Verta: Building Discord Knowledge that Actually Works
The Problem with Discord Support
In medium to large Discord communities, we see the same pattern: users ask the same questions over and over, just phrased differently. "How do I install this?" becomes "installation broken" becomes a screenshot of an error with "help???"
Discord is where community knowledge goes to die. Solutions get buried in thousands of messages. Search is useless when you don't know the exact keywords. Moderators waste time answering the same thing repeatedly.
The Takaro gaming community faced exactly this issue. Hundreds of thousands of messages, valuable solutions scattered everywhere, and no good way to surface relevant answers. We built Verta to fix this.
How Verta Actually Works
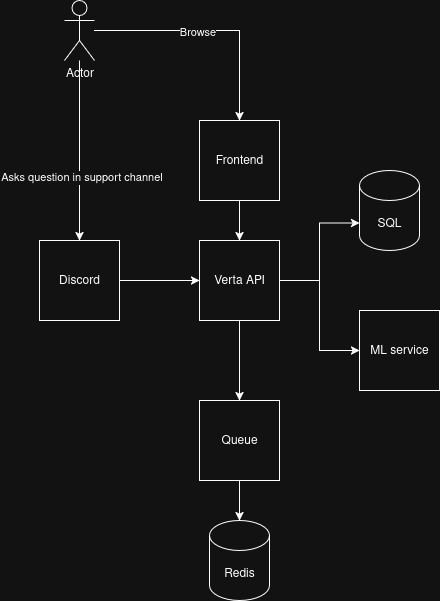
Verta builds intelligent knowledge from Discord chaos through several key components:
Discord Sync with OCR
First, we sync messages from Discord into a database. But here's the important part: we also OCR screenshot attachments. Users constantly post screenshots of error messages, and that text needs to be searchable. A screenshot saying "DirectX initialization failed" becomes searchable text in our system.
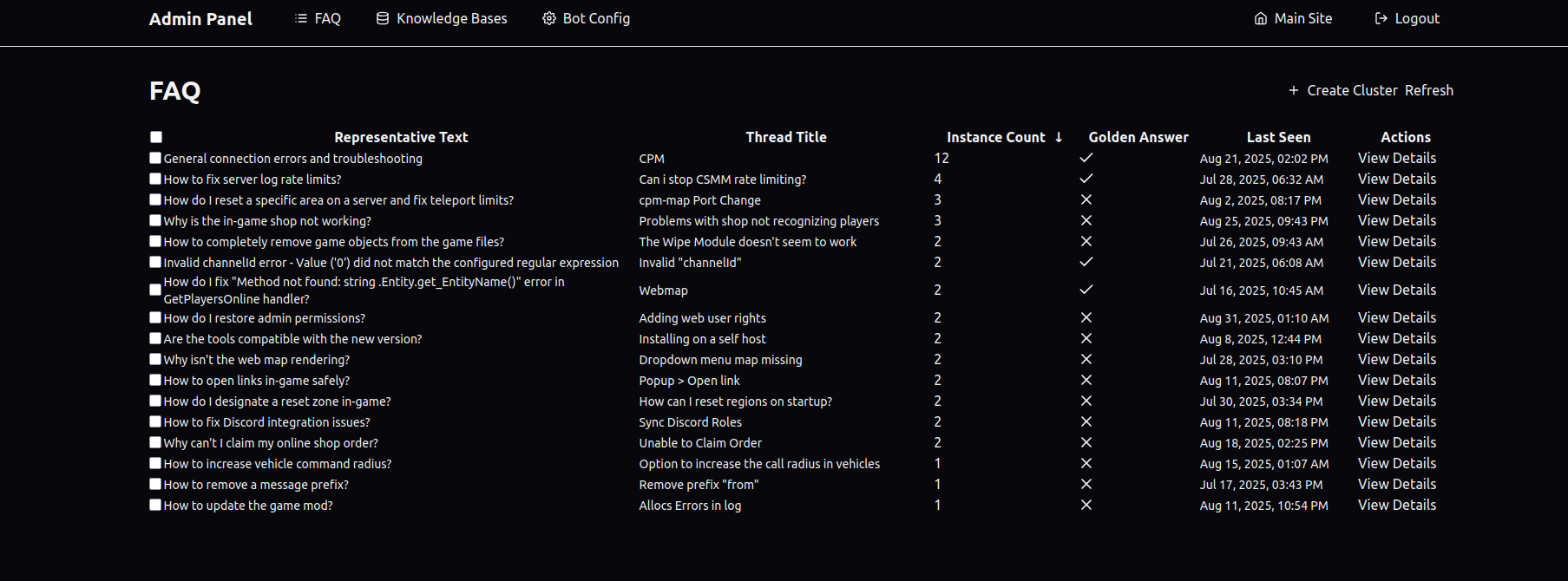
Question Clustering
This is where TiDB's vector search shines. We analyze Discord threads to extract the core questions being asked. First, a self-hosted question classifier model determines if the extracted text is actually a question (not just random conversation). Then we group similar questions together using vector similarity:
SELECT representative_question, similarity
FROM question_clusters
WHERE VEC_COSINE_DISTANCE(embedding, ?) < 0.15
"How install mod???" and "installation instructions please" and "where download" all become part of the same cluster. Instead of thousands of unique questions, we end up with a manageable set of common issues.
