-
-
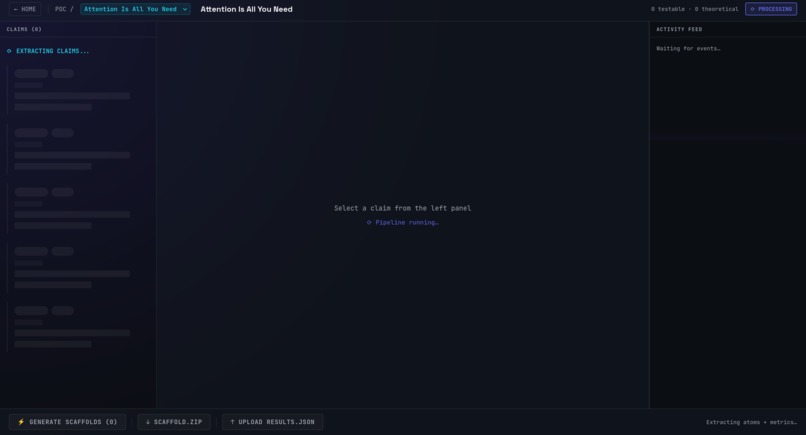
Proof of concept mode
-
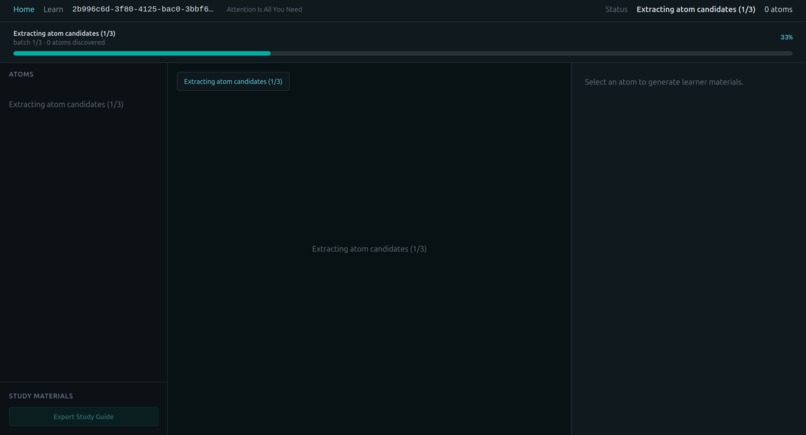
Learning mode in running
-
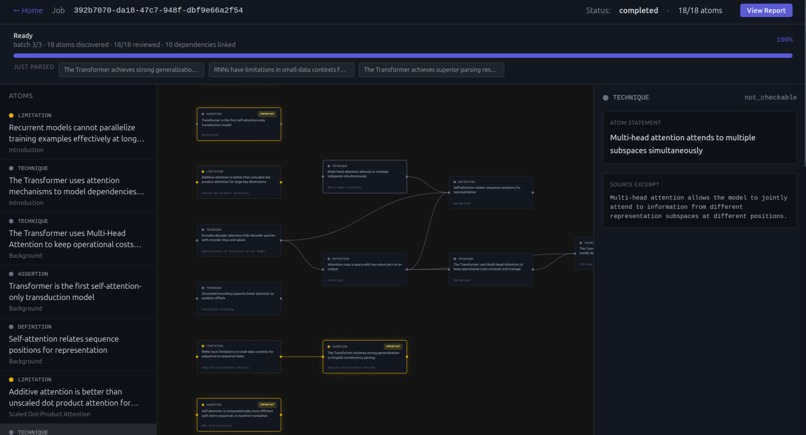
Peer review functionality
-
Landing page
