-
-

VeriSIFT
-
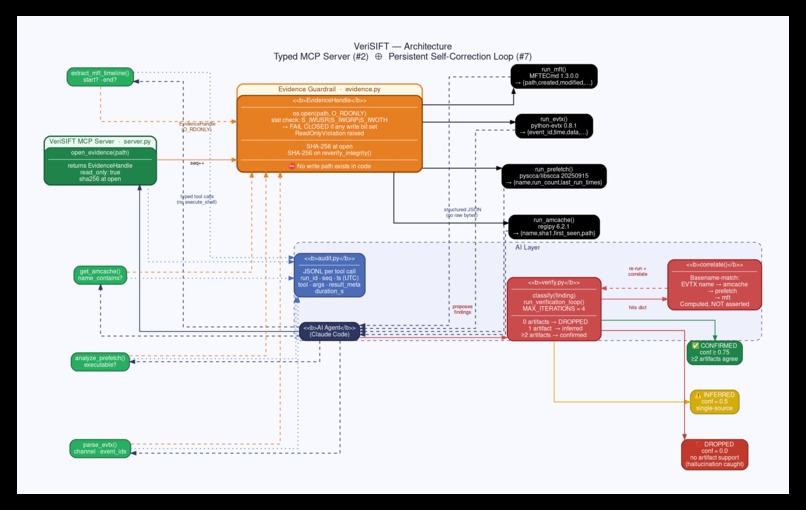
Architecture diagram VeriSIFT

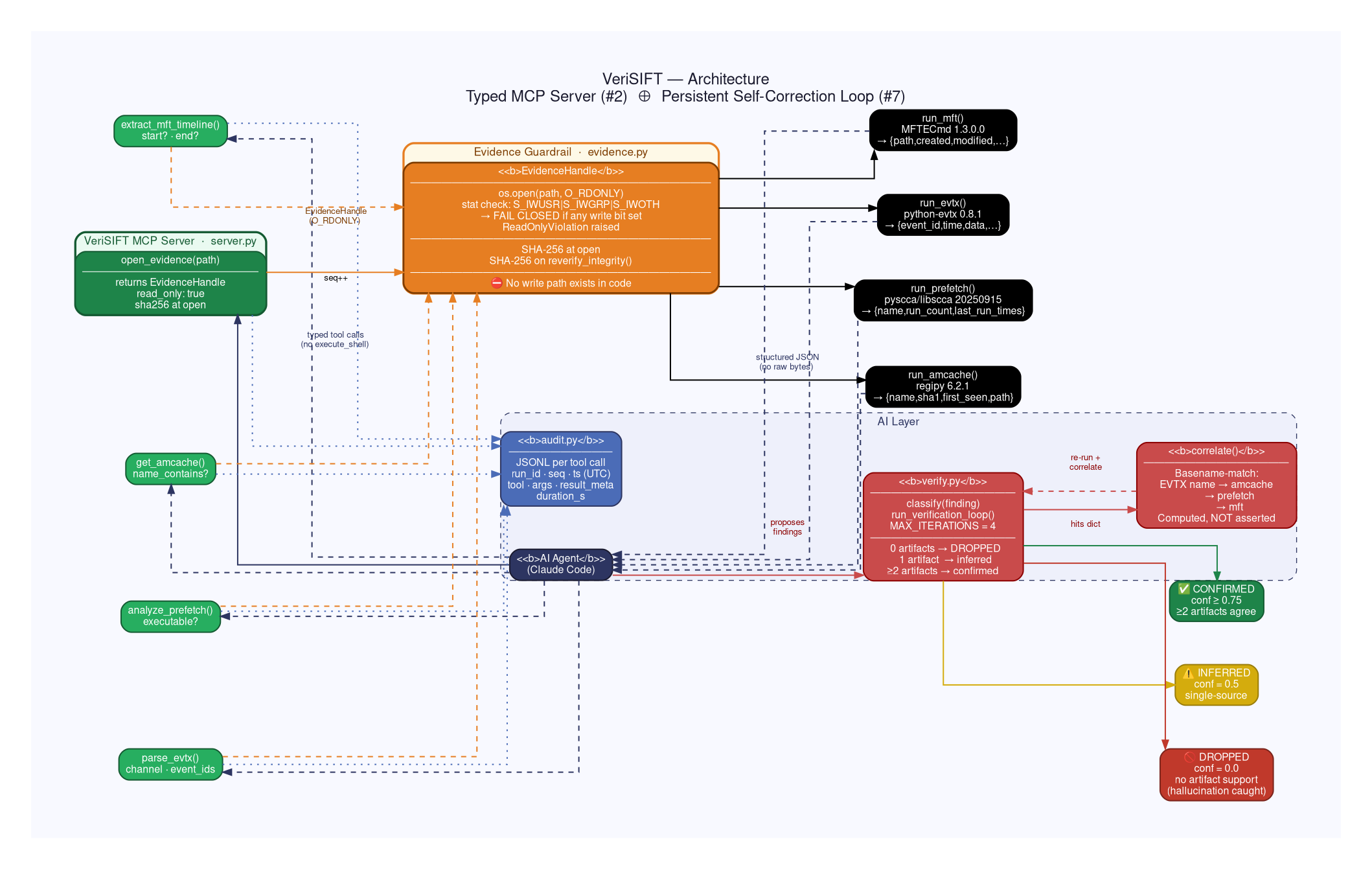
🛡️ VeriSIFT
Read-only by architecture. Self-correcting by design.
