-
-

The start menu of our tool offers users two options: text duplication detection and image duplication detection.
-
Our landing page for text duplication detection, enabling users to easily identify plagiarism within any article.
-
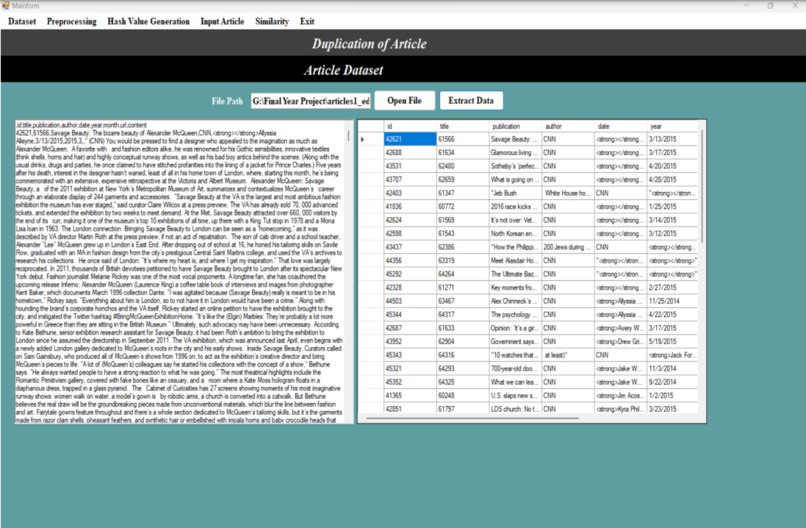
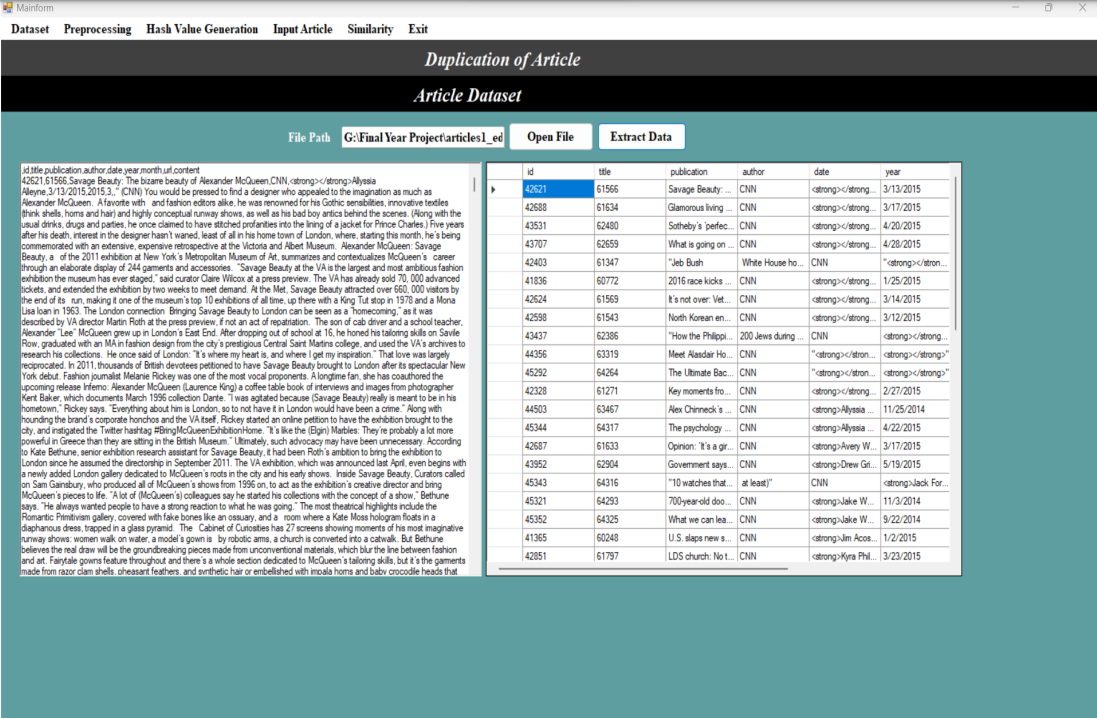
In the ”Import Dataset” window, users can import various types of datasets, including news, educational and organizational data.
