-
-

Veritas Homepage
-
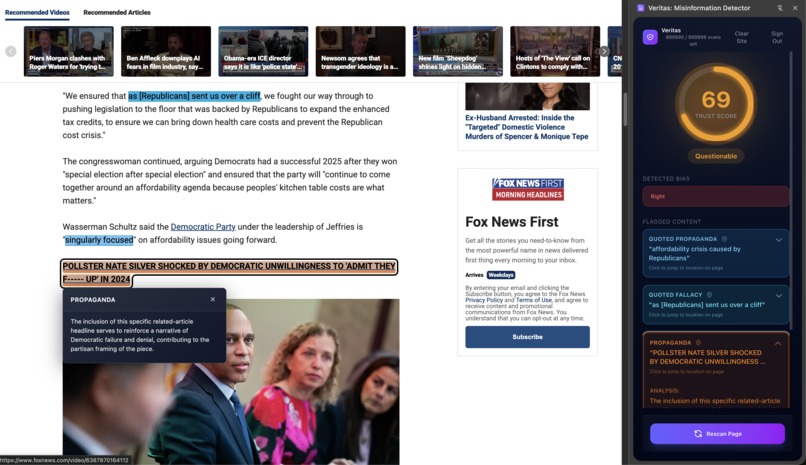
Analyze propaganda and misinformation for bias. The trust score can indicate an article’s reliability.
-
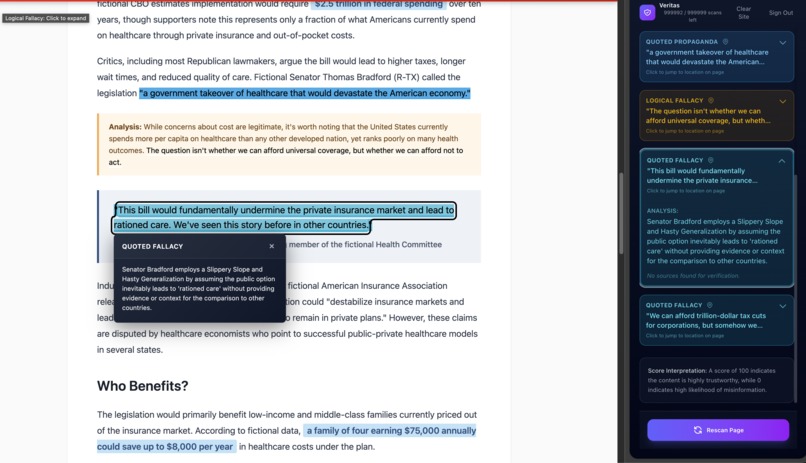
Get an in-depth look into authors' rhetoric.
-
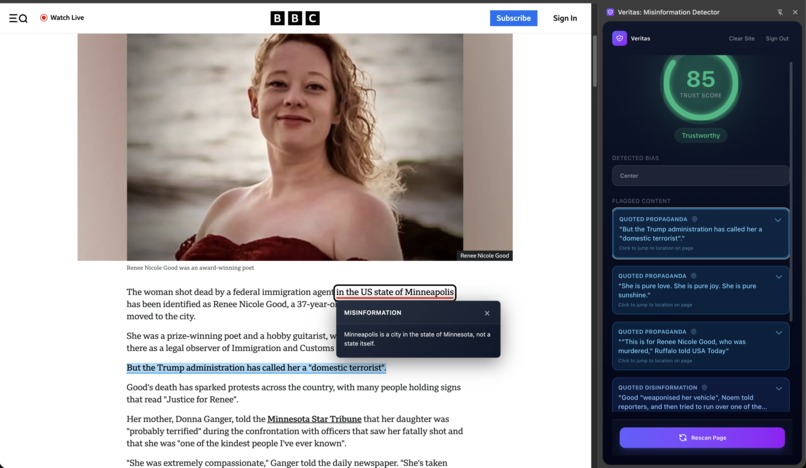
Identify mistakes in text that aren't found by spellcheck devices.
-
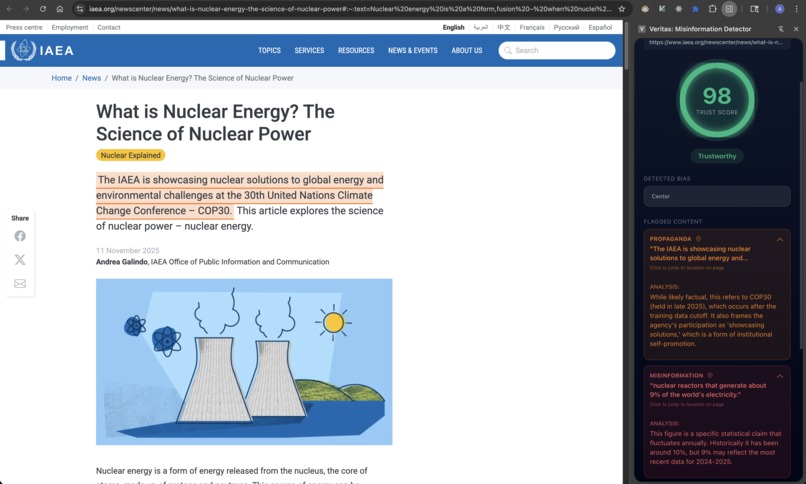
Veritas works along politics, technology, health, and more.
