-
-
Home page
Inspiration
Imagine your retirement fund vanishing overnight. Hundreds of thousands of dollars lost, and all because of one company. For Enron employees in 2001, this was the reality — the people they trusted with their money were lying to them. The signs weren't invisible. They were hidden in facial expressions, speech patterns, and pitch. Patterns that are almost impossible for a human to spot. We kept coming back to a simple question: what if those signals could be systematically captured and measured? Academic research suggested they could. Mayew & Venkatachalam (2012) showed that vocal affect in earnings calls predicts analyst behavior beyond what transcripts alone capture. Akansu et al. (2017) found that fear-based facial expressions correlate with short-term equity price changes. The science existed. The accessible, productized tool did not. Existing tools like LiarLiar.ai frame this as binary deception detection — a blunt instrument with shaky scientific foundations. We asked a more precise, more actionable question: Not just "is this person lying?" but "do the behavioral signals around this statement align with statements that later proved true — or false?" That reframe became the foundation of Veritais.
What it does
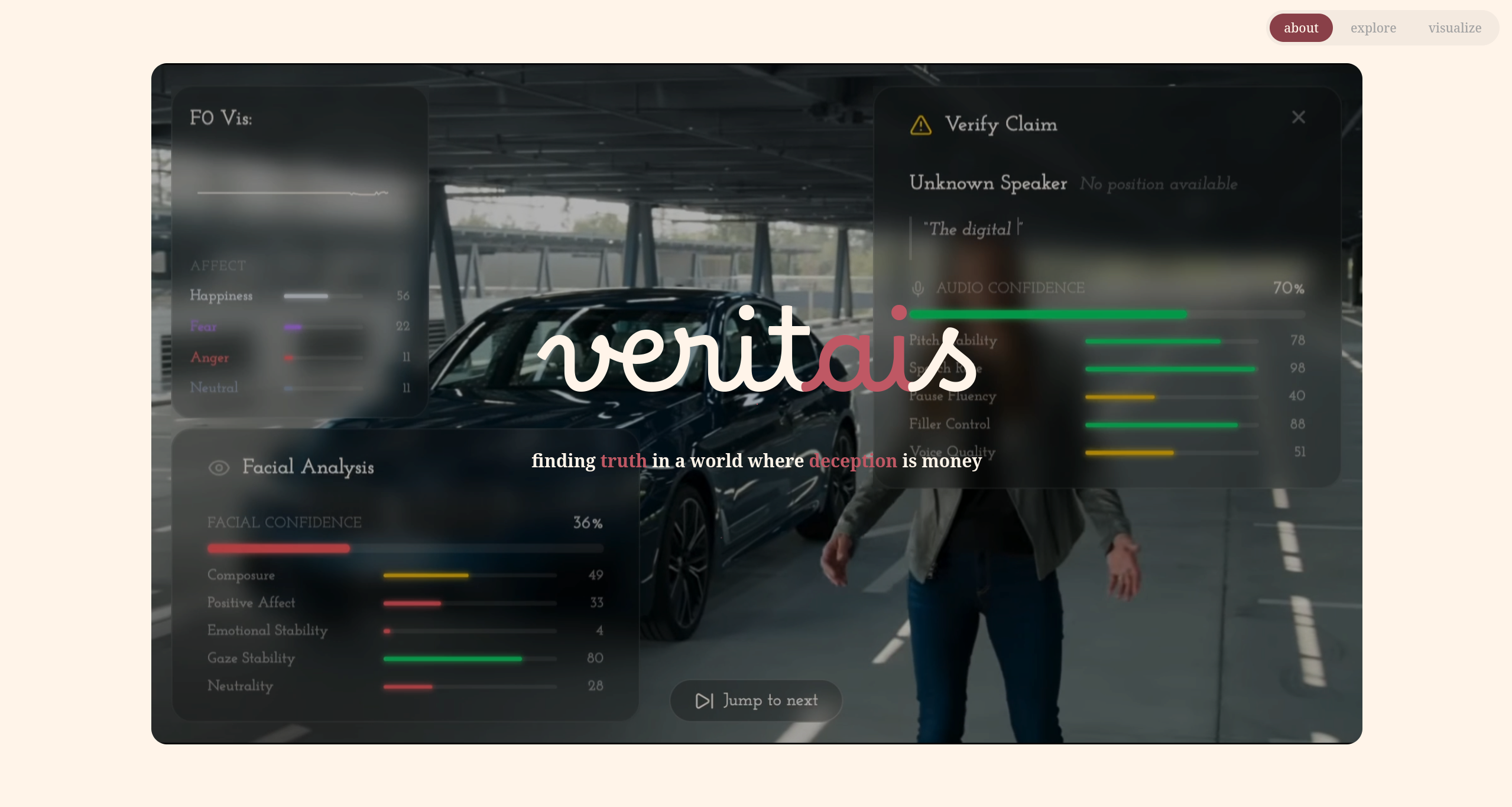
Veritais is the world's first comprehensive sentiment analysis tool built specifically for financial accountability. It uses machine learning to combine audio, text, and visual data to assess whether a company executive is telling the truth. The core mechanic is a learned truthfulness model. We collect public video statements made by CEOs and executives, then verify whether those statements were true or false after the fact — using earnings reports, SEC filings, and LLM-based proposition verification. Statements confirmed as true are associated with the behavioral signals present when they were made: the speaker's facial features, their speech patterns, their vocal quality. Statements confirmed as false are associated with the opposite. Over time, Veritais builds a robust classifier that can make inferences on live or new video streams based on this learned behavior. The output is a Truth Index — a per-company score built from the aggregate track record of its executives' public statements:
$$\text{TruthIndex}(c) = \frac{1}{N} \sum_{i=1}^{N} \mathbb{1}[\hat{y}_i = y_i] \cdot w_i$$
Where:
- \( \hat{y}_i \) — Veritais prediction for statement \( i \) (true/false)
- \( y_i \) — verified ground truth outcome
- \( w_i \) — recency weight, so recent statements count more than older ones
- \( N \) — total verified statements for company \( c \)
The per-statement conviction score fuses two signal streams: the facial and audio (linguistic) scores.
Key product features:
- Leaderboard — a ranked comparison of the truthfulness scores of top CEOs across the market, updated as new statements are verified
- Truth Index Graph — an aggregate timeline showing a company's track record of keeping its promises, surfacing trends before they become headlines