-
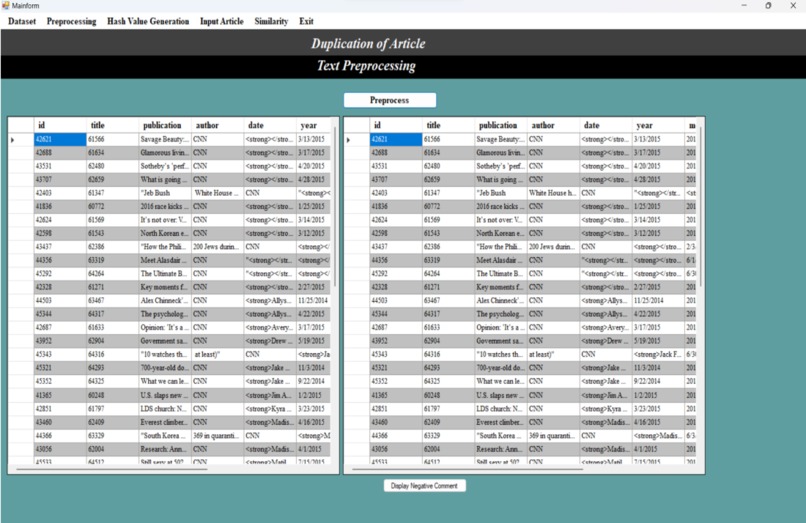
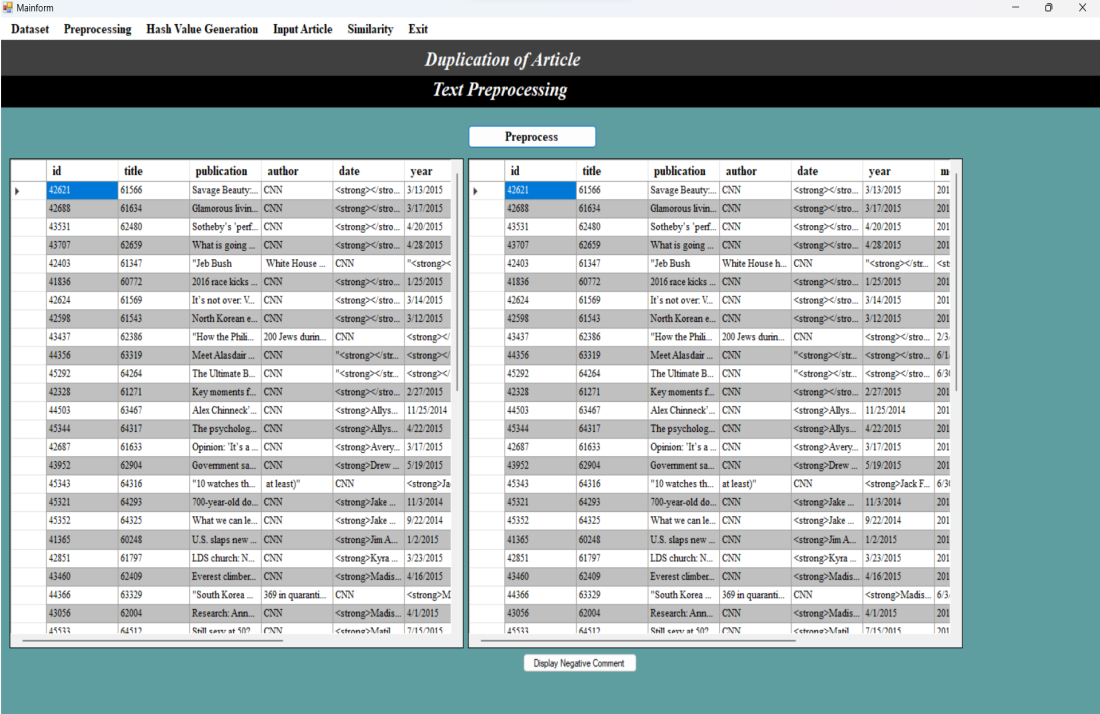
During the preprocessing phase in the ”Preprocessing” window, the imported CSV file undergoes a series of text preprocessing algorithms.