-
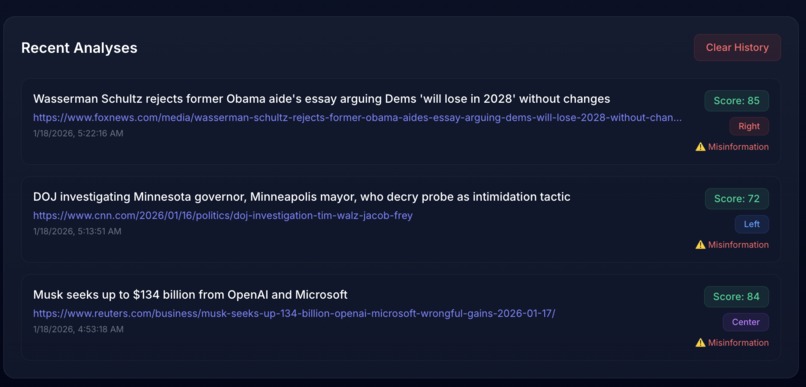
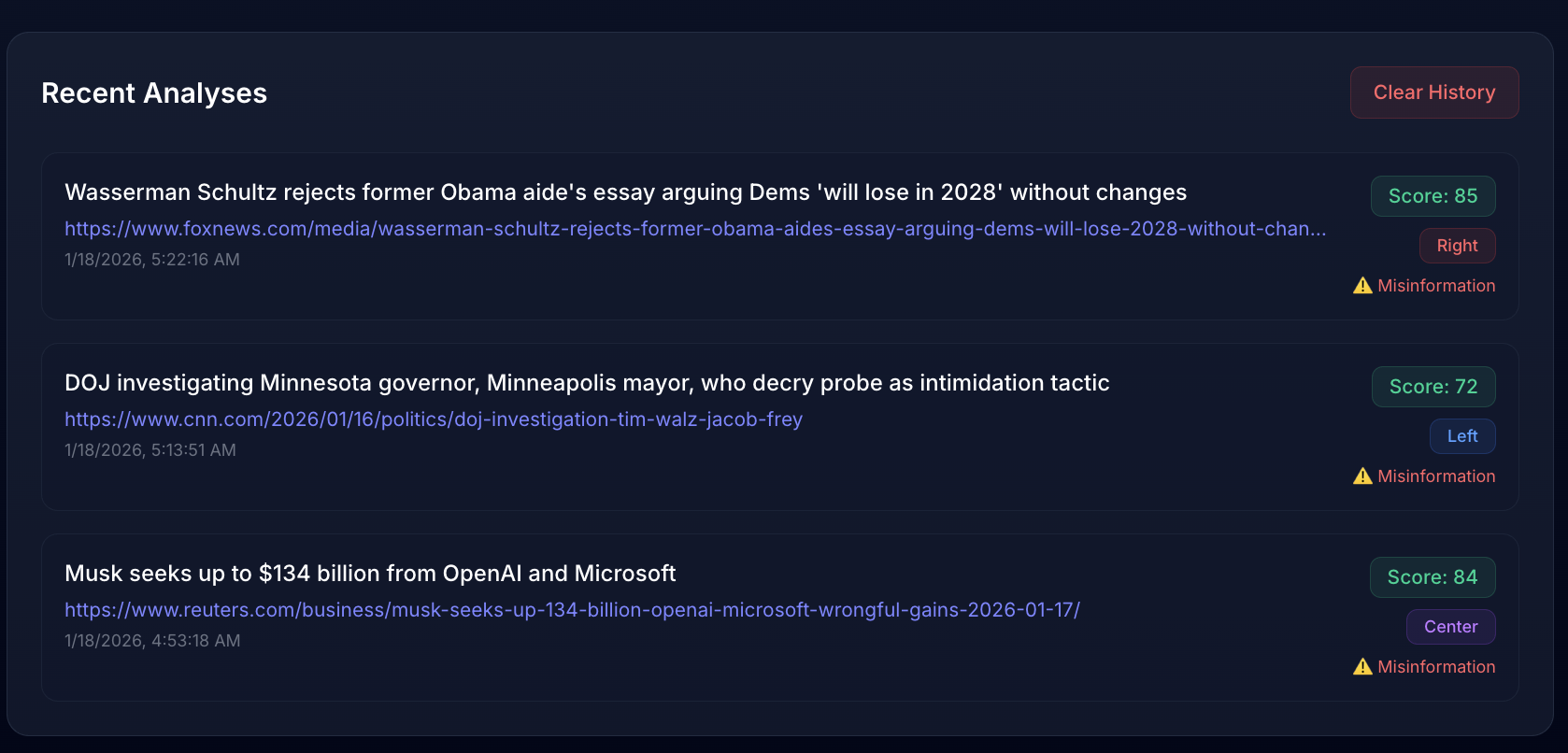
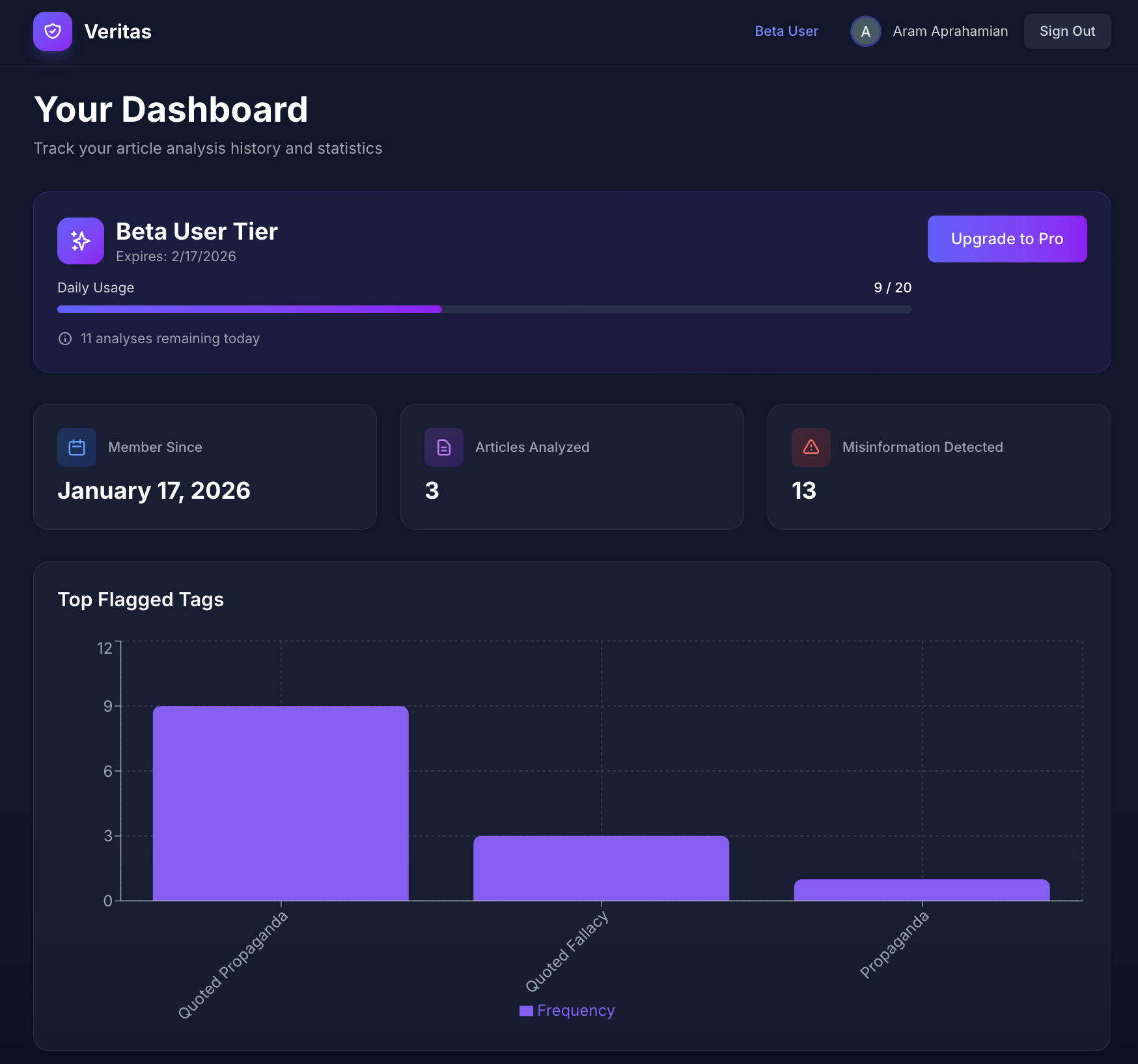
Dashboard-Activity History
-
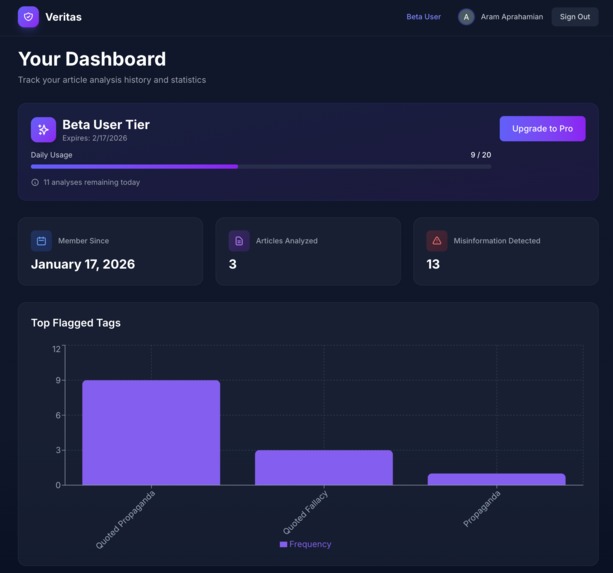
Dashboard-Trends
-
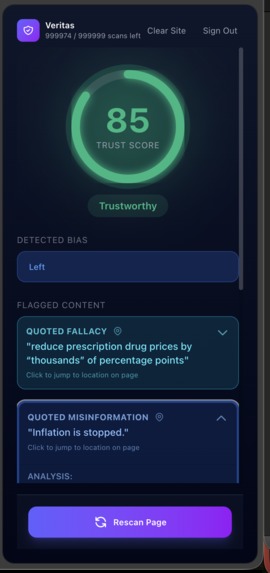