-
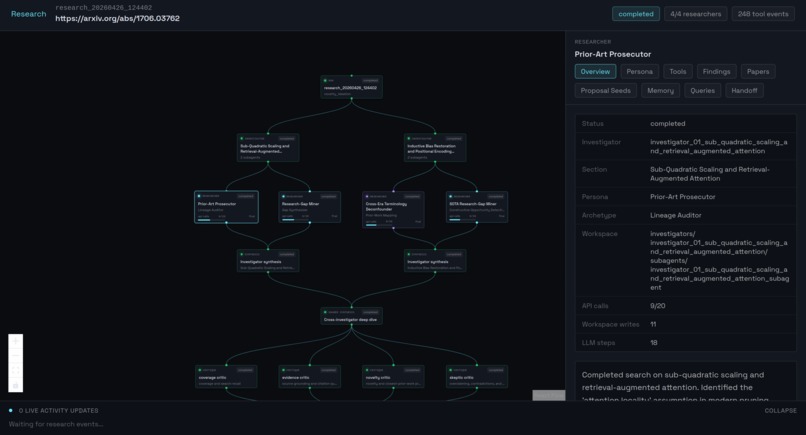
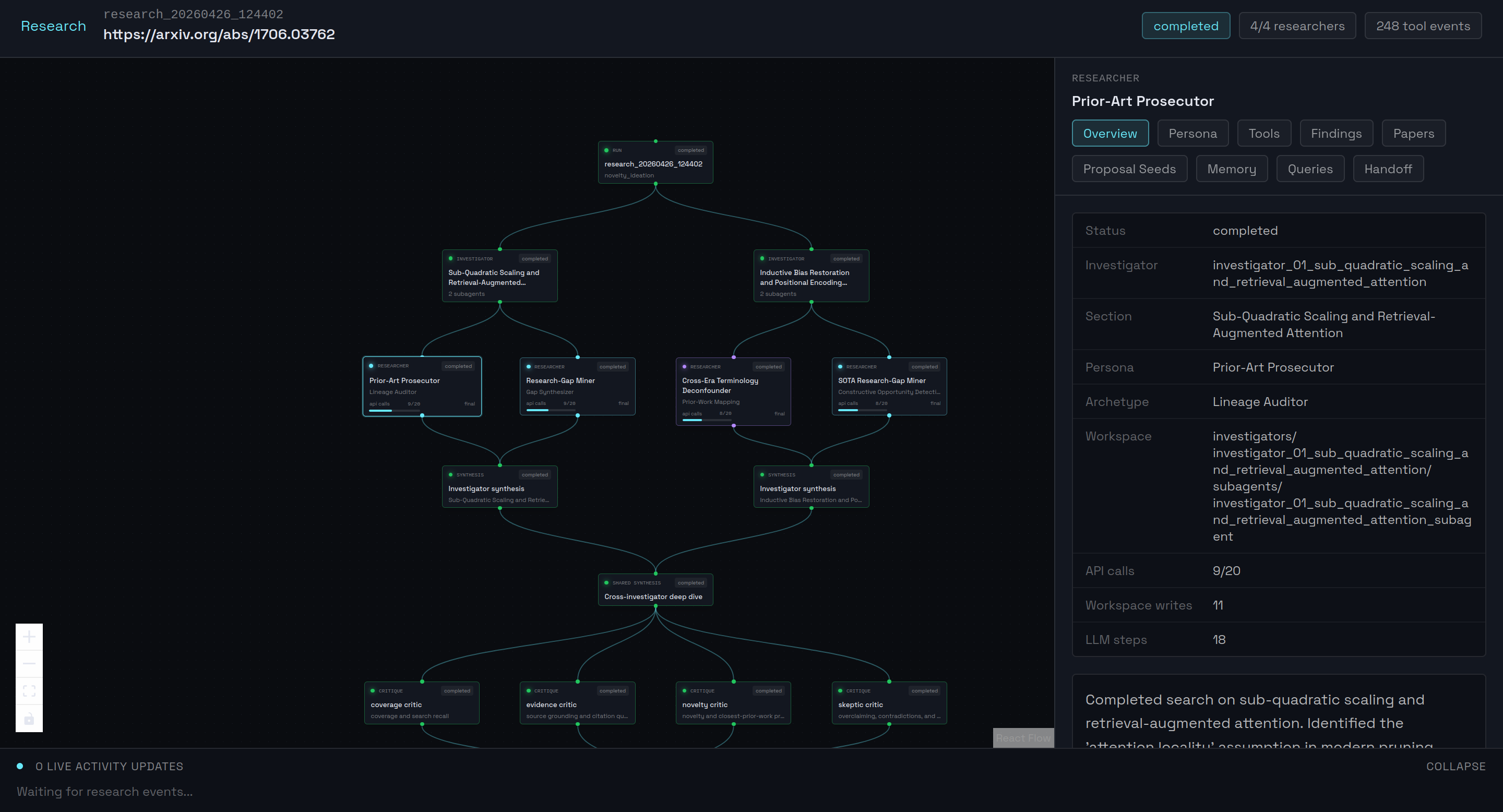
Deep research mode
-

Logo

Research is hard. Not intellectually hard (that's the point). Hard in all the ways it shouldn't be.