-
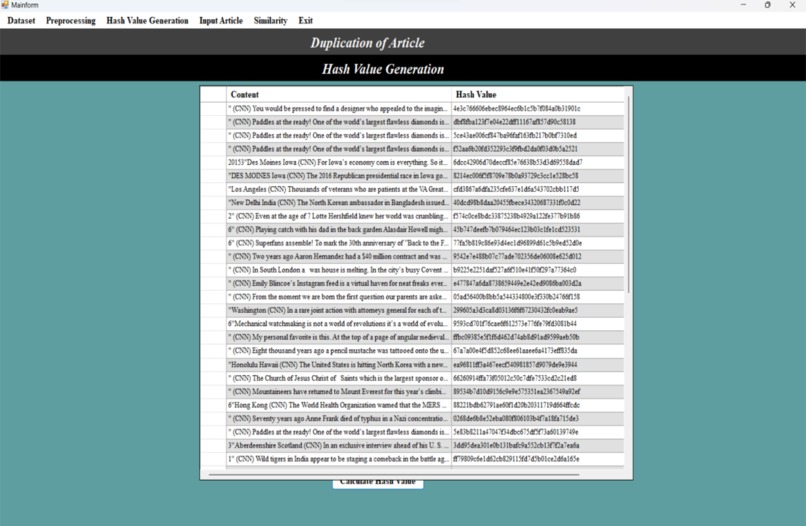
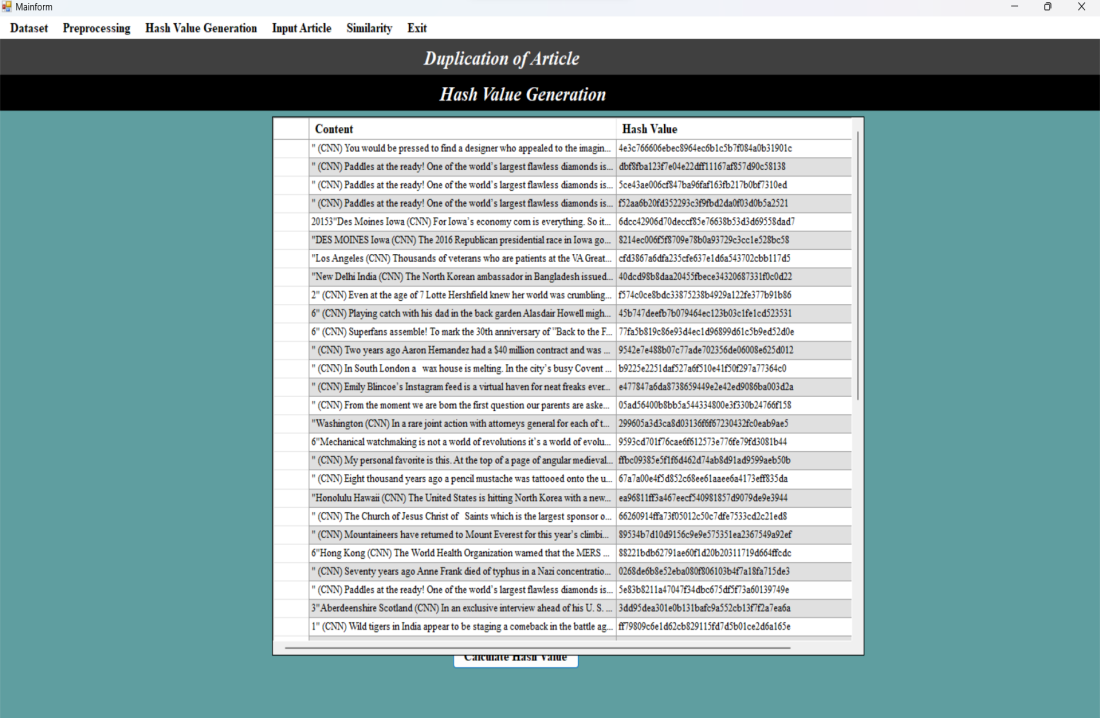
In the ”Hash Value Generation” window, the hash values of the preprocessed articles are generated using the Jaccard similarity algorithm.