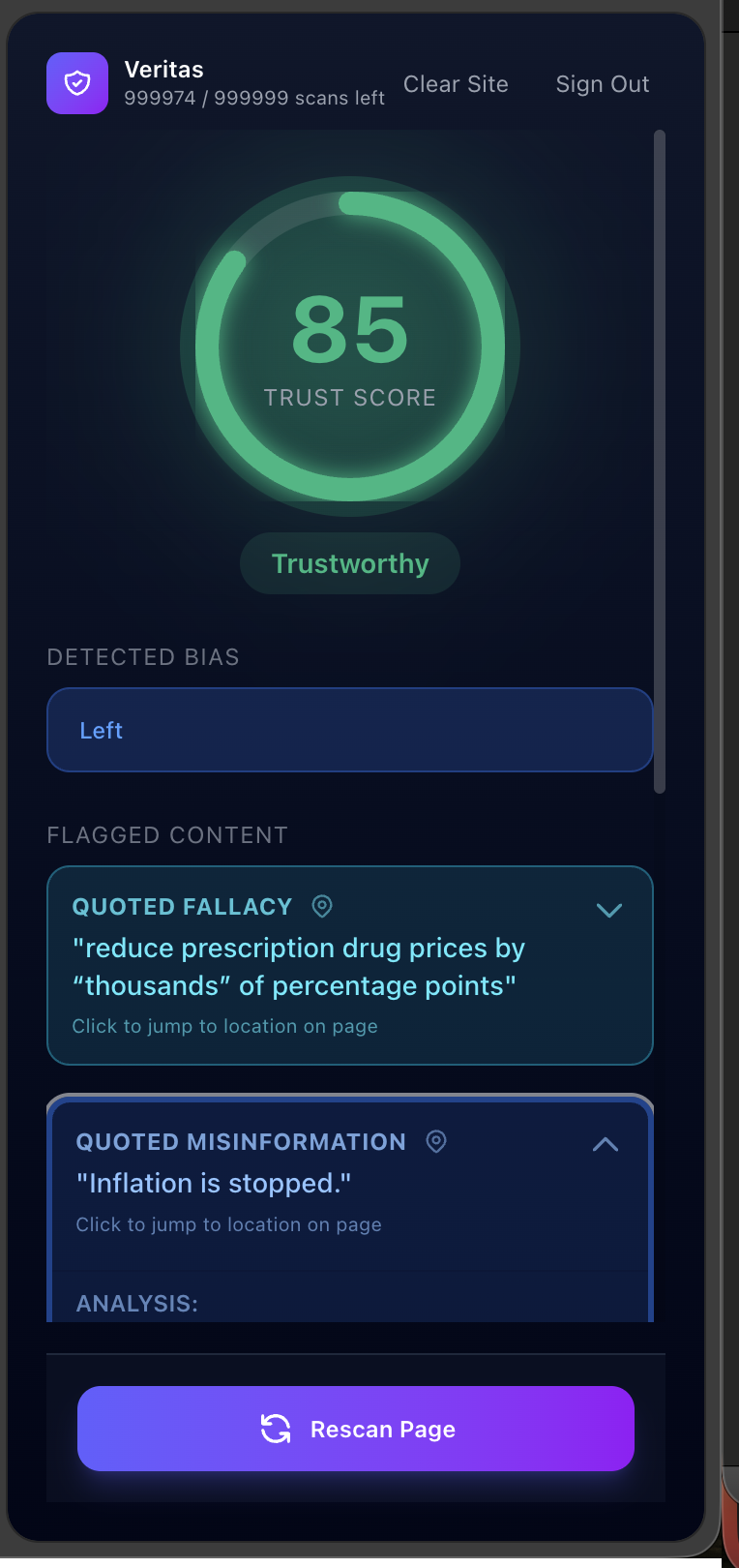
Veritas Trust Scale

Inspiration
The name Veritas comes from the Roman goddess of truth. I wanted to build an extension that tackles identifying misinformation in all shapes and forms and shows the truth. I took inspiration from Grammarly, the Grammar checking tool that many people have come to love. However, instead of grammar, my tool tackles media information. I specifically chose this thinking that it's a tool that could be highly effective for the people I care about and myself.