Multi-Step Search
When a user asks a question, we don't just do one search and call it done. Our search system:
- Searches across golden answers (admin-approved responses), knowledge base docs, and message history
- Sends results to an LLM which analyzes them and suggests follow-up searches
- Executes those additional searches (maybe searching specific knowledge bases or related keywords)
- Combines everything into a comprehensive response
The LLM might see "installation error" results and realize it should also search for "permissions issues" based on the context. This multi-step approach finds answers that simple keyword matching would miss.
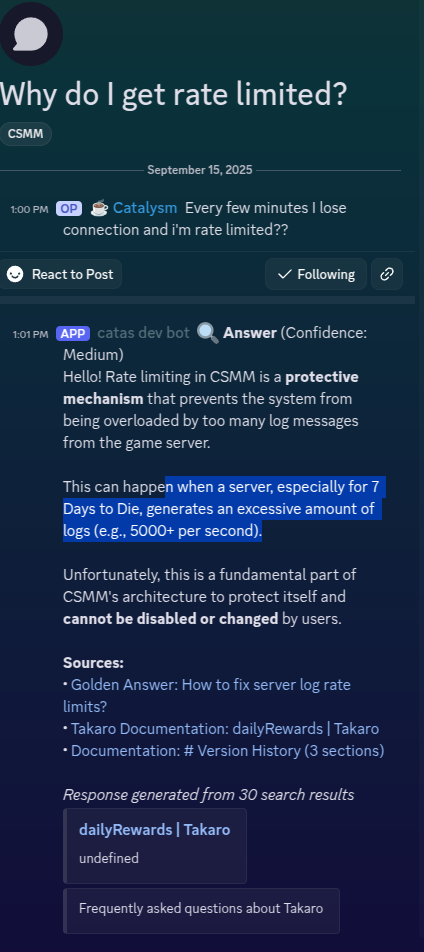
Golden Answers
When moderators see a particularly good response to a common question, they can mark it as "golden." These become the preferred answers for that question cluster, creating a knowledge base that improves over time.
Building on TiDB
I'll admit—I usually default to Postgres for everything. But TiDB's vector search made this project straightforward. We store embeddings right alongside our regular data, use standard SQL with vector operations, and it performs well even on the free tier.
The combination of traditional SQL filtering with vector similarity is powerful. Need messages similar to a query but only from the last week in specific channels? One query handles it.
Current Status
We've deployed Verta in the Takaro community. Some responses are great, others need work. We're learning what works and iterating. That's the reality of building AI systems—you deploy, learn, and improve.
The question clustering has already identified common issues we didn't even know were that common. The golden answers system lets moderators build up authoritative responses over time. And the multi-step search finds relevant context that single-pass systems miss.
Technical Details
Built with TypeScript/Node backend, Python ML service that runs multiple models (embeddings, OCR, and a CPU-based question classifier), TiDB Cloud for vector storage and search, Discord.js for bot integration, and BullMQ for async job processing. Everything runs in Docker containers.
The multi-step search showcases what modern RAG applications need: not just embedding and retrieval, but intelligent query expansion, multiple search passes, and continuous learning through user feedback.

Log in or sign up for Devpost to join the conversation.