-
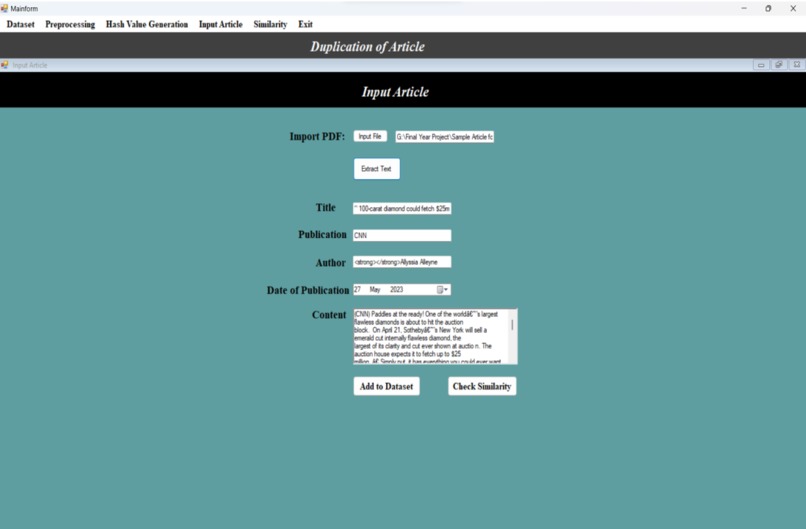
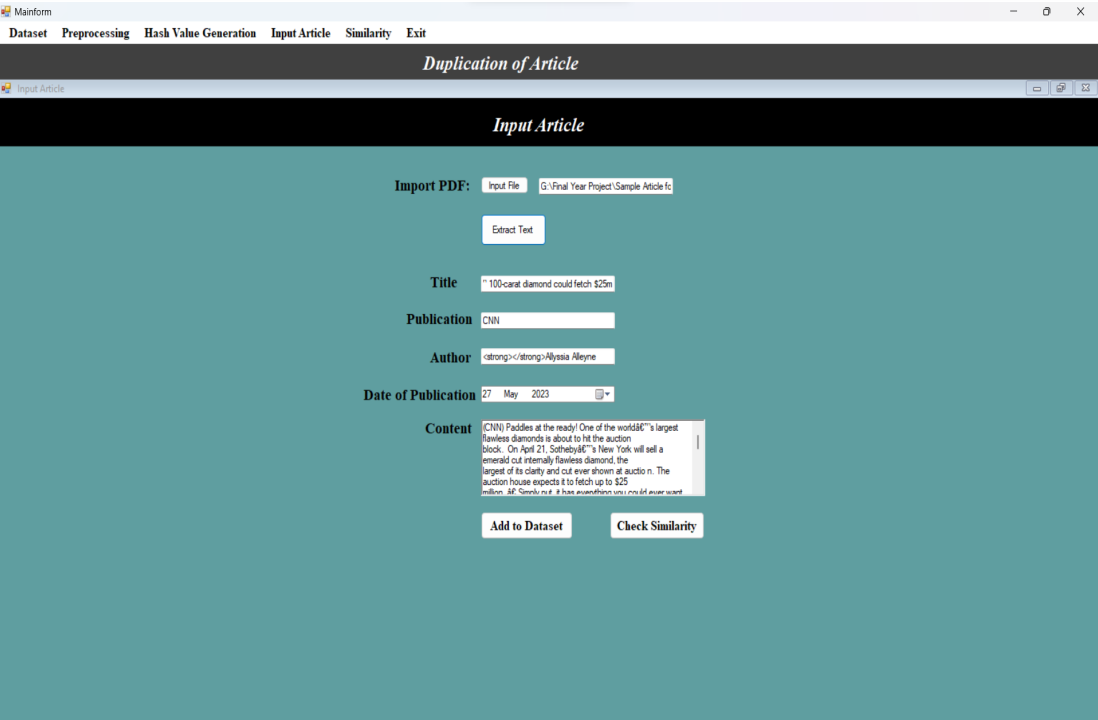
In the ”Input Article” window, users have the option to upload their article in PDF format.