What it does
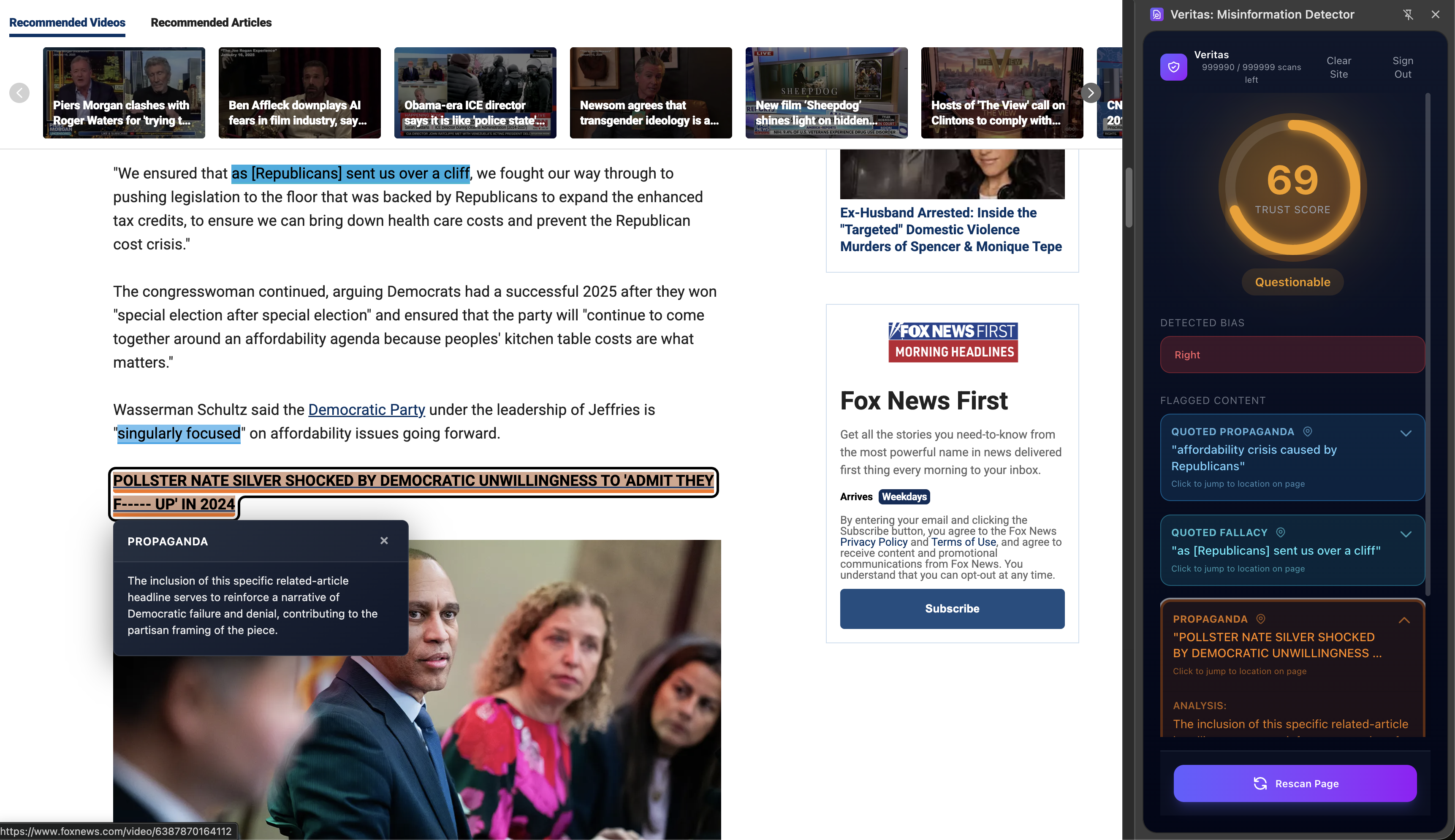
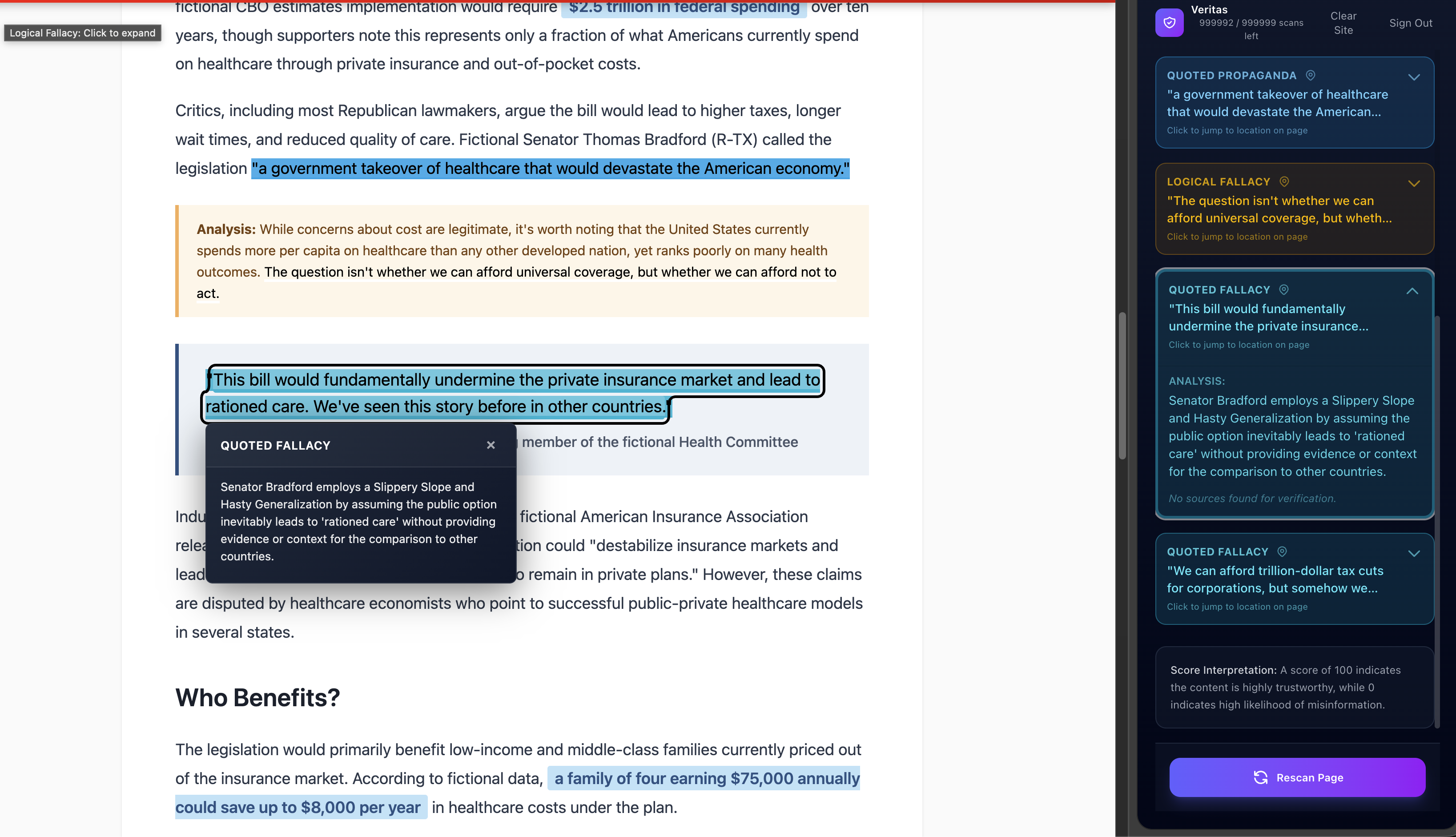
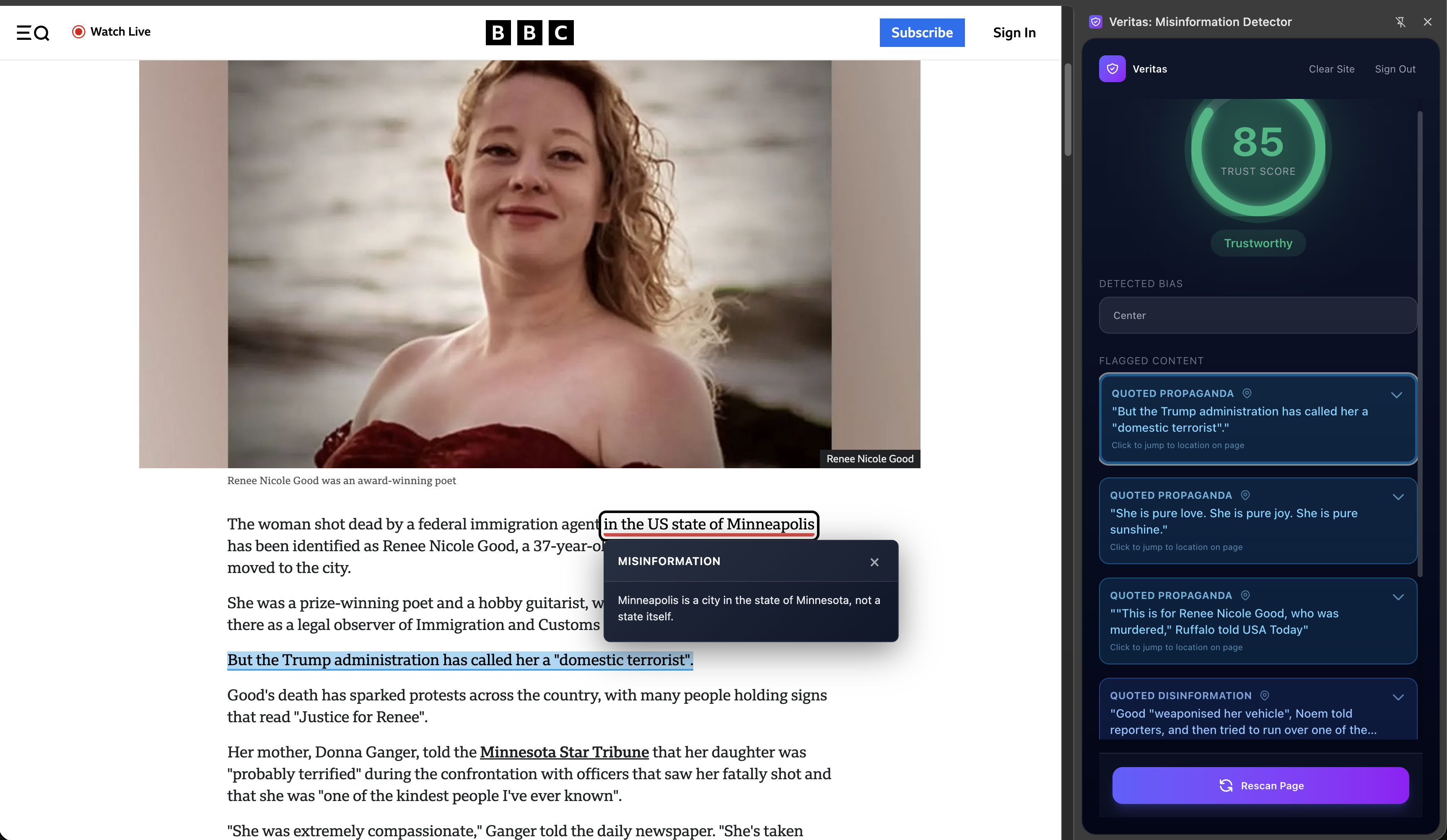
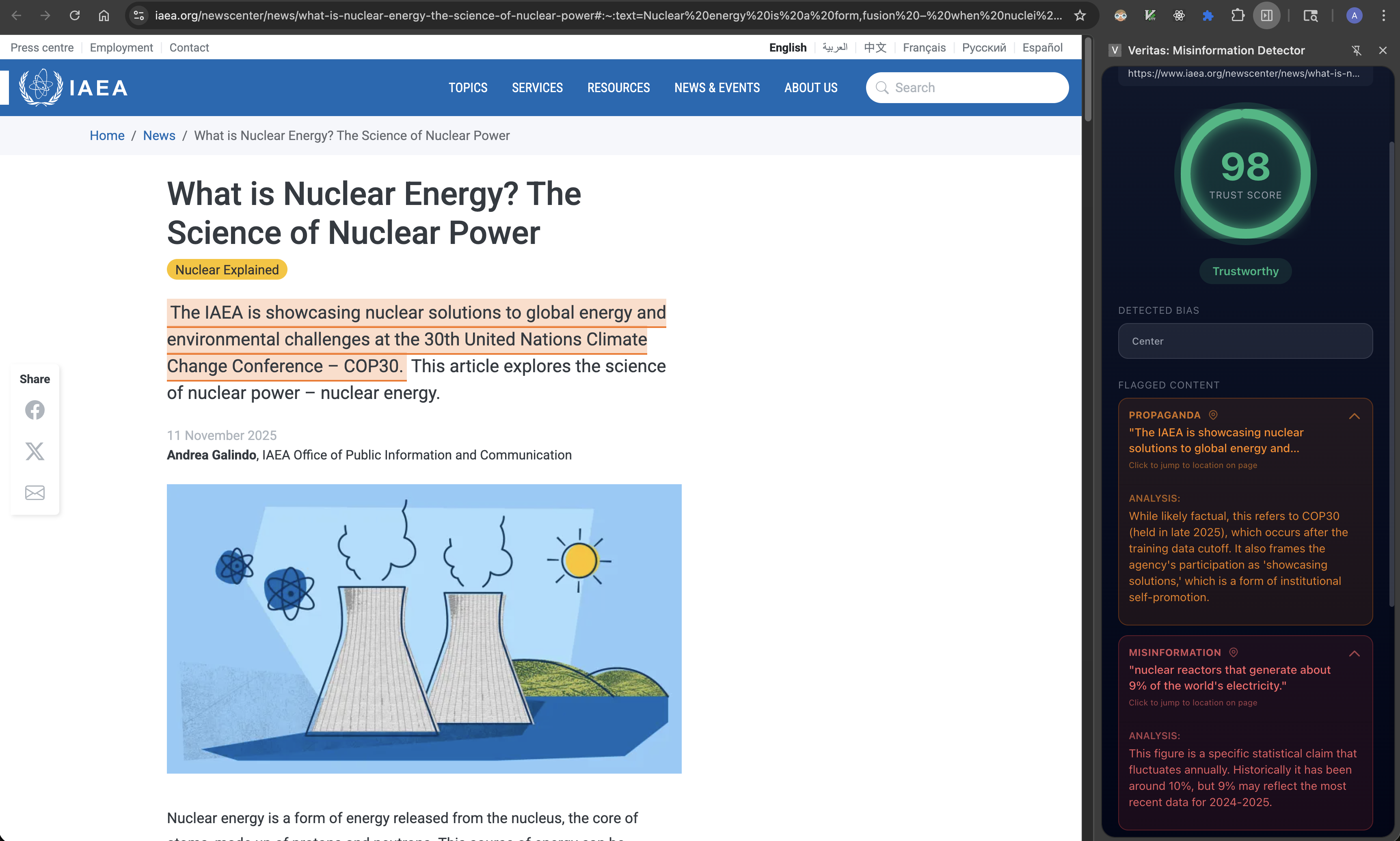
Veritas identifys misleading or false claims in media, cross referencing with reputable sources, and provides a "Trust Score", a score of how trustworthy an article. The program highlights areas with misinformation or with concerning phrasing. The "Trust Score" is measured uupon misinformation, logical fallacies, bias, and more to give you a strong insight of how much to trust what you're reading. The misinformation algorithm inside highlights questionable or wrong sentences, explains why its wrong or provides insight into how it can mislead the reader.
How we built it
Veritas is built upon Next.js and Vercel for the front end, React & Vue for the Extension, and Digital Ocean's database and web service for the backend and processing the misinformation detection api.
For authentication we utilized Auth0 for its ease of use and built in google auth. For payment systems I implemented stripe (in sandbox mode).
Initially, Veritas was going to use a combination of a predictive model based on a True/Fake news dataset with the help of Gemini, however that solution was not effective.