You find a paper that might be relevant. You spend an hour reading it before realizing it assumes three other results you haven't read. You track those down. One of them has a proof that doesn't quite feel right, but you can't tell if it's wrong or if you're missing context. You open twelve tabs. You lose the thread. You start over. And that's before you've done any actual research.
The problem isn't that science is difficult. The problem is that every tool researchers use treats the process as an afterthought. Papers are static PDFs. Notes live in a different app. Verification is manual so you either trust the math or you re-derive it yourself. Literature search is keyword matching. Understanding a new field means reading in circles until something clicks.
There is no system that holds it all together. No single place where you can read, verify, explore, and understand without having to constantly context-switch and losing momentum.
We built Veritas because we kept hitting that wall, and we wanted to know what research felt like without the friction.
What We Built
Veritas is a research OS with four modes:
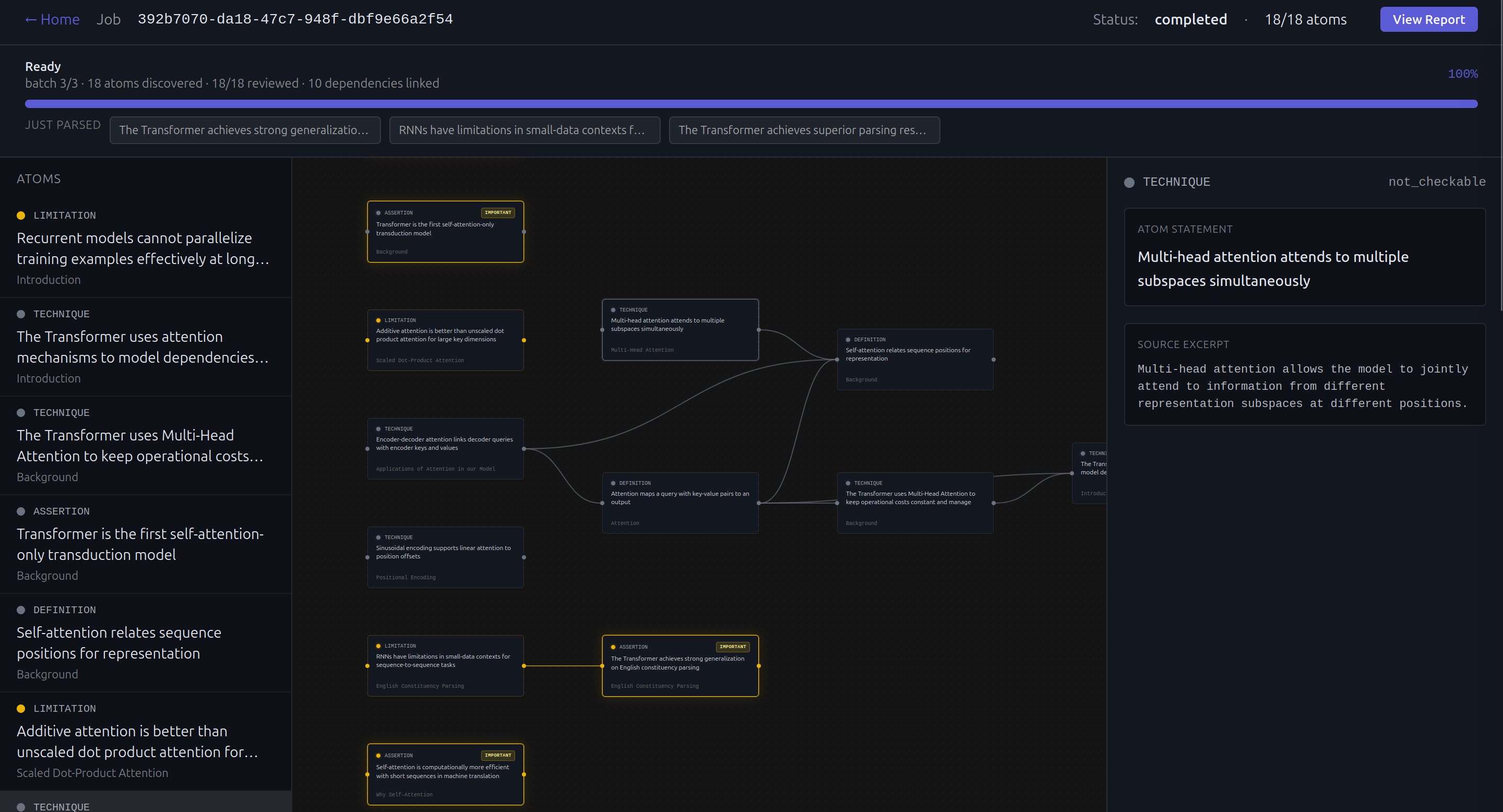
Peer Review: Upload any paper. Veritas decomposes every claim into atomic units, maps their logical dependencies into a DAG, and runs adversarial agents to verify, challenge, and cross-reference each one against the literature. Every claim exits as verified, contested, or falsified. If a lemma breaks, every downstream theorem that depends on it is automatically flagged for review.