-
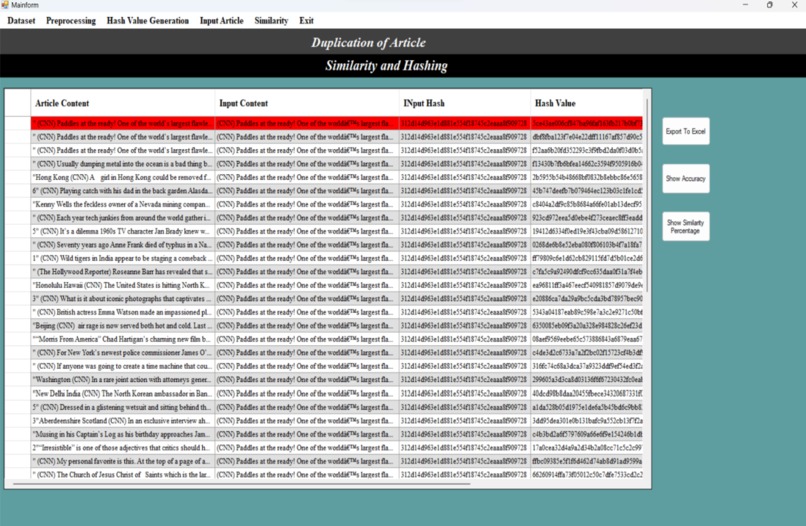
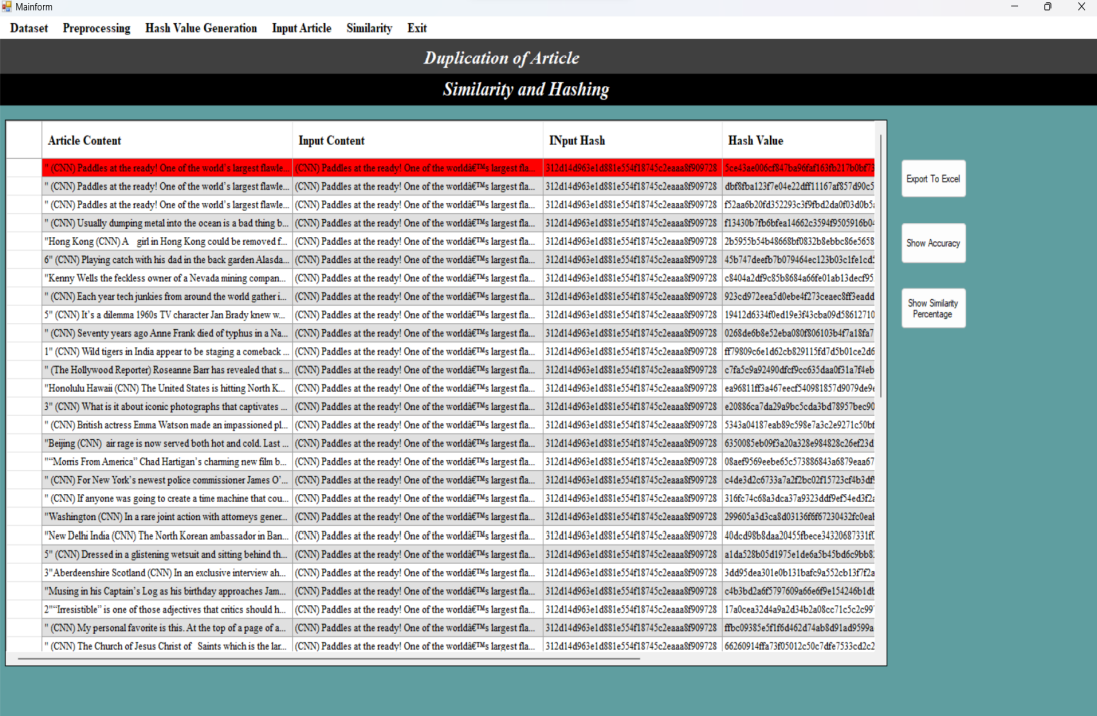
The window displays the similar articles that have been identified in comparison to the input article provided by the user.
-

A comprehensive report is generated, presenting the results in the form of a confusion matrix and a bar graph.