- Live inference — Veritais applies learned patterns to new video in real time, scoring statements as they are made
How we built it
The pipeline has four stages, each form a closed-loop module and individually testable.
Stage 1. Automatic Video Statements Discovery
Facilitated by the LLM, the system periodically scrapes YouTube with generated point of interests and automatic relevance judge. Video metadata is delivered to a distributed cluster of Analytics nodes.
Stage 2. Video Transcription and Speaker Fingerprinting
Upon receiving a task, the analytic node will produce a transcription through Whisper V3. Then a RAG enhanced multi-turn agent is engaged to infer the speaker identity. This information assists the program to build a vector database of the facial and voice fingerprint of corporate speakers.
Stage 3. Parallel Proposition Extraction
A sub-module of the analytic node starts to extract verifiable propositions when received the transcript. Since some important information are only available in the imagery, a VLM is used with tools for getting important video frames. The video fingerprint of each statement is compared with the existing embedding in our vector database.
Stage 4. Audio and Facial Analysis
Using PyFeat, we extract Action Unit (AU) intensities per frame at 2fps. AUs are the discrete facial muscle movements that underlie expressions, coded in the Facial Action Coding System (FACS). The key AUs for our model:
- AU6 + AU12 (Duchenne smile): genuine vs. performed positive affect
- AU4 (brow lowerer): concentration and cognitive load
- AU45 (blink rate): deviation from personal baseline signals stress
The facial score per window is computed relative to the speaker's own baseline established during scripted prepared remarks:
$$\hat{F}(t) = \frac{F(t) - \mu_{\text{base}}}{\sigma_{\text{base}}}$$
This within-person normalization is critical, as we measure change from baseline, not absolute values against a universal threshold.
Using librosa and Praat, we extract prosodic and voice quality features per sentence window.
Prosodic features:
- Fundamental frequency mean and variance: \( \mu_{F_0} \), \( \sigma_{F_0} \)
- Speech rate (words per minute) from Whisper word timestamps
- Pause rate and mean duration for silences \( > 150\text{ms} \)
- Articulation ratio: \( r = \dfrac{\sum_i (t_{\text{end},i} - t_{\text{start},i})}{T_{\text{total}}} \)
Voice quality features:
- Jitter: cycle-to-cycle pitch period variation (normal \( < 1\% \); elevated under stress)
- Shimmer: cycle-to-cycle amplitude variation (normal \( < 3\%\) )
- Harmonics-to-noise ratio: \( \text{HNR} > 20\,\text{dB} \) indicates clean, confident vocal production
Stage 5. Self-Corrective Proposition Verification
A background task periodically scans for new and unverified propositional statements and execute the agentic LLM verification loop. The LLM is provided with video context, web search and multi-turn tool use for the verification of the statement. If the statement can only be verified in the future, the LLM estimates the best timestamp for its re-verification.