Deep Research: Multi-agentic swarm for literature synthesis. Surface related work, contradictions, and open problems across arXiv and Semantic Scholar. Allows the user to surface gaps in literature and generate hypothesis for their research.
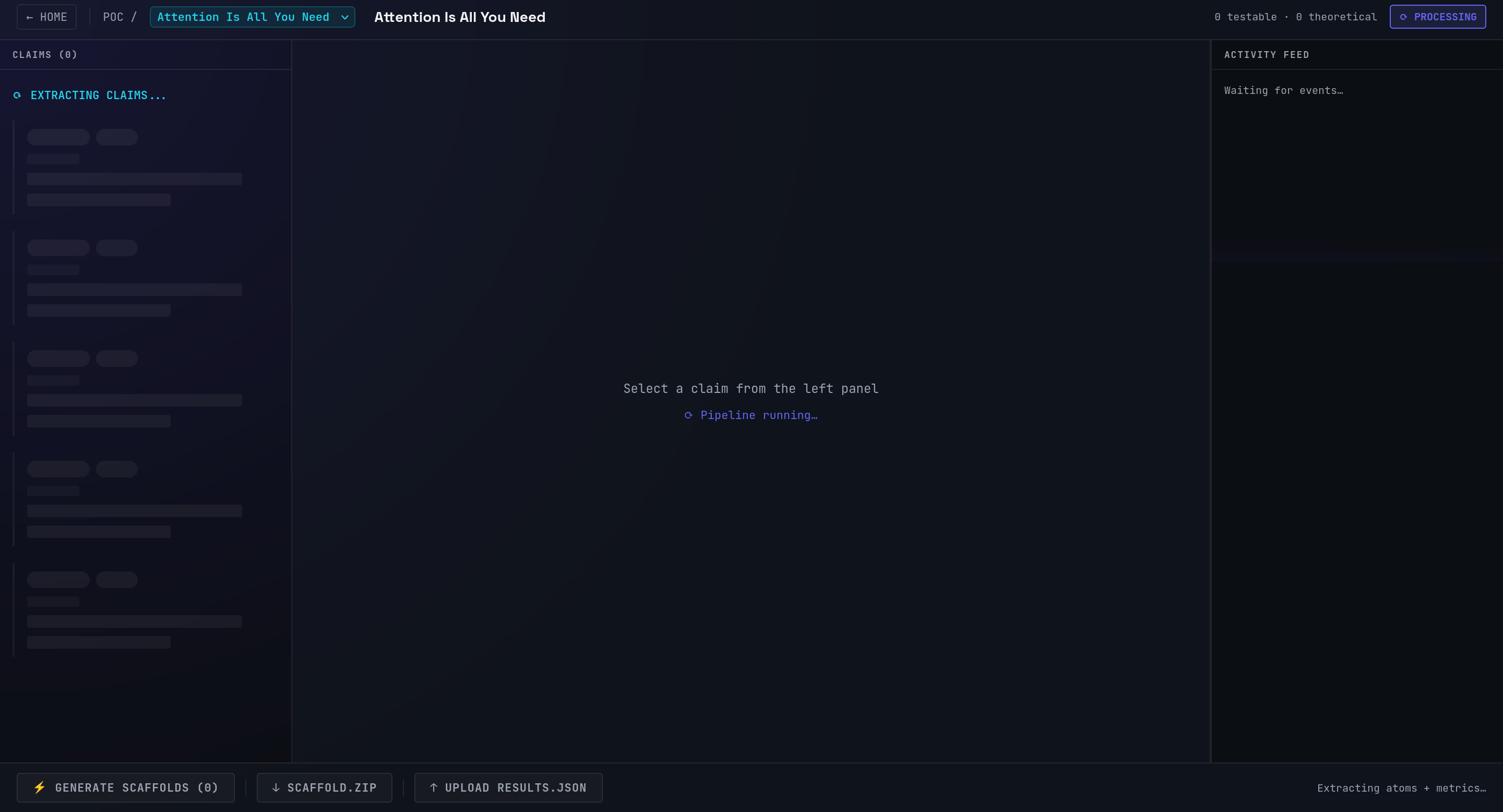
POC Generator: Verifies the claims made in the papers via code generation. It generates code that compares the correct implementation against the claims made by the paper allowing the user to replicate parts of the paper to see if it makes sense.
Learning Mode: Click any concept and the prerequisite chain unfolds inline, from that term back to first principles. Research shouldn't require you to already know everything, we let users chat to the paper and also generate questions to help them learn.
How We Built It
The core architecture is a proof-theoretic dependency DAG. We extract claims from papers, build a graph of their logical dependencies, and run verification in topological order. Technical features used
- Async multi-agent orchestration
- Typed Pydantic interfaces
- Round-to-round context compression to keep deep verification sessions coherent without blowing the context window
- Lean 4 for formal proof export (Experimental feature)
Challenges
PDF parsing is harder than it looks. Mathematical papers are LaTeX compiled to PDF so extracting equations reliably, especially from dense theory papers, required multiple fallback strategies.
Getting the DAG correct was highly challenging as sometimes the claims won't really link to each other or they might make no sense because of poor context handling.
Cost control on adversarial search. Uncapped sub agents blow up API costs fast. We implemented per-claim challenge budgets and token guardrails, calibrating the tradeoff between coverage and cost. We also experimented with different LLM providers and also different sizes of LLM to compromise for API costs.
What we learned
The most surprising thing: the DAG isn't just a verification tool but rather it's a reading tool. Seeing a paper's logical structure laid out as a graph changes how you engage with it. You immediately see which results load-bear everything else. That insight became the backbone of Learning Mode. We also learned that typed interfaces between agents aren't optional. Early versions passed raw strings and hallucinated constantly. Typed Pydantic outputs cut that dramatically and made debugging tractable. Most of all, we learned that the friction in research isn't inevitable. It's an infrastructure problem. And infrastructure problems have solutions.
Built With
- agents
- claude
- devin
- gemini
- inference
- javascript
- python


Log in or sign up for Devpost to join the conversation.