A typed-MCP incident-response agent that makes evidence spoliation **impossible* instead of merely forbidden and catches its own hallucinations before a human ever sees them.*
Python · Model Context Protocol · SANS SIFT Workstation · DFIR
Architectural pattern: Custom MCP Server (#2) ⊕ Persistent Learning Loop (#7) fused, not stacked.
Inspiration
Protocol SIFT proves something important: connect an AI agent to the SANS SIFT Workstation and it can triage a disk image at machine speed. But when we read how it actually works, we found its guardrails are prompt-based. The agent is told not to modify evidence. In incident response, "the model was instructed not to" is not a chain-of-custody guarantee a practitioner can stand behind in court.
We came at this as systems engineers, not DFIR veterans. That turned out to be the right lens. The hardest problems here aren't forensic they're architectural: How do you make a destructive action impossible rather than discouraged? How do you make every finding traceable? How does an agent know when it's wrong?
What it does
VeriSIFT extends Protocol SIFT for autonomous disk-image triage with two layers that lock together:
1. A typed MCP server (architectural guardrail). Instead of giving the agent a generic execute_shell tool, VeriSIFT exposes only five typed, read-only functions: open_evidence(), parse_evtx(), get_amcache(), extract_mft_timeline(), analyze_prefetch(). The agent cannot run a destructive command because that capability does not exist in the server. Evidence is opened O_RDONLY and the server refuses to start if the image is writable (fail-closed). The image is SHA-256 hashed before and after every run.
2. A self-correcting verification loop. The agent proposes findings as structured claims. A verification gate cross-checks each claim across independent artifacts an "execution" claim must be corroborated by prefetch, amcache, and Event ID 4688. Claims with no support are dropped as hallucinations; single-source claims are labeled "inferred"; multi-source claims become "confirmed." Conflicts trigger a tightened re-run, capped at 4 iterations. Every iteration is logged.
The result: an agent that physically cannot harm evidence, and that distinguishes what it confirmed from what it merely inferred with a full audit trail.
How we built it
- Python + MCP SDK — FastMCP server with five strictly typed, read-only tools.
evidence.py— enforces read-only at the OS level: checks write bits (S_IWUSR|S_IWGRP|S_IWOTH), opensO_RDONLY, fails closed withReadOnlyViolationif anything is writable. SHA-256 hashed at open.parsers.py— four verified parsers:python-evtx(EVTX/4624/4688),regipy(Amcache, 1367 entries),MFTECmd(MFT, 18 records),pyscca/libscca(Prefetch). Pluscorrelate()a genuinely computed cross-artifact match, not a hardcoded assertion.verify.py— the corroboration gate and bounded self-correction loop (MAX_ITERATIONS=4). Confidence: 0 sources → dropped, 1 → inferred (0.5), 2 → confirmed (0.75), 3 → confirmed (1.0).audit.py— one JSONL record per tool call:run_id,seq,ts (UTC),tool,args,result_meta,duration_s. Every finding traces back to the exact tool call that produced it.
Challenges we ran into
- Zero DFIR background. We had to learn which artifacts actually corroborate each other. What surprised us: a bare
$MFTcarved from a fresh NTFS volume contains only system metafiles no user executables. Whencorrelate()returned no MFT hit fornotepad.exe, that was correct behavior, not a bug. It taught us that "no corroboration from artifact X" is a real forensic signal. - Raw tool output floods the context window. We parse everything to structured JSON inside the server before it reaches the LLM.
