-
-
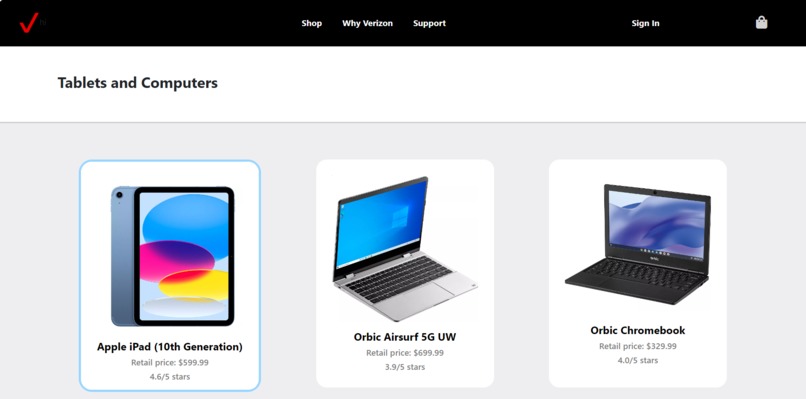
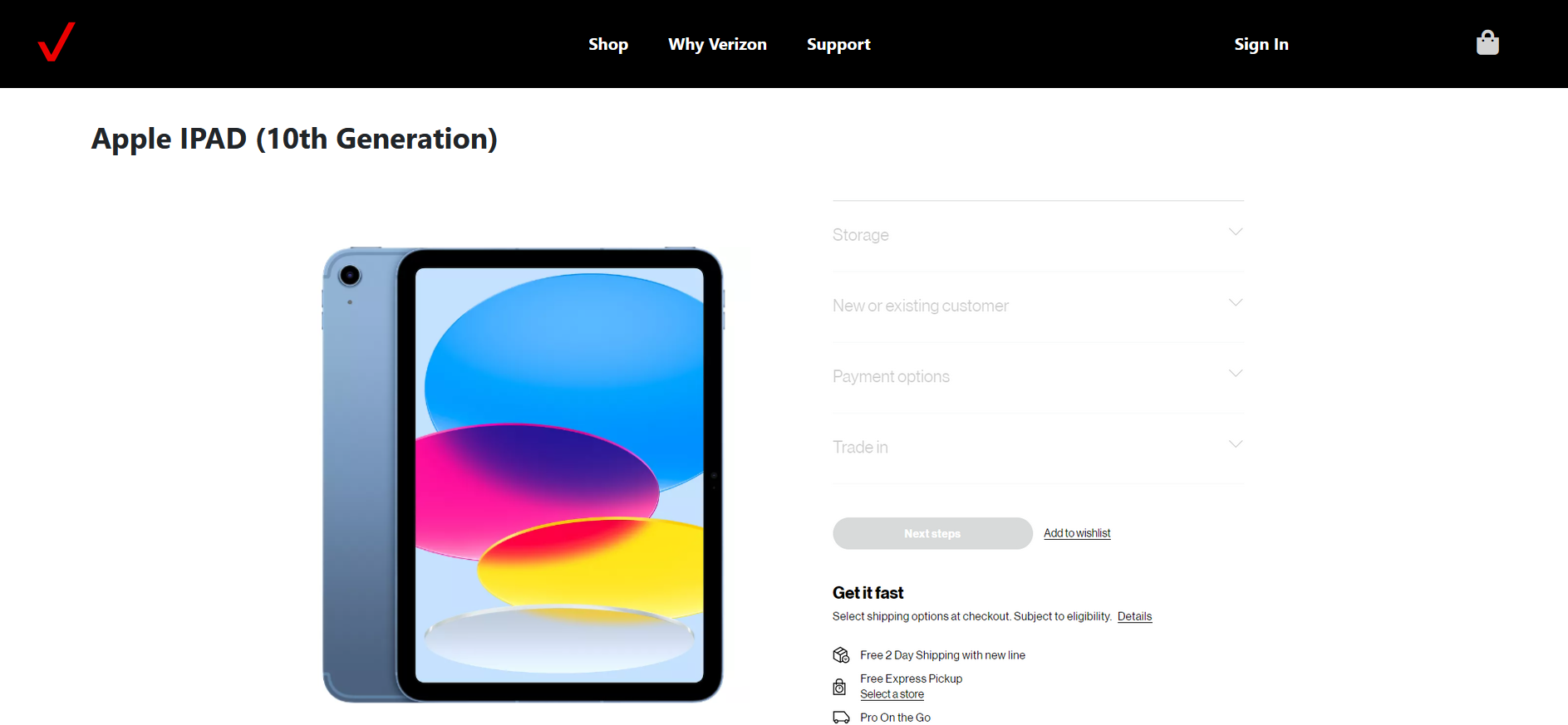
Front End mockup of Verizon Products Page
-
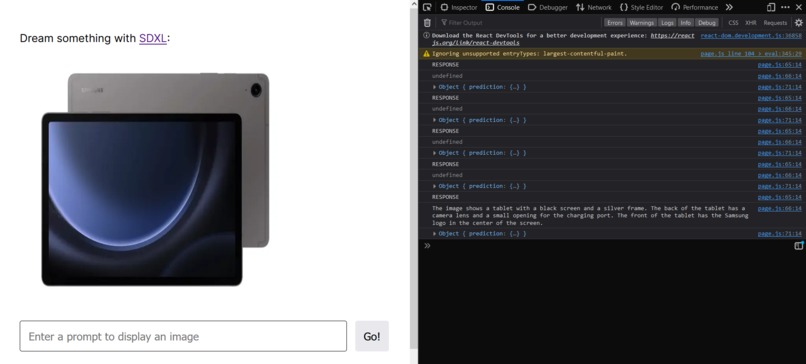
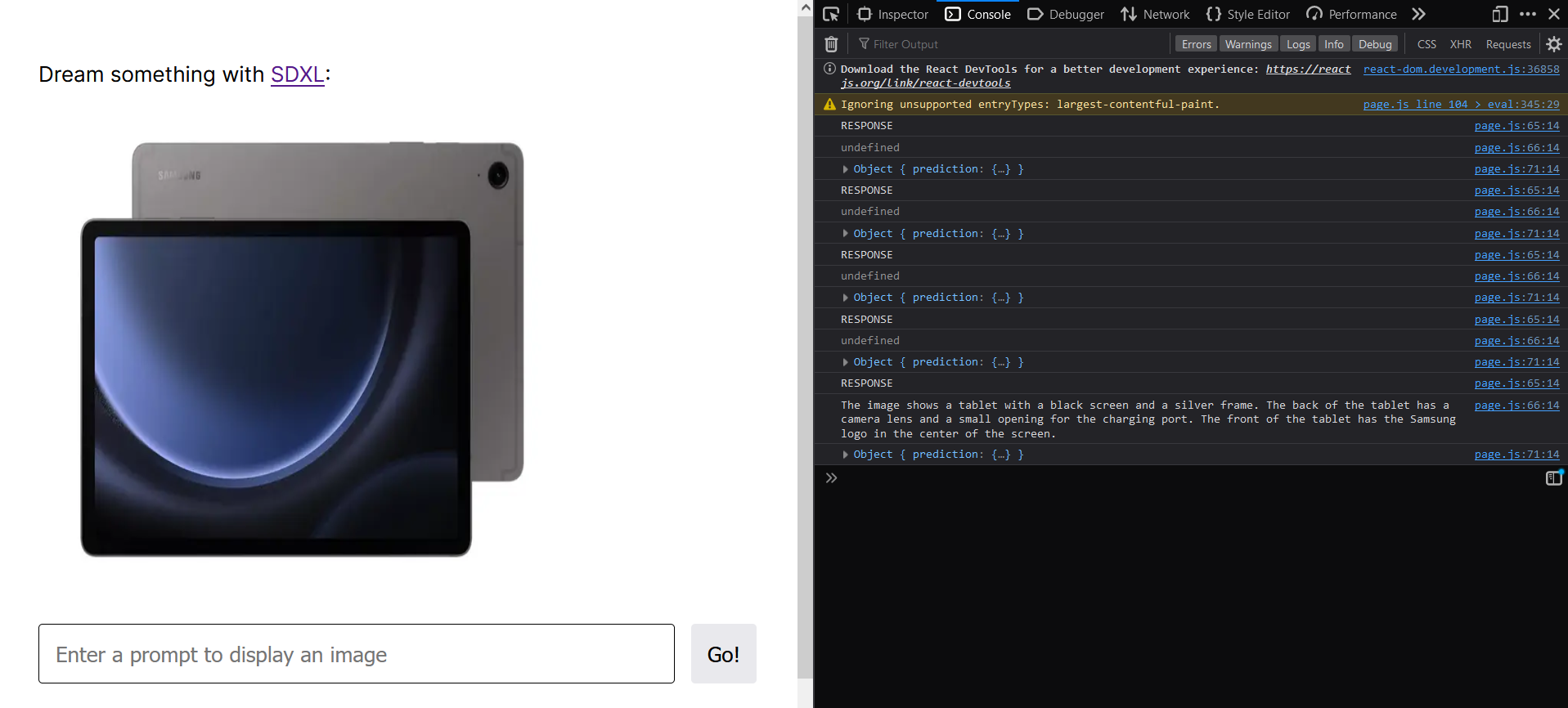
Back End API
-
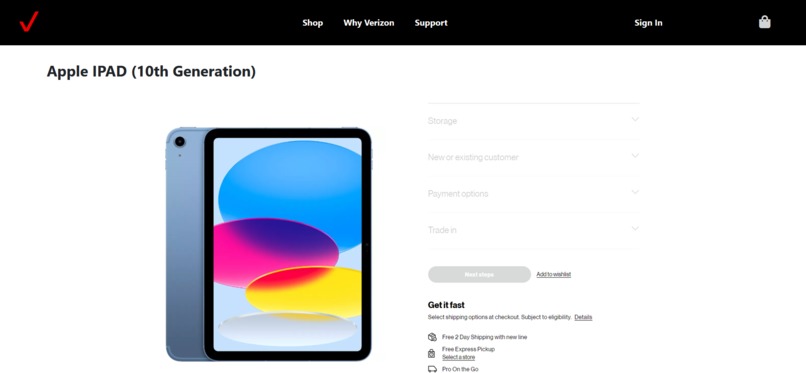
Product Page Mockup
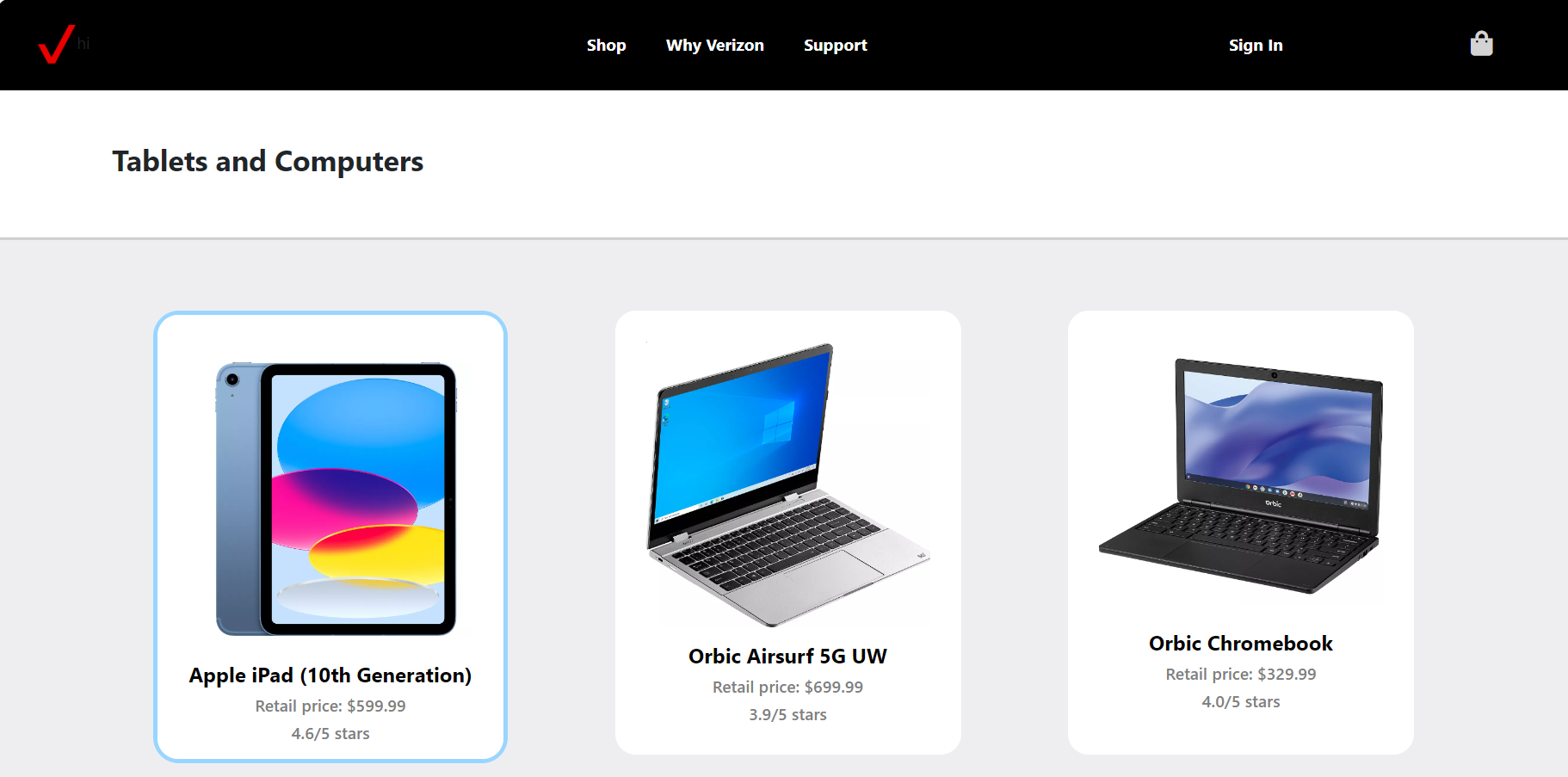
Inspiration
The inspiration for this project was purely a desire to make accessibility more dynamic considering the advantages provided by machine learning.
What it does
The model connects to the Replicate API to generate alt text for images. From there the text is put through the native text-to-speech functionality of the browser.
How we built it
The project can be divided into two websites hosted through Github Pages. The frontend is a mockup of the Verizon Products website, and the other being the backend tool for generating alt text.
Challenges we ran into
The primary challenge was not just generating alt text, but getting image data to the Replicate API. In addition we had some challenges putting together a polished frontend to work with in tandem with our alt text tool. Finally we have the challenge of the loading times for the alt text, which unfortunately isn't optimizable due to the time it takes to run stable diffusion. We weren’t able to fully connect our Verizon frontend with the backend calling the replicate api, so we hardcoded the output from the stable diffusion API for each product image and outputted it to the user via the web speech api. However, in the future if we had more time, we’d do this dynamically from the url of the image the user clicked.
Accomplishments that we're proud of
In the end our frontend came together well. Our alt text tool was capable of correctly generating text for the products page and we expect it to be expandable to other sites with some work.
What we learned
This project really pushed our team's skills in web development.
What's next for VerizonVox
For now the team would like to focus on generalizing the tool to other websites and improving the delay time if at all possible.
Built With
- github
- next.js
- replicate(stable-diffusion)






Log in or sign up for Devpost to join the conversation.