-
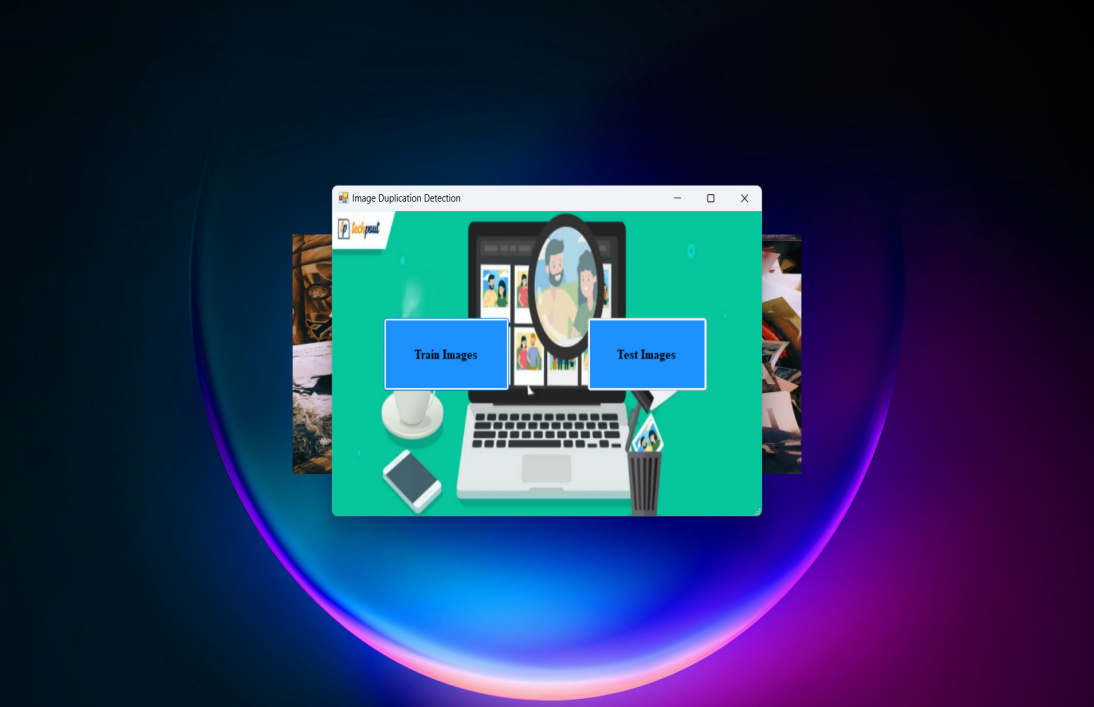
The menu of the image duplication detection module is displayed.
-
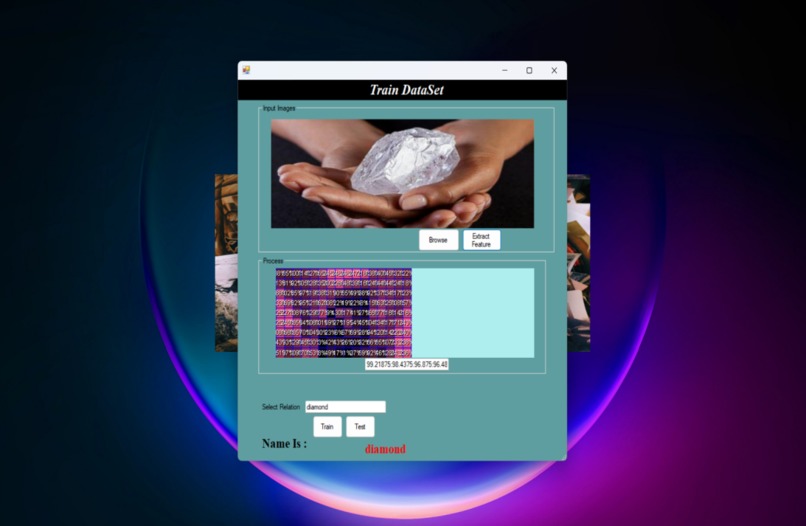
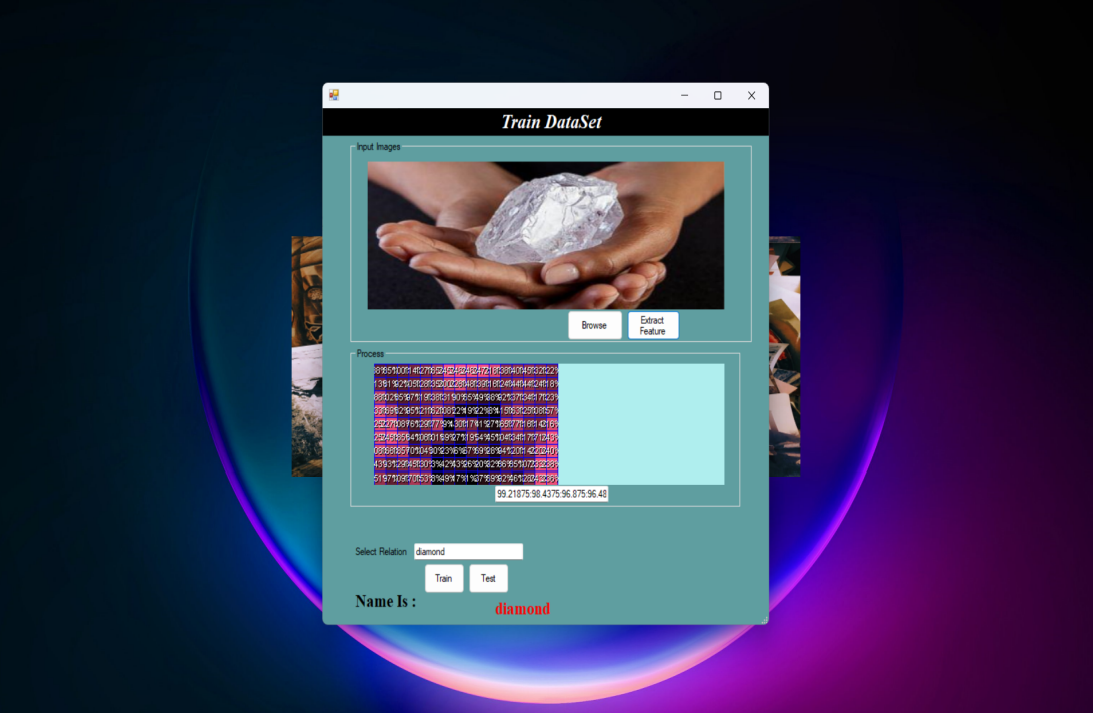
In the ”Training” window of the image duplication detection module, users can upload images to train the system.