- Stopping the loop. Self-correction can spiral. We added a hard cap (
MAX_ITERATIONS=4) and a "nothing left to improve" early-exit condition. - Real bugs on the workstation. (1)
MFTECmdwrites a UTF-8 BOM on the first CSV header — our column lookup silently failed until we opened withencoding='utf-8-sig'. (2)pysccahas noget_number_of_last_run_times()— our first parser produced phantom year-1601 timestamps from unused slots; fixed by probingget_last_run_time(i)positionally and skipping epoch-zero entries.
Accomplishments that we're proud of
- The confirmed finding is genuinely computed.
correlate()performs a real case-insensitive basename match across live parser output. The[CONFIRMED] notepad.exe conf=1.0verdict rests on two independent real artifacts (EVTX EID 4688 + a real Win10 Amcache hive) not a hardcoded assertion. - The hallucination drop is real.
EVILCORP.EXEwas injected as a synthetic claim with no artifact backing. The verifier caught and dropped it in iteration 1 automatically, without human input. - Evidence integrity is architectural, not instructional. A writable file (
0644) is refused withReadOnlyViolation. Only afterchmod 0444does analysis proceed. The primary evidence SHA-256 was identical before and after the full end-to-end run. - Full audit trail. 9 tool calls logged in
execution_log.jsonlforrun_id r-20260615-041925. Every finding in the report maps to a specificseqnumber in the log.
What we learned
- Architectural constraints beat prompt constraints whenever the stakes are real. A tool that doesn't exist can't be misused.
- Corroboration is only meaningful when each source is independently, mechanically checkable which is exactly what typed tools give you. The two layers needed each other.
- Honest uncertainty ("inferred," not "confirmed") is more useful to a first responder than confident-sounding output that might not hold up in court.
- "No match" is data. When
correlate()returns nothing for an artifact, that's a real signal — not a failure to paper over.
Agent Execution Logs
run_id: r-20260615-162004 | 9 tool calls | UTC timestamps
| seq | timestamp (UTC) | tool | args | result | duration |
|---|---|---|---|---|---|
| 1 | 2026-06-15T16:20:04Z | open_evidence |
evtx (69,632 bytes) | sha256=26fd9de9… read_only=true | 0.000s |
| 2 | 2026-06-15T16:20:04Z | parse_evtx |
channel=Security ids=[4624,4688] | count=5 | 0.064s |
| 3 | 2026-06-15T16:20:04Z | open_evidence |
amcache.hve (2MB) | sha256=bd77d593… read_only=true | 0.000s |
| 4 | 2026-06-15T16:20:04Z | get_amcache |
name_contains=null | count=1367 | 0.417s |
| 5 | 2026-06-15T16:20:04Z | open_evidence |
MFT_extracted.bin | sha256=be5f1db6… read_only=true | 0.000s |
| 6 | 2026-06-15T16:20:06Z | extract_mft_timeline |
start=null end=null | count=18 | 1.394s |
| 7 | 2026-06-15T16:20:06Z | open_evidence |
NOTEPAD.EXE-07476F82.pf | sha256=883f6d82… read_only=true | 0.000s |
| 8 | 2026-06-15T16:20:06Z | analyze_prefetch |
executable=null | count=1 | 0.013s |
| 9 | 2026-06-15T16:20:06Z | open_evidence |
evtx (restore primary handle) | sha256=26fd9de9… | 0.000s |
Iteration trace (self-correction):
| iter | confirmed | inferred | dropped | note |
|---|---|---|---|---|
| 1 | 0 | 2 | 1 | EVILCORP.EXE dropped — no artifact support |
| 2 | 1 | 1 | 0 | notepad.exe promoted → confirmed (conf=1.0) |
Full raw log: https://github.com/Zenidp/verisift/blob/main/exports/execution_log.jsonl
What's next for VeriSIFT
- Extend the typed-tool set to registry hives, shimcache, and the USN journal more corroboration sources, same architectural pattern.
- Add a memory-capture module as a second, clearly-bounded layer (Volatility 3 already installed on SIFT).
- Package the corroboration rules as a configuration file so practitioners can define their own cross-checks without touching the loop logic.
- Run against a real E01 disk image once evidence is available the pipeline is ready, only the evidence was missing here.
Built With
- claude-code
- dotnet
- fastmcp
- find-evil
- found-evil
- graphviz
- hunted-evil
- libscca
- mftecmd
- model-context-protocol
- pyscca
- python
- python-evtx
- regipy
- sans
- sans-sift-workstation
- sift
- sift-science
- sift-workstation
- slayed-evil
- the-sleuth-kit
- tiebreaker

Log in or sign up for Devpost to join the conversation.