




🔍 Inspiration
Verita was born from a problem we couldn’t ignore: hiring fraud. With over $2 trillion lost annually to fraudulent resumes, scripted interviews, and AI-generated responses, we asked ourselves—how do we make interviews authentic again?
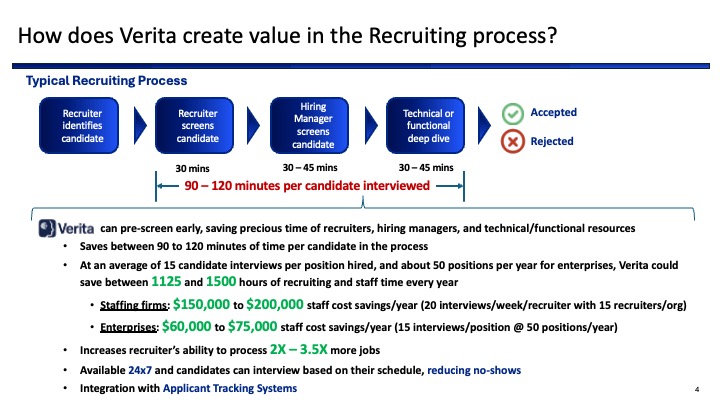
We also realized that genuine candidates often get overlooked because recruiters don’t have the time or tools to evaluate communication, originality, or confidence holistically.
So we built Verita: The first autonomous AI interviewer built to evaluate skills and uncover truth.
🧠 What It Does
Verita is a fully autonomous, AI-powered interview platform that:
- Generates tailored questions from the resume and job description
- Conducts structured, voice-based interviews
- Transcribes responses in real-time
- Captures and analyzes video, audio, and behavioral data
- Scores candidates on:
- Authenticity
- Confidence & Soft Skills
- Content Relevance
- Overall Communication
It then generates a recruiter-ready dashboard, including:
- Full transcript
- Video and audio playback
- Red flags and breakdowns
- PDF summary report
- Role fit suggestion
🧪 How We Built It
Verita is built as a modular multi-modal pipeline, with components for voice, video, behavior, and interview logic.
🔧 Core Tech Stack
- Python / FastAPI – modular backend orchestration
- Bolt.new – lightweight, beautiful, and interactive frontend
- Whisper (Faster-Whisper) – speech-to-text
- ElevenLabs – natural, human-like TTS
- MediaPipe – for gaze tracking, face detection, and emotion signals
- SendGrid – email notifications for candidates and recruiters
- OpenCV + Pydub – video/audio signal processing
- FFmpeg – audio extraction and conversion from video
- File-based JSON storage – to manage sessions without external DBs
📊 Detection & Scoring Features
We engineered over 30 distinct analysis signals, including:
- Repeat-back detection – flags when an answer mirrors the question
- Pause analysis – tracks hesitation before speaking
- Gaze direction – detects reading behavior via eye movement
- Off-screen detection – checks for consistent video presence
- Tab activity monitoring – flags multitasking or window switching
- Energy score – based on voice amplitude and RMS levels
- Pitch variation – assesses voice modulation across responses
- Speech clarity – detects filler words and hesitation frequency
- Confidence score – combines pace, pitch, and consistency
- Content quality – measured by length, relevance, and specificity
- Resume consistency – checks if answers align with submitted resume
- Role fit – suggestion based on interview patterns and job description
🧩 Output
- Authenticity Confidence Score (0–100)
- Letter Grade (A–F)
- Transcript + Audio/Video Playback
- Red Flag Overlay & Timeline
- Recruiter PDF Summary Report
- Role Fit Suggestion
🚧 Challenges We Faced
- ⚠️ Getting real-time transcription to work smoothly with long answers
- ⚠️ Building gaze tracking that worked reliably across lighting conditions
- ⚠️ Tuning behavioral heuristics to avoid false positives
- ⚠️ Aligning audio, video, and transcript data with frame-level accuracy
- ⚠️ Designing a scoring system that felt fair, interpretable, and robust
💡 What We Learned
- Multimodal interviews unlock deeper behavioral signals than text alone
- Subtle indicators like pause patterns, eye shifts, or voice energy carry significant insight
- Real-world hiring needs systems that are not just accurate—but explainable
- Designing for trust and transparency is just as important as engineering performance
Built With
- bolt.new
- elevenlabs
- fastapi
- mediapipe
- openai
- python
- whisper


Log in or sign up for Devpost to join the conversation.