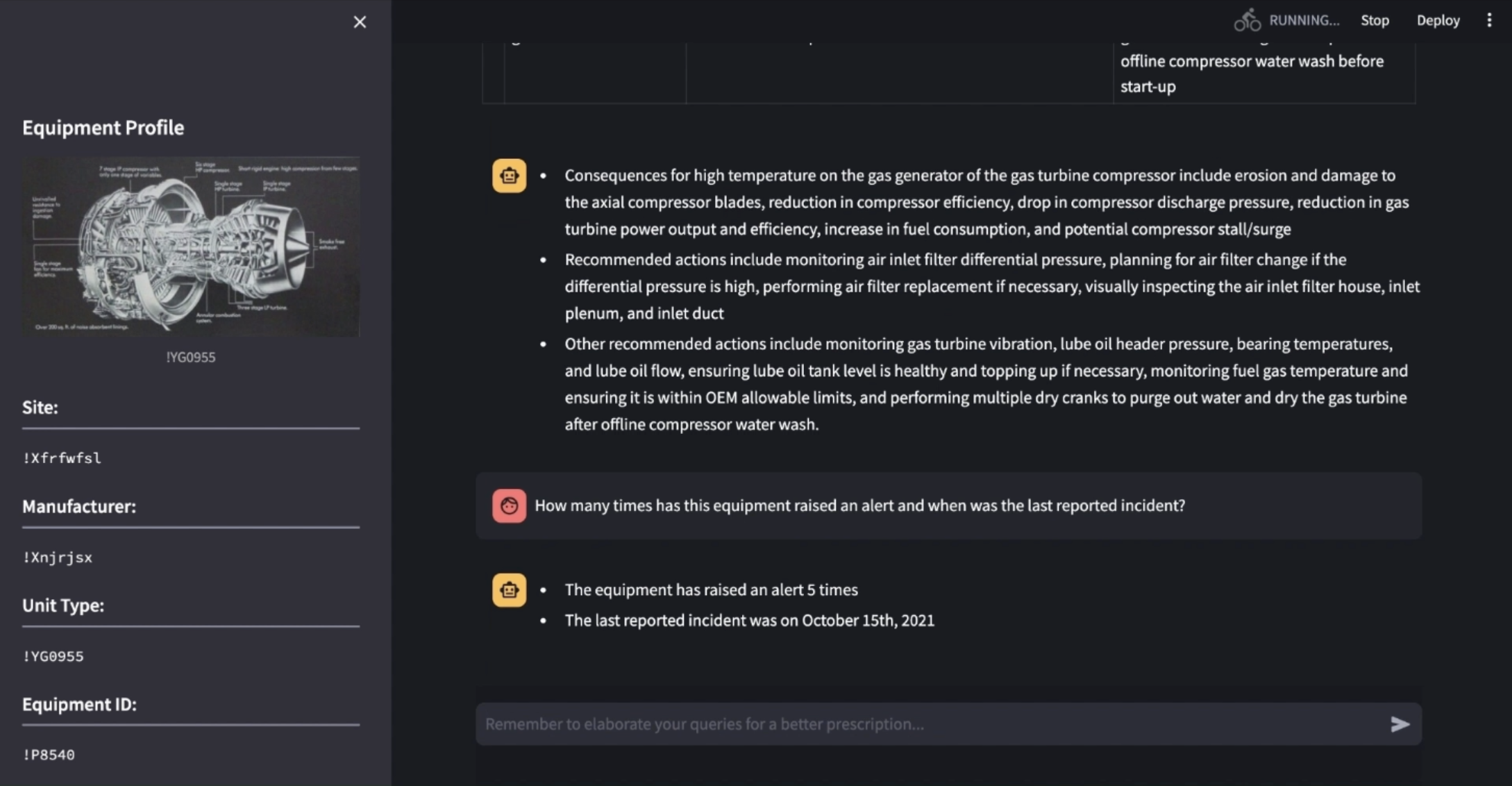
Chat output as paragraphs for summaries and answering reasoning questions






Inspiration
We were initially inspired to work on Equipment Maintenance Advisor when our client spoke to us regarding a fire hazard which occurred at their plant. This accident spurred a need for improved and more proactive maintenance practices. We then realised that there was value in leveraging LLMs when performing their equipment failure diagnosis and prescription tasks due to the cumbersome and time consuming amounts of text that needs to be parsed through in order to perform the analysis.
What it does
Acts as a knowledge management assistant to assist remote analysts in diagnosing equipment failures by retrieving information from several reference documents and historical datasets through a natural-language chat interface.
How we built it
We built it by ingesting all their existing references into a vector database which then allows us to perform Retrieval-Augmented Generation (RAG) using OpenAI's API. Given the engineering nature of our datasets, several technical keyword banks were also created using spaCy in order for us to improve the accuracy of information retrieved by reducing noise from irrelevant words.
Whenever the user asks a query, we decompose their question and perform Rapid Automatic Keyword Extraction (RAKE) to identify the intent of the query. We then perform string matching or cosine similarity to be able to retrieve the right information.
For the user interface, we decided to keep things simple and develop on the Streamlit framework using an existing template as it sped up our development time yet allowed us to have a clean looking interface.
Lastly, we regularly evaluate the performance of our solution using the RAGAS framework to guide development decisions.
Challenges we ran into and what we learned
Data cleaning was a major challenge as many of the datasets we used were collected manually and intended to be used by human analysts. It required that we understood the technical subject matter and work closely with our users to be able to clean mistagged information and ensure consistent categorisation and spelling. Along the way, we learned that leveraging LLMs to perform data cleaning allowed us to automate several cleaning tasks.
Another challenge we face was in determining retrieval strategies. As this was our first time working with both structured and unstructured datasets in a single LLM application, we initially struggled to determine the right balance between using LLMs and writing hard-coded logic. We learned that for better precision and control, it made more sense to hard-code most parts of the app, only utilising LLMs when there was a need to handle natural language or perform reasoning on the user query.
Accomplishments that we're proud of
We are most proud of how quickly we were able to turn around this project. In a span of less than two weeks, we were able to output our first prototype. Then, following the deadline extension, we were able to be more ambitious with our scope to include additional features and work with a larger dataset.
We are also very satisfied with how closely we were able to work with our client and the time spent truly understanding their user requirements and datasets via interviews and collaborations.
What's next for Equipment Maintenance Advisor
Our next step will be to incorporate more datasets, include master agents that are able to perform various distinct tasks according to the user's expectations and improve the tool's ability to reason and decompose questions better for more accurate retrieval. In addition, we expect to move the UI away from Streamlit and continue working with our client to build more modules for Equipment Maintenance Advisor that address other parts of their work process.
Built With
- chromadb
- fuzz
- langchain
- nltk
- openai
- python
- ragas
- scikit-learn
- spacy
- streamlit



Log in or sign up for Devpost to join the conversation.