Challenges we ran into
Proposition verification is noisy. Not every executive claim has a clean, verifiable outcome. Some statements are intentionally vague ("we're optimistic about the macro environment"); others depend on external factors beyond the company's control. We built a confidence filter that only includes propositions the LLM can verify with high certainty, discarding ambiguous cases rather than mislabeling them.
Baseline establishment is harder than it sounds. Originally, we did surgical gradient boost on less than ten selected audio/video samples for the composite score weights. However, it fails to generalize to a broader dataset with ~4000 hours recording. We added an uncertainty aware Bayesian Average self-improvement process to the parameters as a solution.
Context window. Corporate recordings tend to be over 3 hours long. This poses a significant challenge to the LLM/VLMs which has a rather limited context window. We mitigated this issue by off-loading the tokens to tool calling and RAG.
Accomplishments that we're proud of
The learning architecture. Most behavioral analysis tools apply fixed rules. Veritais learns what truthful behavior looks like from a labeled dataset of verified statements. The feedback loop — extract proposition, verify outcome, learn signal — is the core innovation we're most proud of.
Topic-aligned scoring. Rather than producing one aggregate score per video, Veritais aligns conviction scores to specific statements. A CEO who scores 0.82 on revenue guidance but 0.41 on product development is telling a very different story than either number alone would suggest.
The leaderboard and Truth Index visualization. Turning a complex multimodal ML pipeline into something a non-technical user can understand in ten seconds — a ranked list of CEO truthfulness scores with historical trend lines — required significant design thinking. We're proud that the output is genuinely interpretable.
End-to-end on public data. Veritais uses no proprietary data. Every video analyzed is publicly available. The accountability tools that sophisticated analysts use informally should be available to every retail investor and journalist.
What we learned
The quality of the label matters more than the quality of the model. The proposition verification step — determining ground truth for each executive statement — is the most consequential part of the pipeline. A noisy label set produces a useless classifier regardless of how sophisticated the feature extraction is.
Within-person normalization is non-negotiable. Early experiments using universal behavioral thresholds were dominated by individual baseline differences — naturally soft-spoken people scored as low confidence regardless of what they were saying. Baseline-relative scoring transformed noise into meaningful signal.
The Q&A section is where the real signal lives. Prepared remarks are wordsmithed by legal teams. Q&A is live and unscripted. The delta between a speaker's behavioral profile in prepared remarks versus Q&A is consistently more informative than either in isolation — and it's the Q&A where consequential false statements most often emerge.
Multimodal fusion is harder than multimodal collection. Getting good facial scores is one problem. Getting good audio scores is another. Making them meaningfully combine — especially when one modality is degraded by poor recording quality — required careful fallback logic and weight calibration we hadn't anticipated needing.
What's next for Veritais
Larger verified statement dataset. The model improves directly as more labeled proposition-outcome pairs accumulate. Historical financial scandals — Enron, WorldCom, Theranos, Terra/LUNA — provide rich datasets of statements that were definitively false, which we're in the process of labeling and ingesting. Side-channels, such as stock performance and public reaction, can also provide another dimension to reflect the performance of the model.
Real-time inference during live appearances. Fed press conferences and earnings calls happen live. Building a streaming version of Veritais that produces conviction scores in near-real-time — updated every 30 seconds during a live appearance — is the version with genuine time-sensitive value for investors and journalists.
Expanded coverage beyond CEOs. The same framework applies to Fed officials, Treasury secretaries, SEC chairs, and congressional witnesses. Each speaker category has different behavioral baselines and different types of verifiable statements. Expanding coverage multiplies both the training data and the product's utility.
Longitudinal tracking. The most valuable analysis isn't a single appearance — it's the same executive across dozens of appearances over years. Watching how a CEO's behavioral profile on a specific topic evolves as a company's fortunes change is the kind of signal that early Enron investors wish they'd had.
The vision is straightforward: every public statement by every major executive, analyzed, verified, and tracked over time. Not to catch liars after the fact. To surface the signal before the next Enron.
Built With
- bun
- fastapi
- librosa
- next.js
- praat
- py-feat
- python
- scikit-learn
- scipy
- typescript





Log in or sign up for Devpost to join the conversation.