-
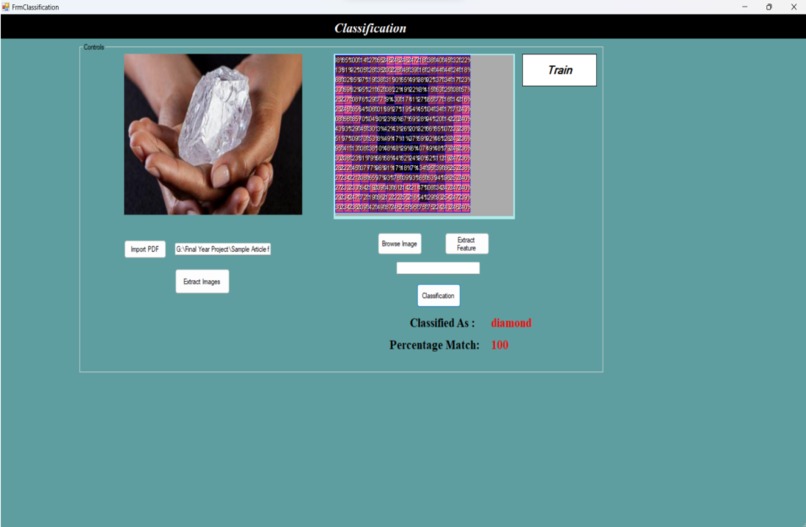
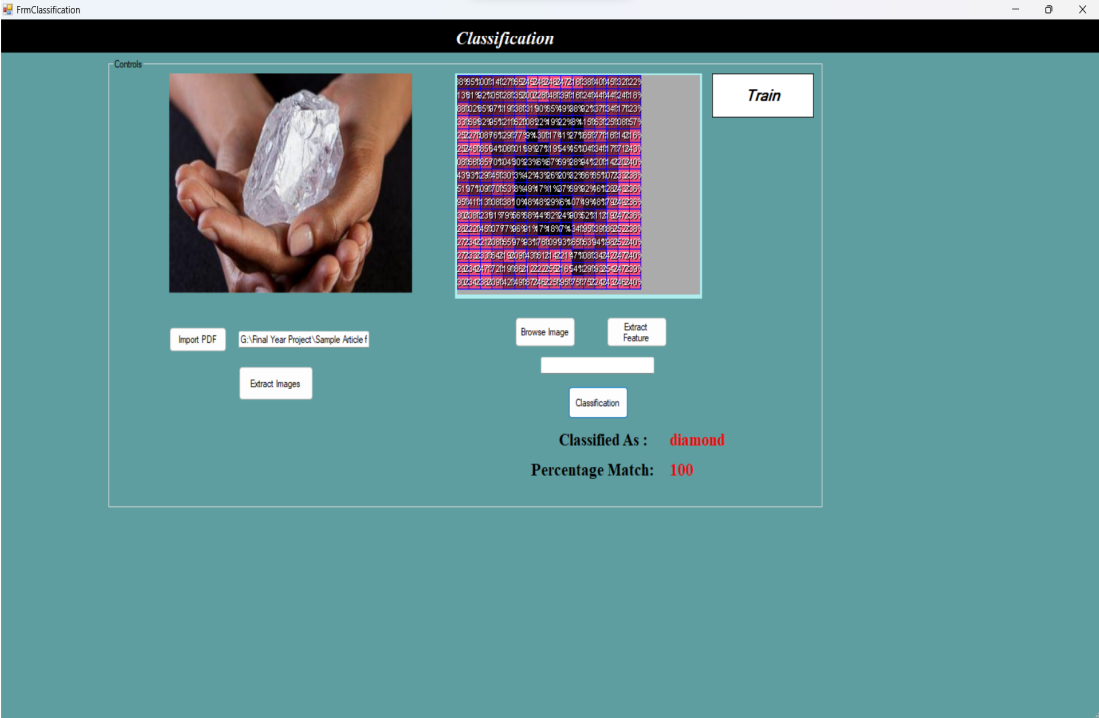
After the testing process is successfully completed, the tool generates results in the form of a percentage match.