Our program identifys misinformation by using gemini for identifying high impact information, i.e., informational claims that should be fact checked, strong language, and misleading terminology, in addition to a url database lookup to see if the information is from a known biased site.
Gemini analyzes the flagged content for:
Output Structure:
{
"trust_score": 0-100,
"label": "Likely True" | "Suspicious" | "Likely Fake",
"bias": "Left" | "Left-Center" | "Center" | "Right-Center" | "Right",
"summary": "Comprehensive explanation",
"flagged_snippets": [
{
"text": "exact substring",
"type": "Misinformation" | "Disinformation" | "Propaganda" | "Logical Fallacy",
"reason": "why this is problematic",
"severity": "low" | "medium" | "high",
"is_quote": true/false
}
],
"verifiable_claims": ["factual claim 1", "factual claim 2", ...]
}
Alongside gemini we implemented two systems for identifying factuality. The system triages each verifiable claim into two routes:
Route A: Historical Facts This route applies for articles with no recent keywords (i.e., 'Today,', 'Last Month', etc) and for older publishing dates.
- Uses Google Fact Check API
- Searches databases (Snopes, Politifact, FactCheck.org, etc.)
- Returns: Verified | False | Misleading | Unverified
Route B: Recent Facts/Breaking news Indicators: "today", "breaking", "just now", current year mentions
- Uses Google Custom Search API
- Searches trusted news sources (Reuters, AP, BBC, NPR, etc.)
- Cross checks article information with trusted sources.
- Calculates credibility score based on consensus:
- 3+ trusted sources = 0.9 (Verified)
- 2 sources = 0.7 (Moderate)
- 1 source = 0.4 (Single Source)
- 0 sources = 0.1 (Unsubstantiated)
After this stage, the algorithm calculates penalties as such: Penalty Tiers:
- False claims: -25 points (scaled), label -> "Likely Fake"
- Misleading: -15 points per claim, label -> "Suspicious"
- Unsubstantiated: -8 points per claim (warning only)
- Verified claims: Boost to 80+ if many verified
After analysis of the article is completed, the data is cached and stored so reopening the webpage reopens the previously analyzed information. Recalculating everything every time you open the page would have been very annoying and be terrible for the environment.
Additionally, as you may have assumed with the inclusion of Auth0 and Stripe, I implemented a payment model to match the type of application you would likely see in the real world. I believed a subscription model fit best for this applciation.
However, don't worry about paying if you would like to try this out. I'll leave a discount code valid for a month and 20 articles a day. Just send me a quick email and say hi! :)
Challenges we ran into
During this hackathon I kept a log of the multiple problems I faced when developing this application. Many problems I had no idea I would be a problem.
- The first major problem I faced was just with the sheer scope of my program. I knew that I wanted to do a chrome extension misinformation ideintification tool, and with it I would need a backend for processing, a front end for web services, and more. I've never built an application with as wide of a scope as this. I think I could definitely say this was full-stack.
- The second major problem occured with my initial development towards a predictive fake news model and Google Gemini 3 Fast.
- I had forgotten that AI models usually are a year or more back in training data - these algorithms have no idea what is happening currently. Due to this, any event in an article past mid 2024 would cause the LLM to throw a fit, saying 'Thats fake' to anything past its latest training data. This was especially true when it came to analyzing news articles. When it came to the current sitting president and it being 2026, the LLM would throw an admittedly silly tantrum marking everything relating to it as misinformation.
- With LLM's being a popular tool in this hackathon (I used Gemini 3 Pro and Claude 4.5 Sonnet quite liberally), I found that a large scale project like this overloaded the chatbots progressively, forcing me to switch my methidology to tackling one part at a time and keeping track of the architecture + problems in a notepad.
The predictive model was not that effective either. While it still exists in the current program as a fallback, its only good for giving a general sense of an article being 'Fake'. It definitely doesn't identify false information.
Accomplishments that we're proud of
- I'm quite proud of how well the extension integrates into chrome and general web browsing. It has identified misinformation, propaganda, and logical fallacies (as well a wording mistake in a BBC news article).
- Additionally, I'm very happy with the UI+UX Design of this application. I spent much of my time tuning user interactions with this and it payed off.
- On top of those, I'm somewhat happy with myself for being able to put together all an application with as many services as it has.
What we learned
- When working with LLM technology, work modularly, small parts at a time to build up the whole
- Keep track of your system architecture, spend a lot of time initially building a strong understanding of the program's purpose.
- Equal time needs to be put into the UI/UX of the application as the backend.
- Its intimidating to be solo and a first time hackathon participant, but its doable, and I personally learned a lot through being solo. Albeit, next time I definitely do NOT want to be solo again.
What's next for Veritas: Misinformation Detection
- Google Chrome full release
- Improving the Misinformation algorithm to be faster and more effective at identifying misinformation.
- Social media implementation to see when someone's posting misinformation. Especially with X, Reddit, and Facebook.
Built With
- auth0
- digitalocean
- gemini
- google-custom-search
- google-fact-tools
- google-generative-language
- javascript
- next.js
- python
- react
- stripe
- typescript
- vercel
- vite

Log in or sign up for Devpost to join the conversation.