Inspiration
Large-scale public opinion campaigns and internet portals that encourage people to customize content result in a lot of duplicate papers, which raises processing and storage costs but is rarely a severe issue. Duplicate papers are frequently found in media collections. While writers may make small changes to previous articles by adding new information or making minor corrections, editors often modify verified articles to suit print editions or include local context. These practices contribute to the presence of duplicated content within media collections. Since great precision is required for real-time applications, it is vital to eliminate nearly identical documents from collections. Nowadays, due to the rapid development of electronic media and the large number of articles created online, duplication detection is required. Additionally, there is a clear connection between plagiarism in article content and the duplication of articles. Newspaper articles have been the subject of most of the previous research on duplicate detection.
What it does
The proposed system will concentrate on finding duplicate articles. The fingerprinting approach and hash index are used in our suggested system to find duplicate articles. To validate our proposed approach, ‘Verifyr’ tool is meant to crawl huge number of articles data for detection. Moreover, it will apply our approach to detect plagiarism articles based on our duplication results in future. Further with the help of tool, it will try to conduct an empirical study and summarize a few of most used plagiarism patterns in plagiarism articles.
How we built it
We designed a hash-based algorithm to process each sentence in the article, which can be seen as a fingerprinting technique. In other words, each article is processed as a set of hash values, where each hash value represents a text sentence in the article. Furthermore, for pairs of obtained hash set (i.e., pairs of articles), Our proposed tool uses Jaccard similarity coefficient as similarity function to detect duplication. We used C# .NET to bulid the project.
Challenges we ran into
Previous studies on near-duplicate detection focused on assessing the similarity between two documents without relying on computationally demanding whole-document bit-wise comparisons. An approach commonly used involved hashing the documents and comparing their hash values to identify duplicate documents, where matching hash values indicated duplicates. However, this method is not suitable for identifying nearly identical documents as it does not provide information on the degree of similarity between two documents. To tackle this issue, most algorithms for near-duplicate identification utilize compact representations of documents. These representations are created and compared using various methods to accurately identify near-duplicates. By employing efficient techniques, these algorithms can effectively determine the similarity between documents and identify nearduplicate content. This approach allows for the detection of near duplicates without the need for computationally demanding comparisons of entire texts, providing a more practical and scalable solution
Accomplishments that we're proud of
To validate our proposed approach, we initially gathered a dataset of articles by crawling various sources. Subsequently, we evaluated our tool's effectiveness by utilizing it to detect data duplication within the collected articles. This approach allowed us to assess the tool's capabilities and determine its accuracy in identifying duplicated content. By applying our proposed approach to the collected dataset, we were able to demonstrate the effectiveness of our tool and provide insights into its performance. Overall, the evaluation process was crucial in validating our proposed approach and demonstrating its ability to detect data duplication effectively. Based on our collected data, a total number of 50,103 Articles, our approach can accurately detect duplicate articles with the precision of 98%.
What we learned
We learned various approaches of solving the problem, various fields of software development and testing. We were exposed to the most recent technologies and then our ability was tested towards that approach.
What's next for VerifyR
We offer our approach as an article, image and plagiarism detector, which is useful for duplication management and plagiarism prevention of articles. For our future work, we plan to extend our study by collecting a larger dataset of articles from multiple sources. This will enable us to investigate the issue of cross-platform duplication and plagiarism detection, which involves identifying instances of plagiarism across different publishing platforms.



Log in or sign up for Devpost to join the conversation.